「代码审查不是为了证明你是对的,而是为了证明代码没有错。」
在传统的软件工程中,代码审查(Code Review)往往是最容易被忽视却又最关键的环节。开发者忙于交付功能,审查者碍于情面不愿直言,最终让带着缺陷的代码溜进生产环境。
今天,我要介绍一个颠覆性的 AI 代码审查工作流——它不懂得「客气」,只懂得「找茬」。
一、什么是「对抗式」代码审查?
这个工作流的核心哲学很简单:**NEVER accepts "looks good"**(永远不要接受「看起来不错」)。
它被设计成一个持有批判立场的高级开发者,必须在每次审查中找出 3-10 个具体问题。这不是为了刁难,而是为了确保:
- ✅ 任务标记为
[x] 的真的是完成了
- ✅ 验收标准真的是实现了,不是糊弄
- ✅ 代码质量经得起安全、性能、可维护性考验
description: "Perform an ADVERSARIAL Senior Developer code review
that finds 3-10 specific problems in every story. Challenges everything:
code quality, test coverage, architecture compliance, security, performance.
NEVER accepts `looks good`"
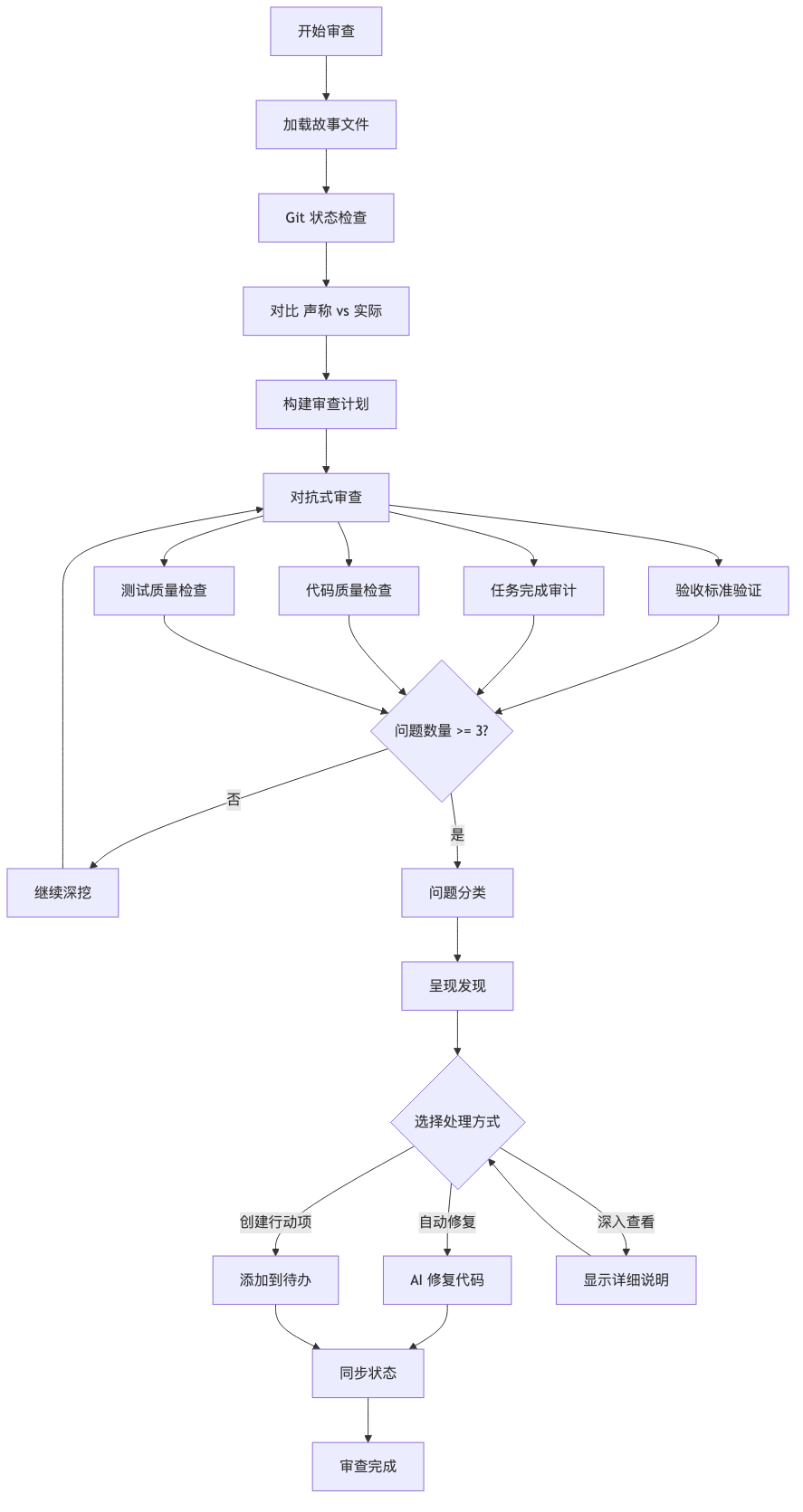
二、工作流全流程解析
步骤 1:加载故事 + 发现真相
审查的第一步是「对账」——对比开发者声称改了什么和 Git 仓库实际改了什么。
git status --porcelain # 找未提交的改动
git diff --name-only # 看修改了哪些文件
git diff --cached --name-only # 看暂存区的文件
发现真相的三个维度:
- Git 有改动,但故事文件里没记录 → 文档不完整
- 故事声称改了文件,但 Git 没痕迹 → 虚假声明
- 有未提交改动没追踪 → 透明度问题
步骤 2:构建「攻击计划」
系统会自动提取:
- 所有验收标准(Acceptance Criteria)
- 所有任务及其完成状态
- 开发者记录的文件列表
然后制定审查计划:
- AC 验证:每个验收标准真的实现了吗?
- 任务审计:每个打钩的任务真的完成了吗?
- 代码质量:安全、性能、可维护性
- 测试质量:是真测试还是占位符?
步骤 3:执行对抗式审查
这是最核心的环节。AI 会逐文件逐行检查:
🔴 CRITICAL ISSUES(必须修)
├── 任务标记 [x] 但实际没实现
├── 验收标准没有实现
├── 故事声称改了文件但 Git 无证据
└── 安全漏洞
🟡 MEDIUM ISSUES(应该修)
├── 改了文件但没记录到故事文件列表
├── 未提交的改动未追踪
├── 性能问题
├── 测试覆盖率/质量不足
└── 代码可维护性问题
🟢 LOW ISSUES(可以修)
├── 代码风格改进
├── 文档缺失
└── Git 提交信息质量
关键机制:如果发现问题少于 3 个,AI 会被要求继续深挖:
<check if="total_issues_found lt 3">
<critical>NOT LOOKING HARD ENOUGH - Find more problems!</critical>
<!-- 重新检查边界情况、架构违规、集成问题... -->
</check>
步骤 4:呈现发现 + 自动修复
审查结果呈现后,开发者有三种选择:
| 选项 |
行动 |
| 1️⃣ 自动修复 |
AI 直接修改代码和测试 |
| 2️⃣ 创建行动项 |
将问题加入故事的待办任务 |
| 3️⃣ 深入查看 |
显示问题的详细解释和代码示例 |
步骤 5:状态同步
最后,系统会自动:
- 更新故事状态(done / in-progress)
- 同步到
sprint-status.yaml
- 记录审查历史到 Change Log
三、与传统 Code Review 的对比
| 维度 |
传统 Code Review |
AI 对抗式审查 |
| 态度 |
礼貌、顾忌 |
直接、不留情面 |
| 覆盖度 |
随机抽查 |
100% 覆盖 |
| 速度 |
依赖人工时间 |
即时反馈 |
| 一致性 |
审查者水平波动 |
标准统一 |
| 可追溯 |
口头讨论或零散记录 |
结构化问题列表 |
四、实战案例示例
假设开发者提交了一个「用户认证」功能:
开发者声称:
[x] 实现登录 API
[x] 添加 JWT 验证
[x] 编写单元测试
AI 对抗式审查发现:
🔴 CRITICAL: 任务标记 [x] 但未实现
├── src/auth/login.ts:45 - JWT 密钥硬编码,应从环境变量读取
└── tests/auth.test.js - 所有测试都使用 t.skip() 跳过
🟡 MEDIUM: 性能问题
└── src/auth/login.ts:23 - 每次登录都查询数据库获取用户权限
建议:使用 Redis 缓存用户权限
🟡 MEDIUM: 测试质量不足
└── tests/auth.test.js - 缺少错误场景测试(密码错误、用户不存在)
结果?开发者必须修复这些问题才能标记为「完成」。
五、真实对话记录
想看看 AI 对抗式代码审查的真实运行过程吗?
完整对话记录:https://autoqa-chats.lovable.app/chat/27
在这个真实对话中,你可以看到 AI 如何:
- 逐个检查验收标准的实现情况
- 发现被标记为「完成」但实际上未完成的任务
- 指出代码中的安全和性能问题
- 要求开发者修复后才通过审查
六、工作流架构图
七、如何集成到你的项目?
这个工作流是 BMAD v6 框架的一部分。基本集成步骤:
- 安装 BMAD v6: npx bmad-method@alpha install
- 实现故事:
/dev-story
- 触发审查:
/code-review
八、总结:为什么「找茬」很重要?
代码审查的本质是质量门禁。在 AI 辅助开发时代,我们不再需要人类做机械性的代码扫描,但我们需要一个永不妥协的质量守门员。
这个 AI 代码审查工作流的独特价值在于:
- ✅ 不讲人情:只认代码,不认关系
- ✅ 事必躬亲:逐文件验证,不遗漏
- ✅ 知识驱动:结合架构文档、项目上下文综合判断
- ✅ 可自愈:发现问题时可以自动修复
正如工作流文档所说:
"YOU are so much better than the dev agent that wrote this slop"
这种「对抗」不是对抗开发者,而是对抗缺陷、对抗技术债务、对抗生产环境的故障。
📚 延伸阅读