
这是一个创建于 3356 天前的主题,其中的信息可能已经有所发展或是发生改变。
URL2io.com — 提供简单、强大的网页正文提取服务
今天给大家分享的是一个网页正文提取服务 URL2Article ,主页地址:http://www.url2io.com
URL2Article 服务提供 RESTful API 接口,用来提取并解析网页中的正文区域,实现网页正文提取、标题提取、发布日期提取、下一页链接提取等。
功能列表
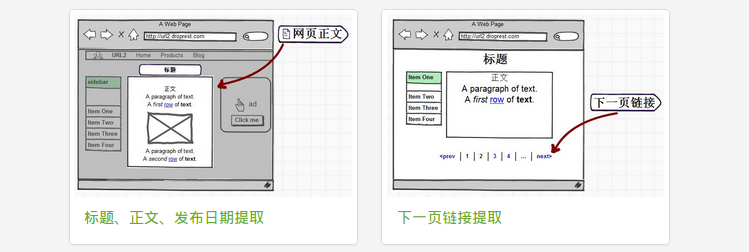
- 标题识别:
不仅仅是简单地提取 title 标签,而是智能识别网页正文的标题。
- 正文识别:
提取的内容将不含有任何广告、导航和其他非正文内容。网页正文中的所有链接、图片和其他媒体将予以保留。
- 发布日期识别:
智能识别文章的发布日期。
- 下一页链接识别:
智能识别当前网页的下一页链接。因为一篇完整的文章会被分成多个页面,所以这个功能会非常有用。
Demo
demo 地址:点这测试效果。
API 使用文档
可以查看相关文档 (URL2Article API doc) 来了解如何使用。
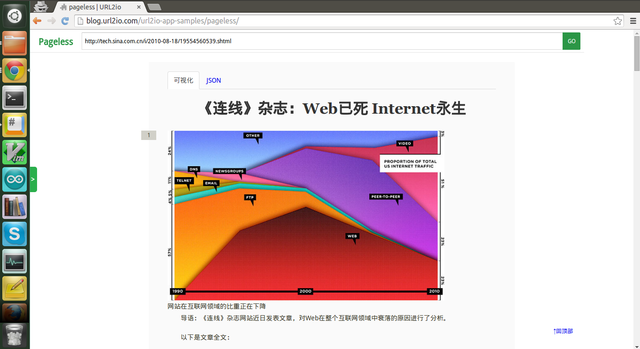
示例应用
为了让大家近一步了解这项服务,我们写了一个教学示例 Pageless, 它使用 URL2Article API 来提取网页正文,并自动将被分成多页的文章合并成一页。
演示地址, 代码在 Github: url2io-app-samples
Feedback
That's all. 希望有兴趣的童鞋可以试用一下,然后给点反馈(使用中出现的问题、会用来开发什么、意见和建议等都可以)。 欢迎留言讨论,或者 url2#sina.com ,或者 QQ 用户群: 341180183
第 1 条附言 · 2016-10-27 11:45:23 +08:00
近期的一些更新:(2016-10-02 ~2016-10-27)
根据大家的反馈和讨论做了大量更新,包括算法优化、新特性支持、其他更新等。
优化 (Breaking Changes): —— URL2Article
- 针对正文上卷问题做了优化
- 运行速度优化
新特性 (New Features):—— URL2Article
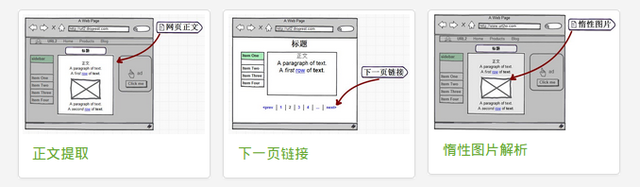
- 对于
<img>标签会保留全部属性,方便之后的处理。 - 支持惰性图片解析,智能识别正文中的惰性图片,并自动将图片地址解析为真实地址。
现有功能列表:
其他更新 (Other Changes):
- 在文档中心添加了 Quickstart ,提供多种编程语言(Python、NodeJS、PHP、Ruby ...)和工具(Curl ...)的使用示例,方便大家快速(约 20 秒)上手。
- 新增 PHP SDK:url2io-phpsdk ,由 @ety001 提供,十分感谢!
- 对于用 js 渲染内容的动态页面,在 UA 中使用兼容搜索引擎蜘蛛的特征串可以抓取到网页的静态版(感谢 @blueset 提供的思路),不过此方法的稳定性还在测试中,所以此次更新暂时还不能提供 -_-
That‘s all. 非常感谢大家的反馈和讨论,URL2io 的成长离不开热心朋友的关注与支持。 欢迎继续留言讨论,或者 url2#sina.com ,或者 QQ 用户群: 341180183,或者 Github Issues,或者关注微薄 @url2io
第 2 条附言 · 2018-01-28 11:43:10 +08:00
URL2io Enterprise 服务发布
URL2io Enterprise 是 URL2io 的本地部署版本,您可以在自己的环境中进行安装部署和管理。
目前包含了 URL2Article 服务(用来提取并解析网页中的正文区域,实现网页正文提取、标题提取、下一页链接提取等。)



 |
101
omg21 2017-06-10 13:36:52 +08:00
这个正文提取是什么思路?
|
 |
102
URL2io OP |