
[求 Star] 如何评估一个 Github 项目的活跃度 —— Grank
xiqingongzi · bestony · 2018 年 10 月 22 日 · 2364 次点击这是一个创建于 2643 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文为 Grank (Github Rank) 的简介及相关思路的介绍,如果您对此文没有兴趣,可以直接关闭网页。
在深圳刚刚结束的 CosCon 2018 大会上发布了《中国开源调查报告》,Grank 作为其中数据篇的部分数据提供者,构建了一个 Github 项目活跃度、社区化的模型,并以 Python 实现。
项目地址: https://github.com/lctt/grank/
数据篇地址: https://mp.weixin.qq.com/s/pUjaSL6hvm2FARUWvOEs5w
Grank 模型
我们认为,一个健康的开源项目应该体现为以下两个方面:
- 项目的活跃度趋势
- 项目的社区化(去中心化)程度
而这两个方面分别有多个因素组成:
活跃度和活跃度趋势
项目的活跃度,我们定义为项目的提交数、 拉取请求数( Pull Request )和贡献者数(Contributors)(其它数据,如代码行数、文件数、issue 数、fork 数、star 数,要么是权重相对低得多,要么是代表意义不够确定,此处忽略不计入模型)。
但是,对于不同的项目,其横向比较其活跃度,或有不同的活跃度形态,或不具备可比性。很难说一个项目比另外一个项目的提交数高,而拉取请求( PR )数低代表的确切含义。因此我们不认为对不同项目的这些数据进行绝对值的比较有太多的科学意义。
所以,我们认为一个项目本身的活跃度变化的趋势和幅度,会更有项目间比较的意义。
社区化程度
我们认为需要有一个评估开源项目的社区化(去中心化)程度的指标。项目(尤其是软件项目)的一个重要属性是开发人员的社区化身份,因此,我们以实际向项目贡献了代码的人员的社区化离散程度来评估项目的社区化程度。
每个参与项目开发的人员均有其身份属性,这个身份可能是企业雇佣身份,也可能是社区志愿者身份。我们通过对项目的提交中的提交者数据进行收集,然后根据开发人员的身份信息、邮件后缀等依优先级来判断其所属身份。然后对这些信息进行聚类,以一个离散评估模型来评估该数据集的离散程度。
Grank 的结果长什么样子?
多项目活跃度
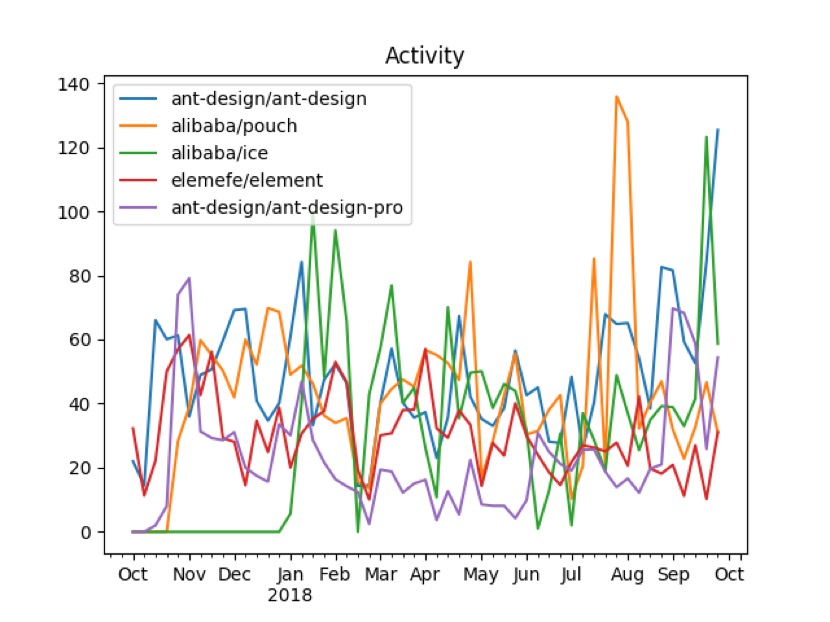
多项目社区化

单项目社区化及活跃度

使用方法
- 使用 pip 安装项目
pip install grank - 获取 Github 的 Personal Access Token
- 使用
grank login设置 Token - 使用
grank config设置社区化企业关键词 - 使用
grank analy <owner> [<repository>]来分析特定用户 /组织和项目,比如grank analy lctt grank,分析结果可以在执行命令目录的 result 目录中找到。 - 使用命令行模式操作,如
grank --token=XXXX --start=2018-01-01 --stop=2018-05-21 --askrule=0 --rule=inc analy <owner> <repository>其中 token 必须指定,其他可以使用缺省设置
Grank 是如何实现的?
Grank 使用 Github 的 GraphQL 来完成数据抓取的工作,抓取项目的所有 commit 和 pull Request 来进行分析,并使用 Pandas、numpy、pandas 进行数据的分析,最终得出结果。
此外,Grank 目前为 Command Line 工具,采用了 Click 来编写命令行的支持。
Grank 能够为你带来什么?
- 评估自己的项目情况
- 学习 Python 项目编写
- 了解 Click 的使用
- 了解 pytest 的使用。
项目地址:
Pypi 地址:
https://pypi.org/project/Grank/
欢迎各位开发者 Star && 发起 Pull Request。在项目的 issue 中为各位开发者标注了一些 good first issue,可以帮助各位开发者快速的熟悉项目。
也欢迎各位开发者针对 Grank 模型提出自己的看法
 |
1
kslr 2018 年 10 月 22 日 via Android
权重公式是啥,我遇到一些 issue pr 不少的,但是合并要等好几个月
|
 |
2
xiqingongzi OP @kslr 目前是等权重的,暂时还没有划分更加细致的内容,获取到数据后,构建三维坐标系,求三维坐标系中的折线,取其变化率。后续还要继续迭代不同场景的数据。比如 issue 的打开和关闭的速度,速度快的大体上应该优于速度慢的。类似的是 PR merge 的速度,同理。如果更细致的话,需要区分 pr 和 issue 的来源账号。
|