推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 2378 天前的主题,其中的信息可能已经有所发展或是发生改变。
如题
主要问题:千万级别处理起来会不会崩溃?
主要是去重
谢谢
 |
1
jdhao 2019 年 7 月 15 日 via Android
自己做一个然后试一下不就知道了
|
 |
2
yedanten 2019 年 7 月 15 日 via Android
得看业务情况啊,不知道你后续的处理是要做哪些操作,否则只是去重,最简单粗暴的转换为 set 就完事了
|
 |
3
momo1999 2019 年 7 月 15 日
推荐用 64 位 Python,加内存就是了。
|
 |
4
lithiumii 2019 年 7 月 15 日
list(set(li)
崩溃了就是你电脑不行!(滑稽 |
 |
5
Takamine 2019 年 7 月 15 日 既然都能打算一次性把 4000 个元素放到一个 list 里面操作,不如就直接再导入 Excel 去重:doge:。
|
 |
6
chengxiao 2019 年 7 月 15 日
这种建议直接上 MongoDB 然后设置索引唯一去重
|
 |
7
nutting 2019 年 7 月 15 日
内存里的操作怕啥,比数据库强多了,随便搞
|
 |
8
ipwx 2019 年 7 月 15 日
In [4]: N = 10**8
In [5]: arr = np.random.randint(0, N, size=N) In [6]: len(arr) Out[6]: 100000000 In [7]: %timeit set(arr) 36 s ± 122 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) 给你一个时间作参考。。。 |
 |
9
ytmsdy 2019 年 7 月 15 日
先分段排序,然后去重。
|
 |
10
v2mo OP 几千万的数据,一台电脑运行,有可行性吗?
|

 |
12
Universe 2019 年 7 月 15 日 via Android
看精度要求,不高的话布隆过滤器可以一试
|
 |
13
pcdRob 2019 年 7 月 15 日
几千万而已 洒洒水啦
|
 |
14
fuxiuyin 2019 年 7 月 15 日
首先,这 4 千万个元素肯定是要便利一遍的,除非你的数据有什么特殊的规律。
其次,要看这 4 千万存在哪,内存?文件?网络? 最后,如果没有优化空间不可避免的要对 4 千万数据过一遍那就看想优化内存还是想优化时间了,不过最快可能也就是楼上 8 楼给的。 |
 |
15
mengzhuo 2019 年 7 月 15 日
4 千万 uint32,最大也就 40M 搞定了…… O ( N )操作而已
|
 |
16
dji38838c 2019 年 7 月 15 日
这样都不肯用 pandas 吗?
|
 |
17
ruandao 2019 年 7 月 15 日
布隆过滤器
|
|
18
ruandao 2019 年 7 月 15 日
想了想, 好像不需要
千万,也就 MB 级别吧 |
 |
19
janxin 2019 年 7 月 15 日
数据都不说一下怎么分情况处理。
这种统一建议 list(set(data)) |
 |
21
misaka19000 2019 年 7 月 15 日
不是,你也说一下你每条数据多大啊,每条数据 1kb 和每条数据 10mb 当然不一样
|
 |
22
vincenttone 2019 年 7 月 15 日
既然 4 千万个元素能放进数组里,说明你内存就够用,去重就是了,就看算法对内存的使用和耗费的 cpu 时间了。
|
 |
23
flyingghost 2019 年 7 月 15 日
4kw 个 int,160M,可以直接放内存。
设计一个分布尽可能均匀的散列函数(这一步不太确定我不是搞数学的。瞎拍一个 md5(obj)//4kw 的算法不知道效果怎么样?) 遍历每个 obj 求 hash,把 obj 的 index 放在对应的桶里。 如果桶里已有元素( hash 冲突),单独放在另一个冲突列表里。 对于冲突列表里的每个冲突 hash,遍历并精确对比每个 obj,从源数据集删除完全相同的 obj。 稍微注意一下 getObj(index)的 O(1)复杂度,理论上可以应对任意量的数据了。 |
 |
24
princelai 2019 年 7 月 15 日
@ipwx #8 只替换最后一步
%timeit np.unique(arr) 11.4 s ± 401 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) |
 |
25
dyllanwli 2019 年 7 月 15 日
|
 |
26
scalaer 2019 年 7 月 15 日
看看 bitmap
|
 |
27
lihongjie0209 2019 年 7 月 15 日
@mggis0or1 bitmap 对于非数字型的元素无法支持, 还是用布隆过滤器吧
|
 |
28
reus 2019 年 7 月 15 日
你这水平,处理什么都会崩溃
自己不会试验吗 要问人,又不说清楚细节 |
 |
29
limuyan44 2019 年 7 月 15 日 via Android
讨论这么多写个代码就这么难吗也没几行啊
|
 |
30
NullErro 2019 年 7 月 15 日
想在内存跑的话,简单直接暴力的就是用 set, 推荐布隆过滤器;每个元素比较大的话可以考虑 mr,spark 或者其他分布式计算框架
|
 |
31
arrow8899 2019 年 7 月 15 日
首先你要清楚数据的特征啊 整形?浮点数?短字符串?超长字符串?数据分布?重复概率?这些都会影响去重的效率!!!
V2EX √ 动手实践 × |
 |
32
changs1986 2019 年 7 月 15 日
bloomfilter ?
|
 |
34
thedog 2019 年 7 月 15 日
bitmap+1
|
 |
35
shm7 2019 年 7 月 15 日 via iPhone
试试 numpy 吧,python list 遍历会检查类型,每次都会。
|
 |
36
Hamniba 2019 年 7 月 15 日
@flyingghost #23
你这个就是 Hash Table 的思想,getObj(index) 是 O(1),但是求一遍 hash 还是得 O(n) 啊。 |
 |
37
smdbh 2019 年 7 月 15 日
天天 4 千万,和每月,每年是有区别的。
但是,其实也没多大区别 |
 |
38
Gooeeu 2019 年 7 月 15 日
Bloom Filter
|
 |
39
sazima 2019 年 7 月 15 日
list(set(item))
|
|
40
sazima 2019 年 7 月 15 日
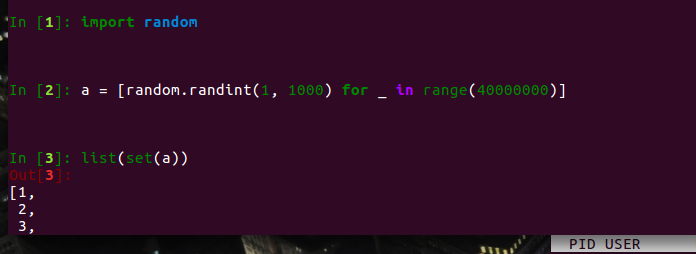 粗略的感觉,耗时不到一秒... 也可能不到 0.5.
|
|
41
sazima 2019 年 7 月 15 日
不好意思我的数太简单了 -__-
|
 |
42
skinny 2019 年 7 月 16 日
没有元素类型、数据大小信息,更没有电脑内存的信息,就直接问 Python 能不能,别人就只能瞎猜随便说了。
还有,千万不要用 C、C++、C#,甚至 Java 之类的语言的设计和使用经验来估计 Python 的内存用量,到时候如果楼主的电脑内存不够大,估计要死机。 |