
因为推友问了一个问题:
@PofatTseng: 發問:要怎麼測量 symbol 在 MachO 裡佔據的大小,如果只看 __Text.__text 後 + 的偏移量準嗎?
@MapleShadow: @PofatTseng 看 Load Command 的 LC_SYMTAB 能满足你的场景吗?like
otool -l xxxx | grep -i LC_SYMTAB -B 10 -A 10
@PofatTseng: @MapleShadow 我想問的是單一個物件的相關 symbol ,比如我有一個 struct Foo {}
怎麼知道他在 MachO 裡佔去了多少空間?Foo 所有symbol 會在連續的位置上嗎
@MapleShadow: @PofatTseng 这个问题是个好问题,本来以为是一个简单的问题但是一点都不简单😂简单说通常情况下我们 App 的符号都被 strip 掉放进 dSYM 所以不占 Mach-O 空间,但是如果你是 debug 版或者动态库就会塞进去。至于长度,symbole table 的指针都是 8 字节(updated: 其实是 16 bytes),但是指向的符号 string 不是定长的,在 string table 里面取
我本以为是一个简单的问题,结果发现自己对 Mach-O 的很多细节都不太了解,于是学习了一下,以此文作为学习笔记。
如果只对上述问题的答案感兴趣的可以直接跳到末尾看结论。
P.S. 学习过程我参考了这篇文章但是因为年代有点久远,里面有些字段已经弃用了,当做字典参考就行。
我们在 macOS 系统如何启动?和 App 如何运行起来均有涉及 Mach-O 文件结构的讨论,但不全面。这里我们再详细介绍一下 Mach-O 的结构。下文使用的例子需要对比 Debug 和 Release 版,所以用我的 Mac 全屏休息提醒工具: Just Focus 为例。
首先我们来看最简单的 64 位单架构 Mach-O 文件(Fat Binary 后面再讨论),相关的数据结构定义在 XNU 源码的 EXTERNAL_HEADERS/mach-o/loader.h 里面。一个 Mach-O 文件有三个主要部分:
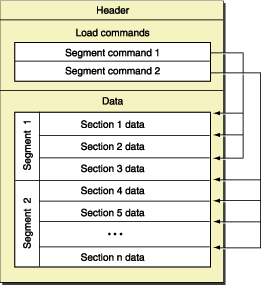
dyld 动态链接的符号表,标示初始函数入口,标示动态库的地址等等。segment,每个 segment 包含 0 个或多个 section。内核加载 Mach-O 时会根据 load commands 把相应的数据加载到内存里,根据 XNU 的注释,分 segment 是为了做数据对齐(segment alignment)以优化换页效率,下文分析 section 结构体时会讲到。Header 是定长的,在 64 位 Mach-O 中表现为 mach_header_64 结构体。
struct mach_header_64 {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */
uint32_t reserved; /* reserved */
};
magic: 大小端兼容性之用,MH_MAGIC_64 就是编译的文件和系统是同样的 byte order,MH_CIGAM_64 则是反过来。原因是曾经兼容 PPC 和 Intel 等多种 CPU,有兴趣的同学可以阅读: macOS 内核之 OS X 系统的起源。cputype: CPU 类型定义,CPU_TYPE_POWERPC 用于 PowerPC CPU,CPU_TYPE_I386 就是 Intel 的 x86,当然还有 iPhone 的 CPU_TYPE_ARM。cpusubtype: 属于 cputype 的细分,比如 i386 全部支持 CPU_SUBTYPE_I386_ALL,或者只支持 armv7 的 CPU_SUBTYPE_ARM_V7。filetype: 文件类型,决定了这个 Mach-O 文件的布局,定义从 MH_OBJECT 0x1 到 MH_DSYM 0xa。
MH_OBJECT: 编译过程产生的中间文件,这个文件比较特殊,其他文件分了多个 segment 和 section 但是这家伙只有一个 segment,把所有的 section 都塞进去。这个中间文件可以在 DerivedData/JustFocus-xxxx/Build/Intermediates.noindex/JustFocus.build/Debug/JustFocus\ Helper.build/Objects-normal/x86_64/ 里面找到。MH_EXECUTE: 标准可执行文件MH_BUNDLE: 动态库,macOS 上跟资源文件打包为 .bundle 或 .plugin,比如 /System/Library/Audio/Plug-Ins/HAL/AirPlay.driver/Contents/MacOS/AirPlay。本质上是动态库,Unix-like 系统叫做 .so,但是在 macOS 历史上曾经有点特殊,可以参考macOS 上 bundle (.so) 和 dylib 的区别。MH_DYLIB: 动态库,比如 /System/Library/Frameworks/AppKit.framework/AppKit 就是 MH_DYLIB 类型。MH_PRELOAD: 不在内核运行的特殊文件格式,比如内核还没加载前就要执行的 Bootloader,参考 macOS 内核之系统如何启动?MH_CORE: core 文件,程序 crash 的时候保存地址空间里的数据,服务端开发的朋友应该很熟悉。不过 macOS 默认不会把 core 信息 dump 到 /cores/ 目录,而是产生 crash log 放在 /Library/Logs/DiagnosticReports。可以参考这里打开 core dump.MH_DYLINKER: 动态链接器类型,一般我们写的 App 都是用系统的 /usr/lib/dyld,这个文件就是 MH_DYLINKER 类型。MH_DSYM: 编译后的 .dSYM 包里最主要的就是用 Mach-O 文件存储的 symbol 信息,比如 Alamofire.framework.dSYM/Contents/Resources/DWARF/Alamofire 就是 MH_DSYM 类型的 Mach-O 文件。ncmds: load commands 个数sizeofcmds: load commands 总长度flags: 这里面有一堆 flags,大部分是跟编译相关的,我也没全部学明白,所以干脆不描述了,感兴趣的朋友可以看这里。reserved: 应该只用来做字节对齐了
mh64->reserved = 0; /* 8 byte alignment */
Mach-O 文件中,读完 Header 和 Load Commands 之后,就是各种 Data 数据了,这些数据是以 segment 组织的。
一个 segment 有起始和终止的 offset,该范围内的数据就是 segment 的数据。segment 的标识是 segment name,宏以 SEG_ 开头。
但是 segment 的数据没有带上起始终止之类的信息,这些信息是在 Load Commands 中定义的。比如 LC_SEGMENT_64 会定义某个 segment 从哪里开始到哪里结束,名字是什么,虚拟内存的属性(比如 read-only),有多少个 section 等等,相当于一个索引,我们要获得有意义的数据就得先解析 Load Commands 然后再去读取对应的数据。
segment 的数据会被 dyld 根据 LC 的布局信息加载到内存里,所以 segment 都是按页对齐的。在 x86 上一页是 4096 bytes 也即 4 KB。
segment 做按页对齐其实就是把它所包含的所有 section 加起来除以 4 KB,不能整除就在最后一个 section 补 0。
理论上 Mach-O 文件里的 segment 有多大,加载后就会占多少的虚拟内存。但是实际上一个 segment 有可能在加载后比它在 Mach-O 里的数据大,比如 __PGAEZERO 这个 segment。在 Mach-O 里它其实是空的,只在 Load Command 记录了一个索引信息,但是加载到内存的时候,内核会给我们的 App 的地址开始端 0x0 分配一个空的页(到 0x1000)。这个空的内存页不带内存保护(声明为 VM_PROT_NONE),不可读写不可执行,我们平时遇到的访问野指针(NULL)就会命中这个区域,然后内核就让我们的 App crash 了。
上面 header 提到过 .o 文件比较特别,他是编译过程的中间文件(intermediate object file),出于文件大小的考虑,他的所有 sections 全部放在一个 segment 里面,并且这个 segment 没有名字。
segment 用名字区分,定义了这么多种:
#define SEG_PAGEZERO "__PAGEZERO" /* the pagezero segment which has no */
/* protections and catches NULL */
/* references for MH_EXECUTE files */
#define SEG_TEXT "__TEXT" /* the tradition UNIX text segment */
#define SEG_DATA "__DATA" /* the tradition UNIX data segment */
#define SEG_OBJC "__OBJC" /* objective-C runtime segment */
#define SEG_ICON "__ICON" /* the icon segment */
#define SEG_LINKEDIT "__LINKEDIT" /* the segment containing all structs */
#define SEG_IMPORT "__IMPORT" /* the segment for the self (dyld) */
/* modifing code stubs that has read, */
/* write and execute permissions */
#define SEG_UNIXSTACK "__UNIXSTACK" /* the unix stack segment */
有些是历史遗留产物,对我们来说有用的字段是这些:
__PAGEZERO 的作用讲过了不再赘述,这个东西是由静态链接器生成的。__TEXT 包含了所有的可执行代码,内存保护设置为 VM_PROT_READ 和 VM_PROT_EXECUTE。因为这一整段都是只读的,所以内核可以在内存不够的时候把这些数据换出(page out),需要的时候再换回来(page in)。__DATA 可写的数据,比如 ObjC runtime 支持的库。像这样的系统库有可能被多个进程链接,因为这一段内存可写,所以写操作会触发 copy-on-write,以此实现逻辑上每个进程有一份 copy (不一定真的要 copy)。__LINKEDIT 动态链接器需要用到的数据,比如 symbol table, string table 之类的下面这些是历史:
__OBJC Objective-C 的 runtime 支持,历史遗留字段,现在都放进 __DATA 里面了__ICON 应该是历史遗留产物,现在图标资源已经分离出去了,我们的 App 一般打包成 .app 文件夹。__IMPORT i386(IA-32) 也就是 32 位 x86 架构才会用到的一个字段,64 位改用 __DATA,__la_symbol_ptr 了。__UNIXSTACK 应该也是历史产物,参考这里。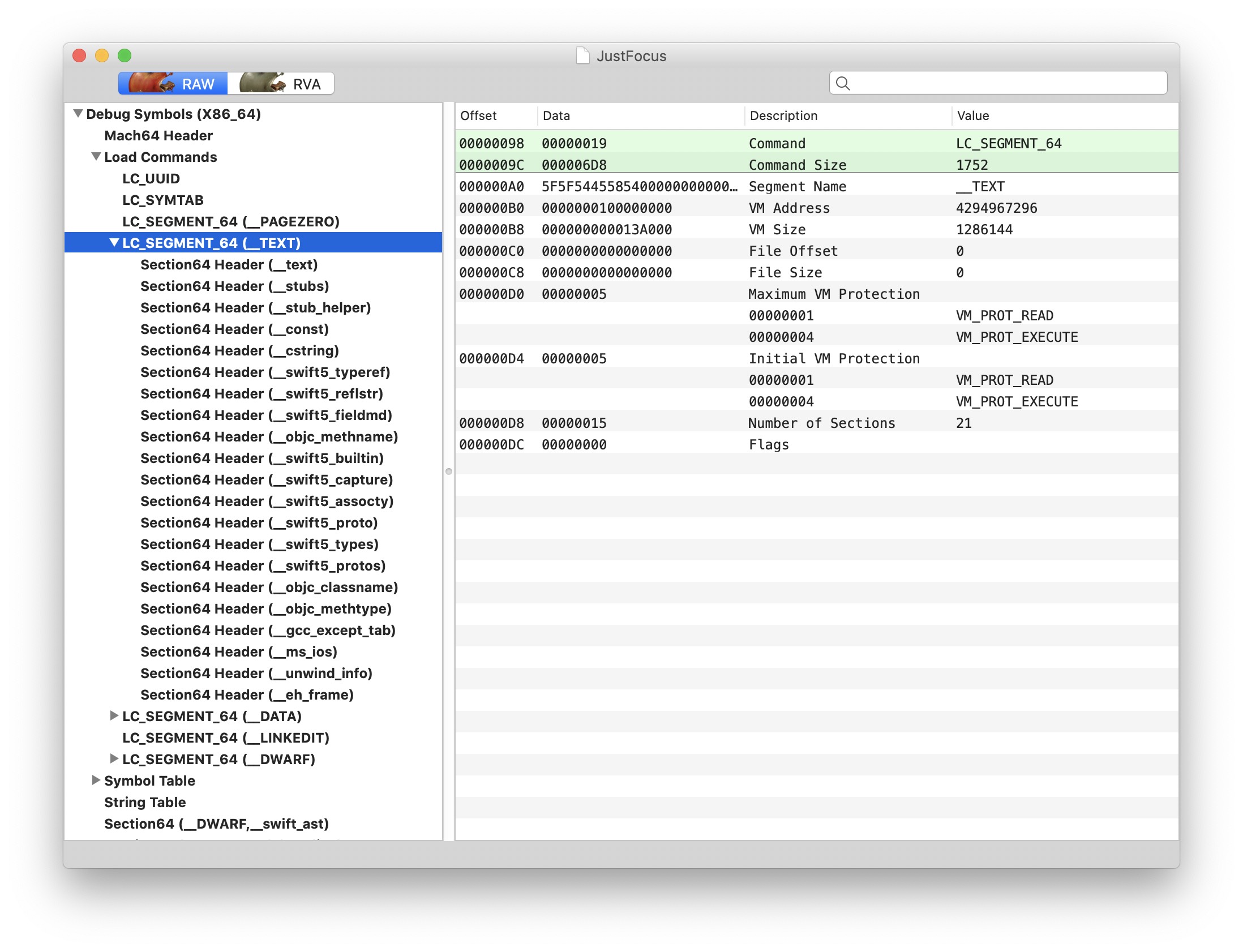
__TEXT 和 __DATA 一般会包含多个 sections,这些 sections 的命名和用途也会随着系统和编译器更新而变化,想要了解全部 section 及其作用的可以参考 LLVM 项目。这里我们看几个关键 section。
| Segment, Section | 作用 |
|---|---|
| __TEXT,__text | 可执行的机器码 |
| __TEXT,__cstring | 常量定义的 C strings,以 '\0' 结尾。编译器编译时会把所有 C String 合并优化,放在这个地方。 |
| __TEXT,__const | 初始化过的常量。编译器会把所有无需重定向的以 const 声明的常量放在这类。(多数编译器都把未初始化过的常量默认赋值为 0。) |
| __TEXT,__objc_ 开头的 | 以前放在 __OBJC 里 runtime 的支持,现在都放这里了。 |
| __TEXT,__stubs 和 __TEXT,__stub_helper | 动态链接需要用到的信息 |
想要理解完所有 __TEXT 里的 sections,你得学习 llvm 的源码。并且这些字段也经常随着系统和编译器的更新二更新,所以我选择放弃。真的需要的时候再回过来反查就行。在这一个 segment 里最重要的就是 __TEXT,__text,可执行的机器码放在这里。
| Segment, Section | 作用 |
|---|---|
| __DATA,__data | 初始化过的变量,比如一个可变的 C string 或者一个数组 |
| __DATA,__la_symbol_prt | Imported 函数的指针表,比如 libswiftFoundation.dylib 这样的动态库的符号的指针地址 |
| __DATA,__bss | 未初始化的静态变量 |
load command 的定义很简单:
struct load_command {
uint32_t cmd; /* type of load command */
uint32_t cmdsize; /* total size of command in bytes */
};
cmd 就是 LC_ 开头定义的宏,非常多,我们只看关键的,全量的请参考 loader.h 里的定义。
| Command | 结构体 | 作用 |
|---|---|---|
| LC_UUID | uuid_command | 编译出来的 image/dSYM 的 UUID,用于两者互相关联 |
| LC_SEGMENT_64 | segment_command_64 | 定义 segment |
| LC_SYMTAB | symtab_command | 定义 symbol table |
| LC_DYSYMTAB | dysymtab_command | 定义动态链接库需要用到的 symbol table |
| LC_UNIXTHREAD | thread_command | 程序的入口。现在大部分 App 都用 dyld 调起了,内核的 Mach-O 和 dyld 则还是用 LC_UNIXTHREAD 声明入口 |
| LC_MAIN | entry_point_command | 程序的入口,需要配合 LC_LOAD_LINKER 使用,把该地址交给 dyld 然后由它来调起 App 的入口函数 |
| LC_LOAD_LINKER | dylinker_command | 声明用到的 dy linker, iOS/Mac 一般都是 /usr/lib/dyld |
| LC_LOAD_DYLIB | dylib_command | 该 Mach-O 需要用到的动态库 |
通过 Load Command 获取了 segment 的 offset 和 size 之后就可以读取为 segment_command_64 和 section_64 结构体了。
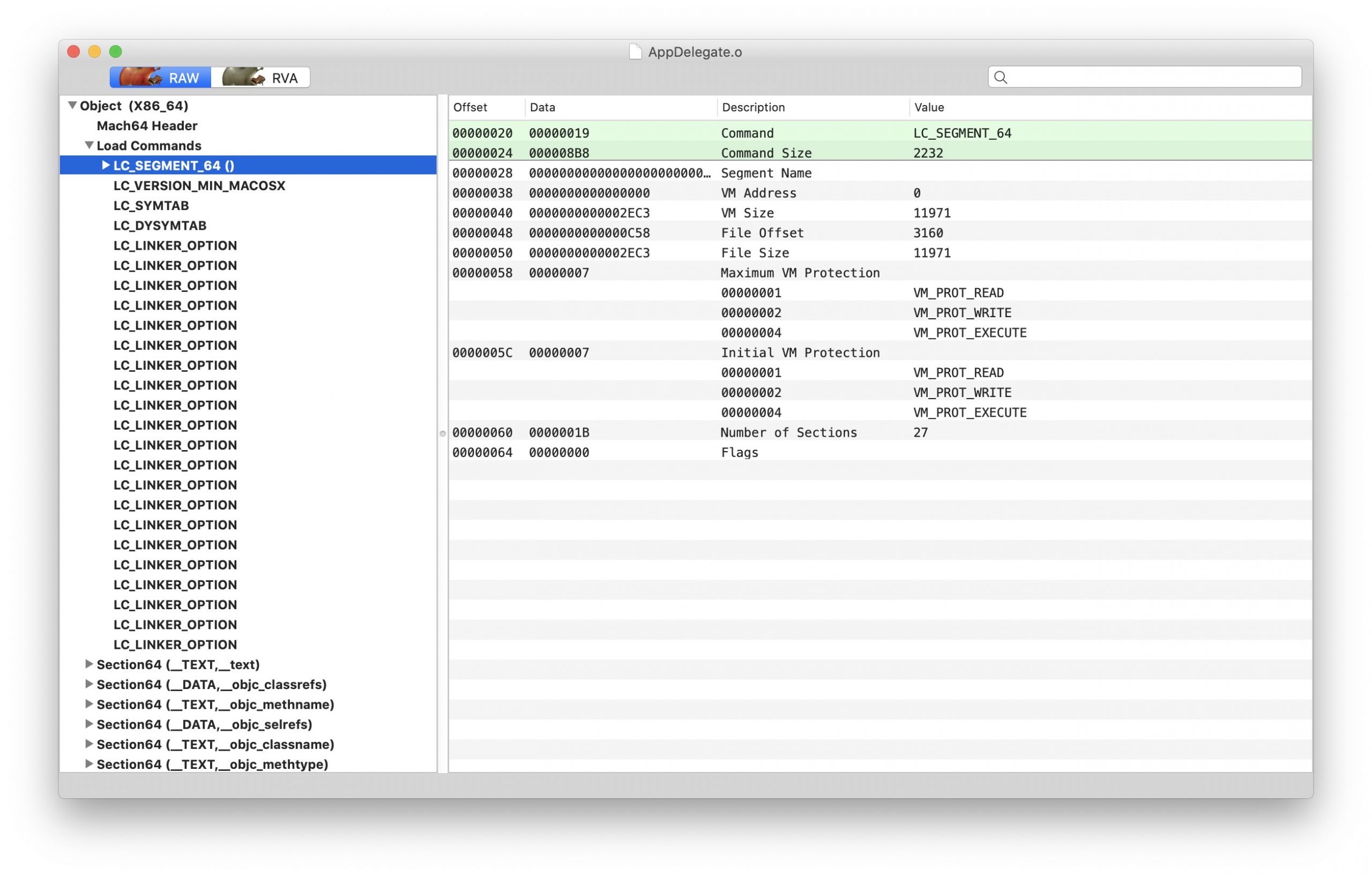
struct segment_command_64 { /* for 64-bit architectures */ uint32_t cmd; /* LC_SEGMENT_64 */ uint32_t cmdsize; /* includes sizeof section_64 structs */ char segname[16]; /* segment name */ uint64_t vmaddr; /* memory address of this segment */ uint64_t vmsize; /* memory size of this segment */ uint64_t fileoff; /* file offset of this segment */ uint64_t filesize; /* amount to map from the file */ vm_prot_t maxprot; /* maximum VM protection */ vm_prot_t initprot; /* initial VM protection */ uint32_t nsects; /* number of sections in segment */ uint32_t flags; /* flags */ };
struct section_64 { /* for 64-bit architectures / char sectname[16]; / name of this section / char segname[16]; / segment this section goes in / uint64_t addr; / memory address of this section / uint64_t size; / size in bytes of this section / uint32_t offset; / file offset of this section / uint32_t align; / section alignment (power of 2) / uint32_t reloff; / file offset of relocation entries / uint32_t nreloc; / number of relocation entries / uint32_t flags; / flags (section type and attributes)/ uint32_t reserved1; / reserved (for offset or index) / uint32_t reserved2; / reserved (for count or sizeof) / uint32_t reserved3; / reserved */ };
其中比较特殊的是,最后一个 segment 也就是 __LINKEDIT 存储 link edit information,里面有 symbole table, string table, dynamic symbol table, code signature 等信息。
但是他的 LC_SEGMENT_64 里面却没有包含里面的 sections 信息,你需要配合 LC_SYMTAB 来解析 symbol table 和 string table。
// LC_SYMTAB 对应的结构体
struct symtab_command {
uint32_t cmd; /* LC_SYMTAB */
uint32_t cmdsize; /* sizeof(struct symtab_command) */
uint32_t symoff; /* symbol table offset */
uint32_t nsyms; /* number of symbol table entries */
uint32_t stroff; /* string table offset */
uint32_t strsize; /* string table size in bytes */
};
没有对 Mach-O 文件的符号进行任何处理的时候,所有符号表信息都会放在 Mach-O 文件里。
我们可以用 MachOView 直接查看 Symbol Table。
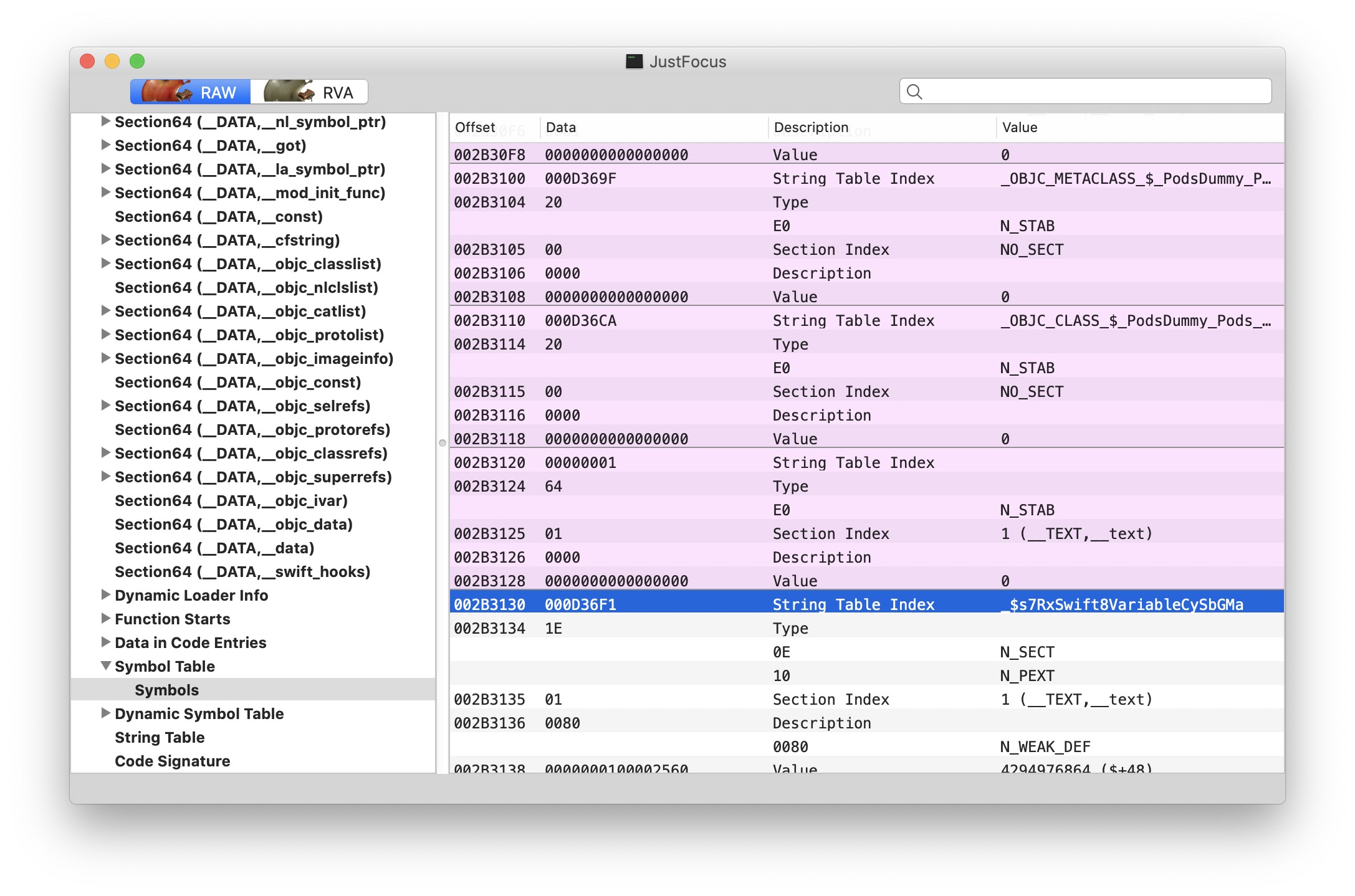
这是 Just Focus Debug 版的符号表,但是 Xcode 在编译的时候默认会对 Release 版做一个优化: 把符号从 App 的 Mach-O 去掉,写进成对的 dSYM 文件。可以在你的 Xcode Project -> Build Settings -> Build Options -> Debug Information Format 看到各个 scheme 的配置。
DWARF 是 Executable and Linkable Format 配套的一个 Debug 数据格式。ELF 则是 Unix 的一个标准格式,多数 Unix 系统和 Linux 都采用这种格式定义可执行文件。macOS 虽然不支持 ELF 但是用了 DWARF 作为 debug 数据格式。
DWARF 生成 debug 信息并塞进 Mach-O 文件DWARF with dSYM File 生成 debug 信息并放到配套的 dSYM 文件,以 UUID 匹配,App 的Mach-O 里不带符号信息。
可以读取 LC_SYMTAB 然后在最后一个 segment 里找到 symbol table。LC_SYMTAB 数据是一个定长的 16 bytes 数据。
然后通过 symbol table 的 string table index 获取该 symbol 对应的 string,这个就不是定长的了,读到 \0 停止。所以符号的 string 越长占 Mach-O 的 size 就越大。
2019-11-16 updated: 上面的说法是你使用 MachOView 这样的工具时,可以肉眼 filter 已知的 string 所以可以这样查。但是系统执行文件的时候,拿到的是 (__TEXT,__text) 里的一个个指针地址,crash 发生的时候内核会保存当前进程的内存空间快照,crash 时的指令地址反查 symbol 就能得到我们人能阅读的 crash 堆栈。所以如果你想要通过 string 裸读 Mach-O 文件来反查对应指针地址的话,因为 string table 里的存储是连续的 bits,没有索引就无法读出 string,所以只能解出所有结果,然后自己去 filter。
无用 class/struct 会占用 Mach-O 空间吗?
如果是 C/C++ 的符号,编译链接时会知道这个 class/struct 没人用,直接优化删掉,等于没有。
如果是 ObjC 的符号,则还是会保留,因为有 runtime,你不知道它到底有没有被人用。
所以 ObjC 无用的 class/struct 在 release 下不会占用 Mach-O 的 Symbol Table/String Table 空间,但是会占用 Mach-O 的 (__TEXT,__text) 空间。
foo 的所有符号会连续吗?
不连续,link-editor 比如 dyld 可以通过读取 LC_SYMTAB, LC_DYSYMTAB 等 load command,从对应的 Symbol Table 和 Dynamic Symbol Table 找到符号。
比如 Just Focus 有一个 Swift enum JFAppState 在 Symbol Table 上它的符号并不连续。
什么符号可以从 Mach-O 去掉?
默认情况下所有符号都会保留在 Mach-O 里,这样调试的时候就能显示全部符号,但是如前所述发布版本并不需要这些符号,完全可以去掉以节省空间。Xcode 对 Strip Style 也提供了多个选项可供设置: Build Settings -> Deployment -> Strip Style
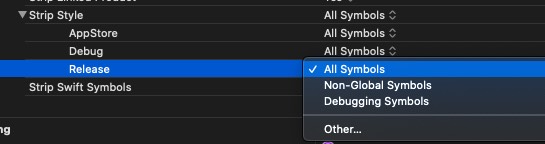
单独编译静态库是无法 Strip All Symbols 的,不然你引用这个静态库链接器就不知道该怎么链接了。但是打包成一个完成 App 的时候,静态库的符号可以被去掉。
理论上动态库的符号无法去掉,但是编译器可以根据你调用的方法进行优化,只保留用到的符号。但是 ObjC 有 runtime,应该无法确定哪些符号用到哪些没有。llvm 用到的链接器 ld 提供了 -strip-unneeded 的选项,不过我还不知道他是怎么实现的,大概要把编译原理从头学一下然后再学一遍 llvm 才知道了。
主流操作系统 Unix-like, Windows 和 macOS 虽然各有自己可执行文件的格式,但是设计上大同小异。
Mach-O 文件格式随着系统与编译器的升级加入和删除了很多古老的 segment 或者 section,而这些特性都需要编译器(llvm)与执行环境(xnu)的配合开发。
作为一个编译后的产物,Mach-O 里的字段有很多跟编译器的优化相关。这些字段如果要一个个理解清楚需要很多时间,并且需要熟悉编译原理以及 llvm 自家的特性(毕竟很多优化都是独有的)。所以没有必要细究每一个字段的作用,真的用到的时候再查就行了。
但是以鸟瞰的视角了解 Mach-O 文件的结构,对于理解一些古怪的问题还是很有帮助的。



今天和同事讨论到一个问题:
bundle和动态库一样吗?
同事说 bundle 只是包含了其他资源而已,其实就是动态库。
我看 Mach-O 文件类型里 MH_BUNDLE 与 MH_DYLIB 是分开的,所以觉得 .bundle 里面的 Mach-O 文件和 dylib 的 Mach-O 文件应该会有些不一样。不过我也不知道有什么不一样,所以学习了一下,以此文记之。
定义一下动态库为 dylib Mach-O 文件, bundle 指的是 .bundle 文件夹里面的 Mach-O 文件,一般类 Unix 系统叫做 .so 库,不过苹果官方建议叫做 .bundle。
P.S. 这里苹果官方不厚道,它推荐用 .bundle 作为 MH_BUNDLE 类型文件的后缀名但不强制,然后自己还把 .bundle 后缀名用作一个类似 .app 的资源与可执行文件打包。所以很容易就会混淆两个概念。实际上我看到的 MH_BUNDLE 类型的 Mach-O 基本上都没有后缀名,有 .bundle 后缀名的基本上都是资源与可执行文件的打包。
先说结论: 通常语境下 bundle 和 dylib 没有区别。要较真的话也只有在 OS X 10.5 以前才有比较大的区别,所以同事说 bundle 和动态库没有区别是对的。
P.S. ELF 系统(Executable and Linking Format,Unix-like 系统基本都是)上这两者完全相等,只有 Mac 的 dyld 对他们做了点区别对待。
Mach-O 文件的 header 里有一个 type 字段表示当前文件的类型,如果把 .bundle 文件夹解开,里面的 Mach-O 文件的类型是 MH_BUNDLE,而 dylib 则是 MH_DYLIB。
➜ otool -hv AppKit Mach header magic cputype cpusubtype caps filetype ncmds sizeofcmds flags MH_MAGIC_64 X86_64 ALL 0x00 DYLIB 60 8344 NOUNDEFS DYLDLINK TWOLEVEL APP_EXTENSION_SAFE
➜ AppKit.framework otool -hv /System/Library/Audio/Plug-Ins/HAL/AirPlay.driver/Contents/MacOS/AirPlay Mach header magic cputype cpusubtype caps filetype ncmds sizeofcmds flags MH_MAGIC_64 X86_64 ALL 0x00 BUNDLE 21 2544 NOUNDEFS DYLDLINK TWOLEVEL
在 macOS 上,动态加载通过 dyld 进行。bundle 和 dylib 两种文件都可以使用 dlopen 加载。两者的区别要在 dyld 的源码里面找。
dyld 的 dlopen() 实现主要关注是这几个地方:
dlopen()load()loadPhase0()loadPhase1()loadPhase2()loadPhase3()loadPhase4()loadPhase5()loadPhase6()checkandAddImage()
dylib 就从 sAllImages 找到一样路径的 image 先删掉dylib 和 bundle 能使用的 API 不一样,所以这里还得判断 context.mustBeBundle 和 isBundle()是否匹配// some API's restrict what they can load
if ( context.mustBeBundle && !image->isBundle() )
throw "not a bundle";
if ( context.mustBeDylib && !image->isDylib() )
throw "not a dylib";
bundle 就不会加到 global list,因为 bundle 可以只加载但不链接。所以结论是 bundle 可以只加载不链接,而 dylib 加载后就链接了。
NSObjectFileImage 只有 bundle 能用dyld 提供了 NSObjectFileImage 接口,这些接口只有 bundle 能用,只加载不链接就通过这个接口来实现。
NSObjectFileImageReturnCode NSCreateObjectFileImageFromFile(const char* pathName, NSObjectFileImage *objectFileImage)
里面会调用 load() 方法加载 bundle,这类接口的 context.mustBeBundle 为 true,底下判断的时候遇到非 bundle 就会报错。
load() 之后再使用以下方法链接:
NSModule NSLinkModule(NSObjectFileImage objectFileImage, const char* moduleName, uint32_t options)
NSObjectFileImage 相关的接口从 OS X 10.5 开始已经被废弃了。
在 Mac OS X 10.5 (2007 年) 以前,bundle 可以被 unload 但是 dylib 不可以,10.5 开始 dylib 也可以被 unload 了。dlclose() 的实现很简单,调用时减一下引用计数,为 0 就从走垃圾回收接口 garbageCollectImages() 删掉。
经过以上调查,现如今的 bundle 跟 dylib 在使用上几乎可以完全对等。要说区别那就只有编译 dylib 为 shared library 的时候需要加上版本号,而 bundle 只会给自己的 App 用就没有必要了。
libbz2.1.0.5.tbd
libbz2.1.0.tbd
libbz2.tbd
至于 Mach-O Header file type 的区别,只是给 dyld 作 NSObjectFileImage 接口判断而已,这些接口废弃了那自然就没有区别了。

前面的文章都在讲内核代码细节,实在有点费脑,这次我们来聊点轻松的历史故事吧。现在我们已经知道 macOS 的内核主要是由 BSD 和 Mach 组成,但是为什么是这样的混合设计呢?
Amit Singh 的 Mac OS X Internals 一书在开头就介绍了从 Apple OS X 诞生的历史,几年前刚买这本书的时候我还觉得为啥讲这么长的故事一直不进入“干货”部分。现在回过头来看,正是作者介绍了这段历史,后面内核中一些有点疑惑的地方才顺理成章。
本文主要来自 Amit Singh 书中所述,再加上我查阅的资料所写。年代久远,如有谬误,烦请诸位不吝雅正。
乔布斯(Steve Jobs)和史蒂夫·沃茲尼克(Steve Wozniak) 1976 创办苹果公司,关于这家公司的故事已经广为流传,OS X 的诞生也与乔布斯后来的回归息息相关。我们知道乔布斯离开苹果后创办了 NeXT 公司,也知道今天我们开发的 iOS/macOS 系统跟 NeXTSTEP 系统有千丝万缕的关系。但是乔布斯一回归 NeXTSTEP 就变成今天的 macOS 了吗?并不是,历史的道路是非常曲折的。

时间回到 1977 年,乔布斯在 West Coast Computer Faire 发布了 Apple II 这款个人电脑,这是苹果公司对外发售的第一款消费级个人电脑。这款产品大获成功,也让两位创始人成为百万富翁。
1984 年 1 月 22 日,苹果在超级碗(Super Bowl)中场休息时播放了一个堪称历史经典的广告——
,以此发布新产品 计算机。但是在苹果公司内部,与 Macintosh 研发的同一时期,乔布斯还带领了一个团队开发 Lisa 电脑(1983 年发布)。现在我们知道这是一个失败的产品,并且乔布斯也于 1985 年被董事会赶出了苹果,后来自己创办了 NeXT 公司。
一晃四年过去,1988 年苹果的团队在开会讨论下一代操作系统应该带上什么特性。他们在白板上用三种颜色的便利贴表示不同的 idea:
当时 Macintosh 上跑的系统版本是闭源的 System 6,1988 年 4 月发布,苹果自家的很多产品都使用这个系统。在这个阶段,苹果的图形界面操作系统依然还是处于比较领先的地位,市面上有 GUI 的操作系统还不算多,做得好的更没几个。但是苹果的下一代系统 System 7 的研发却出现了问题,一连好几年没法发布。
这时候隔壁家微软已经在 1990 年发布了 Windows 3.0 (1.0 和 2.0 市场反响都一般),借此一炮而红,成为当年最流行的图形界面操作系统。

1991 年苹果终于发布了 System 7 版本,但是这些“蓝色”的 idea 不过是对现有系统的改进,并没有特别大的突破。

而微软在 Windows 3.0 成功后,又继续在操作系统上发力。当时微软内部有一个代号为 Chicago 的项目,原计划在 1993 年发布。但是项目一直延期,最终在 1995 年才终于面世。这款产品就是广为人知的 Windows 95。除了家用系统,微软在 1993 年也发布了面向服务器的 Windows NT 系统,自带网络服务, NTFS 文件系统,支持 Win32 API。

反过来看苹果,却陷入了深深的危机。1998 年开始苹果一直在探索自家操作系统未来的方向。除了已经发布的“蓝色” System 7,“粉红色”的部分苹果与 IBM 合作,成立 Taligent 公司试图研发下一代操作系统,但是该项目一直没有产出,直到最后公司被 IBM 收购也没有对外发布过任何系统。
至于更加激进的“红色”项目,代号为 Raptor,则无疾而终。个中细节在网络上未有记录,只在《Mac OS X Internals》一书有所提及。可以说 1990 年代的苹果,正在一步步走向深渊。
面对微软的挑战,苹果做了很多操作系统的探索和尝试,内部开发与外部合作兼备。当时的 CPU 还不像今天基本只剩 Intel 和 AMD 两家(手机端基本都是 ARM),Macintosh 的机器使用的是摩托罗拉 68K 系列的 CPU,而 Windows 则使用的是 Intel 的 x86 系列 CPU。68K CPU 虽然能提供 Intel 486 一样的能力但是发热比 486 高,这时候如果苹果也开始迁移到 Intel 平台那可能历史就改写了。
Intel 的 CEO Andy Grove 还找过苹果,期望能让 Macintosh 支持 Intel CPU。但是当时苹果评估之后觉得 Intel 的 CISC (复杂指令集) 设计未来肯定打不过 RISC (精简指令集),所以没有投入 Intel 的怀抱。他们选择了与 IBM, 摩托罗拉合作成立 AIM 联盟,研发 RISC 的 PowerPC CPU。
1994 年苹果发布的高性能机器 Power Macintosh 首次搭载了这颗芯片,在市场上获得不错的反响,在 9 个月内卖出超过 100 万台。但是长期来看当时没有选择 Intel 是个错误的决定。
但是研发 PowerPC 的同时,苹果也没有放弃 Intel x86 架构。1992 年他们跟 Novell 公司合作,打算把 System 7 移植到 x86 架构上。苹果有操作系统经验,Novell 则有跨平台经验。但是 1993 年中,PC 价格战开始后因为业绩压力董事会把 CEO John Sculley (也就是那位著名的卖可乐的 CEO,也是他把乔布斯赶走的)辞退了,新任 CEO Michael Spindler 对 Intel 不感兴趣于是这个项目就被取消了。

Michael Spindler 在 CEO 的位子只坐了 3 年,他在职期间发布了 PowerPC 倒是挺成功的,但是后来的 Newton 和 Copland 操作系统却均是失之作。
苹果一直以来都自信自家的产品能提供远超其他产品的用户体验,但是随着 Windows 95 的发布这种差距在缩小,并且随着 PC 价格的下降苹果的性价比已然极低,于是苹果急于让自家的操作系统提供远超微软 Windows 的能力。
从 System 7.6 开始,Macintosh 的操作系统正式改名为 Mac OS 7.6。1994 年苹果宣布 Mac OS 8 将提供非常革命性的新特性,项目代号为 Copland。
Copland 的目标包括拥抱 RISC 让整个系统原生支持 PowerPC 架构,集成并改进苹果现有的技术比如 OpenDoc,ColorSync 等等。保留现有的 Mac OS 界面并提供可自定义的能力。扩展系统能力,允许跟 DOS 和 Windows 系统协作。支持多用户登录。以及一些其他革命性的特性。
一开始这个项目在公司内是非常激动人心的,1995 年还对 50 个 Mac 开发者放出了 Beta 版。但是从那以后,Copland 就再也没有更新过,也从来没有正式对外发布过。
当时的苹果公司以及负债累累,John Sculley 辞职的时候苹果公司还有 20 亿美元的现金与 2 亿美元的负债。到了 1996 年,有超过 500 名工程师投入到 Copland 项目中,光这个项目一年就要花去 2.5 亿美元的预算。那一年苹果亏损 7.4 亿美元,CEO Michael Spindler 被辞退,Gil Amelio 上任,该项目被正式取消。
Gil 后来在他的 On the Firing Line: My 500 Days at Apple 一书中是这样描述这个项目的:
just a collection of separate pieces, each being worked on by a different team… that were expected to magically come together somehow…
Copland 项目虽然失败了,但是它让苹果重新思考了自家操作系统的定位,同时感受到了强烈的生存危机,毕竟从 1991 年发布 System 7 到 1997 年之间,苹果一直没能发布一个正式的大版本。
此时的苹果急需寻找一款足够优秀的操作系统来拯救苹果。这时候收购一个操作系统公司的选项浮出水面。差不多是时候乔布斯要出场了,但是在他出现之前,还有另外一家公司成为苹果的候选。

1996 年 Gil Amelio 上任后苹果已岌岌可危。当时考虑过跟微软合作,开发基于 Windows NT 的 Apple OS。同时也考虑采用 Sun 公司的 Solaris 系统,或者收购 Be 公司的 BeOS。
Be 公司也跟 Apple 颇有渊源,甚至有点狗血。BeOS 的创始人 Jean-Louis Gassée 曾经是苹果公司欧洲运营负责人。1985 年 Gassée 得知乔布斯准备把当时人还在中国的 CEO John Sculley 赶走的时候,通知了 John Sculley,于是 Sculley 召开了董事会讨论这件事情。当时乔布斯在苹果内部可谓是众叛亲离,这是他自己盲目自信带来的后果。当时他利用自己的权威给 Macintosh 部门很多资源,员工的收入都比隔壁 Apple II 高得多,但实际上 Apple II 才是真正贡献公司利润的部门。1985 年初连创始人史蒂夫·沃茲尼克也离开了苹果,连带着很多高层也相继离开。所以最终董事会站在 Sculley 这边,反而把乔布斯赶走了。
John Sculley 成功把乔布斯赶走了之后,就让 Gassée 主管 Macintosh 产品。1988 年 Gassée 主管苹果的高级产品开发和全球市场,有传言称他要取代 Sculley 成为 CEO。不过 1990 年他就被 Sculley 和其他董事会成员要求离职了。
1991 年离开苹果之后 Gassée 创办了 Be 公司,带走了一堆苹果员工。他们开发了 BeOS,能在 PowerPC 上跑,目标很明确就是希望苹果可以收购他们,取代前面说的已经快挂掉的 Mac OS。BeOS 的特性很多,首先可以在 PowerPC 运行,然后支持内存保护,抢占式多任务,支持对称多处理等等。但是,BeOS 当时还没有完全实现,也并没有经历过市场的考验。
1996 年苹果给 Be 开价 5000 万美元(Be 公司的总投资大约 2000 万美元),但是 Gassée 非常自信地给出 5 亿美元回价。苹果又协商给 1.25 亿,Gassée 回 3 亿,苹果再开价 2 亿,但是 Gassée 仍不接受,给了个最终价 2.75 亿。
于是交易告吹。
苹果于同年底宣布以 4 亿美元收购了乔布斯的 NeXT,1997 年 2 月正式完成收购,乔帮主回归苹果,7 月份说服董事会辞退 Amelio,自己成为公司 CEO,开启了苹果的新世纪。
![]()
NeXT 的操作系统 NEXTSTEP (也写作 NeXTstep, NeXTStep) 跟 BeOS 不一样,它是经历过市场验证的。苹果当时的 CEO Amelio 还戏称这场收购是用 "plan A" 取代了 "plan Be"。
最终 NEXTSTEP 与 Mac OS 的结合诞生了如今我们使用的 Mac OS X (macOS)。不过并不是说乔布斯一回到苹果这系统就整合完了,他的回归到 OS X 诞生大约隔了 3 年。

1985 年乔布斯离开苹果的时候,带走了 5 个苹果员工创办 NeXT 公司,专做面向教育的产品。四年后,1988 年 10 月 12 日,
,跑在上面的操作系统就是 NEXTSTEP。NeXT 公司的创始团队还包括来自 CMU Mach 内核的团队的成员 Avie Tevanian。他是 Mach 内核的主要设计者和开发者之一。所以 NEXTSTEP 系统从第一天起就是基于 Mach 和 BSD 内核进行开发。当时发布的第一个版本采用的是 Mach 2.0 版本和 BSD 4.3 版本。Avie Tevanian 后来也成为苹果公司软件工程的高级 VP,2003 年当上 CTO,2006 年离职。
NEXTSTEP 系统提供了图形界面和 Unix 风格的命令行操作。可以说今天我们见到的 macOS 的很多特性都来自于 NEXTSTEP。比如说:
Application Kit1992 年,NEXTSTEP 发布了可以跑在 x86 架构上的版本。当时它们可以支持在 68K(摩托罗拉), x86(英特尔), PA-RISC(惠普), SPARC(Sun)等多种不同的芯片上运行。并且可以把多种架构的代码打包成一个 fat binary,也就是我们今天在 iOS 上常见的所谓 Universal Binary。

NeXT 公司还和 Sun 公司合作开发了 OpenStep。这是一套能跑在 SunOS, HP-UX 和 Windows NT 上的面向对象的接口。基于这个接口,一个精简版的 NEXTSTEP 就可以跑在支持这个接口的机器上。1994 年 OpenStep 发布了第一个版本。
不过没多久 NeXT 公司就转而专注在 WebObjects 技术上了。1996 年乔布斯还在微软的 Professional Developers conference 演示了这一技术: [Microsoft Professional Developers Conference 1996 Keynote Speaker: Steve Jobs](Microsoft Professional Developers conference)
简单说这个技术就是用 Java 开发网站的技术。这里有一份官方文档有兴趣的读者可以看看。
这项技术在 NeXT 被苹果收购之后也用在了部分苹果产品上,但是从 2008 年开始就不更新了,2016 年官方宣布中止开发。据称目前还用于 Apple Store 以及 iTunes Store 的一部分,不过除非内部负责该项目的开发者,不然无从考证了。
我们知道 Mach 是 NEXTSTEP 以及后来的 OS X 非常重要的组成部分。它是由 CMU (Carnegie Mellon University) 开发的微内核。它的前身是 CMU 开发的 Accent 内核,Accent 的前身则是 UR (University of Rochester) 开发的 RIG (Rochester's Intelligent Gateway) 项目的一部分。
1975 年一群来自罗切斯特大学(University of Rochester)的学者在开发一个智能网关系统,叫做 RIG (Rochester's Intelligent Gateway)。这个项目跑在 Aleph 系统上,这个系统跑在 Data General 公司的 Eclipse 小型机上。

这个内核的主要功能是提供 IPC 能力(interprocess communication),也就是我们常说的“进程间通信”。我们可以从 Aleph 的 IPC 抽象上看到 Mach IPC 的设计。系统采用 Message 在多个进程间传递信息,采用 Port 来对应信息的接收方。跟后来的 Mach 设计是一样的。但是当时这个系统有几个非常严重的基础缺陷,比如说:
关于这个系统的论文可以在这里下载,有兴趣的读者可以看看。

RIG 项目的其中一个成员——也是上述论文的作者之一——Richard Rashid 在 1979 年转到 CMU 当教授。在 CMU 工作的其中一个项目就是 Accent 内核,从 1981 年开始正式启动。这个内核面向的是网络操作系统。作为一个面向通信的系统,Accent 也采用了类似 RIG IPC 通信方式的设计,不过做了很多改进:
wire 到物理内存上(还记得我们之前分析内存接口的时候有一个 wire 类型的内存占用吗?)看起来 Accent 比 RIG 好多了,但是这个内核设计的时候是跑在 PERQ 工作站上的。虽然它拥有很多厉害的特性但是设计的时候非常依赖硬件,也不支持 Unix 软件运行。
为了支持 Unix, Richard Rashid 开始了 Mach 项目,并于 1985 年发布了第一个版本。这位厉害的学者因为 Mach 一战成名,1991 年加入微软,后来成为微软的 VP 直到 2012 年。
关于 Accent 的论文可以到这里下载。
Mach 内核的设计目标之一是要兼容 Unix 系统。在这个项目启动的时候,Unix 已经存在了 15 年之久,有大量的 feature 被集合到这个巨大的内核里。
Richard 甚至把 Unix 戏称为"所有新特性或功能的垃圾场"(dumping ground for virtually every new feature or facility)。所以 Mach 项目就是要设计一个可以为其他操作系统内核基础的一个微内核,他们的目标包括:
Mach 内核设计的时候主要 focus 在 CPU 支持与内存管理上,没有考虑支持文件系统,网络接口或者设备 I/O 接口。当初他们的设想是,真正的操作系统可以作为一个用户态的程序跑在 Mach 内核上。Mach 内核采用 C 语言开发,这意味着可以很轻易地移植到各个平台。
Mach 内核开发的时候以 4.3BSD 为基础进行开发。Richard 由于有 RIG 和 Accent 的经验,在 Mach 内核的设计上可谓驾轻就熟。1986 年正式对外发布的时候,他们在论文上称这是"为 UNIX 开发的一个新内核"。
当时选择新的 Mach 内核作为自家操作系统内核的,不止 NeXT 一家。1994 年苹果还没收购 NeXT 之前,在 Copland 项目中也用到了作为 Mach 3.0 作为系统内核。但是在对外公布的测试版中却极其不稳定。这个内核项目叫做 NuKernel,当然后来也随着 Copland 项目的结束也无疾而终。

在前面的文章中我们也提到过 Mach 内核的一些基本抽象,这里还是简单介绍一下:
task 表示一个或多个线程资源的集合,资源包括内存,ports(翻译成端口好像不太合适), CPU 核心等等。我们可以简单理解为大家熟悉的“进程”。thread (线程)是一个 task 的基本执行单元。task 负责提供线程的运行环境,多个线程共享相同的资源。这点与 Accent 不同,Process 被进一步分为 task 和多个 threads。port 跟 Accent 的 port 很像,也是一个内核维护的消息队列,用于 IPC 通信。在 Mach 里一个 port 表示为一个整数。message (消息)就是用于 IPC 的结构体,可以在不同的 task 之间通信,也可以在同一个 task 里的不同 thread 通信。memory object 可以看成是映射到一个 task 内存空间的的一个数据集合(包括文件数据)。Mach 的内存管理分为 pmap 物理内存层和 vmmap 虚拟内存层。需要 PMMU 硬件支持换入换出,现代 CPU 都集成 MMU 了,当年的 MMU 还是外置的。当年 CMU 做了一个非常重要的决定,就是 Mach 内核开源且无任何 licensing 约束。这意味着任何人都可以免费发行 Mach 内核。

1996 年 12 月苹果宣布收购 NeXT 公司, 但是在那之前,2 月份苹果就已经开始了一个特别的项目:把 Linux 移植到 PowerPC 平台,让 Macintosh 机器也能跑 Linux。
这个项目的产品叫做 MkLinux, 由 OSF (Open Software Foundation) 和苹果公司联合开发的,目标是让 Linux 内核跑在 Mach 3.0 内核上。
OSF 早期的成立是为了给 UNIX 系统提供一个开放标准。在 CMU 开发 Mach 2.5 版本的时候,OSF 宣布用于其开发的 OSF/1 系统,并将 host Mach 内核的未来版本。事实上 Mach 3.0 版本是从 CMU 开始,后来也是由 OSF 开发完成。当时 NEXTSTEP 用的是 Mach 2.x 内核。
1996 年在 WWDC 上苹果公司正式宣布将把 Linux 移植到 Power Macintosh 机器上,名为 MkLinux (Microkernel Linux)。
这个项目后来也随着 OS X 的整合而终止,交回给社区维护。但是这个项目对苹果整合 NEXTSTEP 帮助不小,在官方的 Kernel Programming Guide 有曰:
OS X is based on the Mach 3.0 microkernel, designed by Carnegie Mellon University, and later adapted to the Power Macintosh by Apple and the Open Software Foundation Research Institute (now part of Silicomp). This was known as osfmk, and was part of MkLinux (http://www.mklinux.org). Later, this and code from OSF’s commercial development efforts were incorporated into Darwin’s kernel.
这也是为什么我们看 XNU 代码里面,Mach 的部分都放在 osfmk 目录下。目前 MkLinux 社区也没什么声音了,最后一个发版本在 2002 年。
P.S. osfmk 就是 Open Software Foundation Mach Kernel 的缩写。
前面我们提到 CMU 开发 Mach 内核时嫌弃传统 UNIX 内核什么都干,过于臃肿。所以设计目标是要取代 UNIX,让 UNIX 跑在 Mach 内核的用户空间里。这个特性在 Mach 3.0 真正实现了。但是众所周知 Mach 内核并不提供文件系统和网络实现,所以依然需要和 UNIX 做大量的数据交换。这种交换的方式就是通过 Mach 的 IPC 通信。而让几乎所有进程都在两个空间之间做 IPC 通信是非常低效的。
所以 NEXTSTEP 系统修改了 Mach 内核的实现,让 Mach 和 BSD 都跑在同样的内核空间上,同时让用户空间发起的文件、网络请求等本来要通过 IPC 调用的接口都改成 system call。

1997 年 1 月份
是乔布斯回归后的第一次登台,讲了一堆苹果过去十年犯下的错误之后,宣布 Rhapsody 项目,很有救世主之风。 第一次演示了 Rhapsody 的 demo。在他登台之后,现场响起了绵延不绝的掌声。Rhapsody 基于 NeXT 的 OPENSTEP 开发,可以认为是 Mac OS X 的过渡产品。经过漫长的研发阶段,终于在 2000 年 12 月正式发布第一个 Public Beta 版。这期间大概的时间线是这样的:
其中在 1999 开始开源了系统的核心部分,名为 Darwin。其核心就来自 NEXTSTEP 的 XNU,也就是 Mach/BSD 混合内核。Mach 部分更新了 OSFMK 的 Mach 3.0 和部分来自 University of Utah 的 Mach 4 项目,BSD 部分更新了 FreeBSD 项目的代码。早期苹果甚至提供了 Darwin 安装包,可以作为一个独立系统安装到 x86 和 PowerPC 机器上。不过现在只开放源代码了。
2000 年乔布斯在 Macworld Expo 上首次介绍了 Mac OS X,演讲风格非常乔帮主,有兴趣的朋友可以看看:
严格来说现在我们接触到的 macOS 内核,官方叫做 Darwin,它的核心是 XNU,可以独立安装。严格意义上 XNU 和 Darwin 并不完全相等,较真地讲 XNU 只是 Mach/BSD 部分。在前面的文章里我基本上把 Darwin 和 XNU 当做同义词,这并不严谨。但是根据我的考证,目前 Darwin, XNU 和 macOS Kernel 基本等同于一个意思,只要读者朋友不会产生歧义即可。
使用 uname -a 可以查看自己的系统版本:
Darwin xxx.local 19.0.0 Darwin Kernel Version 19.0.0: Thu Oct 17 16:17:15 PDT 2019; root:xnu-6153.41.3~29/RELEASE_X86_64 x86_64
Mach 内核最初的设计是一个微内核,但是现在 Darwin 已经是一个什么都干的宏内核(Monolithic kernel)了。在看这段历史的时候颇有一种天下大势,分久必合,合久必分的感觉。想想从 1971 年第一个 Unix 版本到现在(2019 年)已经 48 年过去了,OS X 10.0 也过去 18 年了。2016 年,苹果在 WWDC 宣布 OS X 改名为 macOS。
风云变幻几十年,既有技术的发展也有商业的博弈,很多今天看起来完全看不懂的代码,都是当年历史遗留的未解之谜。XNU 代码里的注释,也有历史的痕迹:
/*
* Well-known UDP port, debugger side.
* FIXME: This is what the 68K guys use, but beats me how they chose it...
*/
#define KDP_REMOTE_PORT 41139 /* pick one and register it */
至少现在我终于明白,什么是 68K guys 了。XDDD

此前我们在macOS 内核之系统如何启动?提到内核作为一个巨大的 Mach-O 文件如何被加载到内存运行的,不过内核是被 BootLoader(iBoot) 加载的,入口 LC_UNIXTHREAD 也是 ASLR 应用之前的旧实现。
那么内核是如何运行起一个 App 的呢?
在开始之前我们先了解几个简单的背景知识:XNU 的 Process (进程)的组成是怎样的?
我们知道 Process 这个抽象概念是指一个 Program (程序)加上它所持有的 Resources (资源)。资源包括物理的 CPU 时间和内存,或者抽象的文件概念等等。
我们知道 XNU 内核主要由 BSD 和 Mach 两个部分组成,BSD 作为 Unix 内核提供了 Unix Process,Mach 内核则把 Process 抽象为 Task 和 Thread,所以在 macOS 上,一个进程既是 Mach Task 也是 BSD Process。不过内核中比较多的 IPC 是通过 Mach 来完成的。
Mach Task 的定义在 osfmk/kern/task.h,这个结构体非常大,持有 IPC space, memory address space, Mach threads, BSD info 等非常多进程相关信息。
我们在用户空间给自己的 App 新起线程的时候,无论是用 NSThread 还是其他上层接口,系统都用 pthread 接口实现了(POSIX Threads)。进入到内核空间,一个 pthread 对应的是一个 Mach Thread,结构体定义在 osfmk/kern/thread.h,就是 struct thread。机器相关的定义在 struct machine_thread,不同的架构各有一个实现。thread 带有 struct task *task; 信息指向对应的进程。这个 Mach Thread 里也包含了 BSD 的 uthread。
所以一个 pthread 既是 Mach thread 也是 Unix thread。所以内核在创建一个新进程的时候,就需要同时创建 Unix Process 和 Mach Task,以及他们需要的 threads, processors 等各种信息。
我们可以通过 sysctl 查看:
➜ sysctl -a | grep -i proc
kern.maxproc: 4176
内核也在 bsd/conf/param.c hardcoded 了数字 NPROC:
#if CONFIG_EMBEDDED #define NPROC 1000 /* Account for TOTAL_CORPSES_ALLOWED by making this slightly lower than we can. */ #define NPROC_PER_UID 950 #else #define NPROC (20 + 16 * 32) #define NPROC_PER_UID (NPROC/2) #endif
/* NOTE: maxproc and hard_maxproc values are subject to device specific scaling in bsd_scale_setup / #define HNPROC 2500 / based on thread_max */ int maxproc = NPROC;
fork() 与 exec()在传统的 Unix 系统中,fork() 是唯一用来创建新进程的方法,该方法将复刻一个当前进程的完整结构,包括二进制代码。所以负责启动其他 App 的进程为了能跑其他人的程序,还需要配合 exec() 方法,把 fork 出来的进程的 image 覆盖成新 App 的。
macOS 的 BSD 部分也提供了 fork() 方法,返回值是 pid_t,为 0 即表示当前跑在子进程,-1 是失败,其他就是父进程的 pid。参考 MTU 课程的一个示例代码:
#include <stdio.h> #include <sys/types.h>#define MAX_COUNT 200
void ChildProcess(void); /* child process prototype / void ParentProcess(void); / parent process prototype */
void main(void) { pid_t pid;
pid = fork(); if (pid == 0) ChildProcess(); else ParentProcess();}
void ChildProcess(void) { int i;
for (i = 1; i <= MAX_COUNT; i++) printf(" This line is from child, value = %d\n", i); printf(" *** Child process is done ***\n");}
void ParentProcess(void) { int i;
for (i = 1; i <= MAX_COUNT; i++) printf("This line is from parent, value = %d\n", i); printf("*** Parent is done ***\n");
}
BSD 提供的 exec() 方法有很多,可以参考这里:
execl, execlp, execle, exect, execv, execvp, execvP -- execute a file
但最终都会进入 execve() 系统调用,这是内核提供给用户空间用于打开其他程序的唯一接口。
fork()在进入内核实现之前,fork() 在用户空间还做了一大堆事情,这些是在 libSystem 里面实现的,源码可以在这里找到。
我们的示例代码在调用 fork() 函数之后,就会先进入 libSystem 调用 libSystem_atfork_prepare() 处理注册的 hooks,接下来如果是动态库就走 dyld 的 _dyld_fork_child() 方法,静态库就不走 dyld 了。(我找到了函数实现但是没有找到判断与调用的地方。)
在 dyld 43 版本还有对静态库的处理 _dyld_fork_parent() 但是最新的版本(655.1.1)已经只剩下 _dyld_fork_child() 了。
// Libsystem-1252.250.1
// init.c()
static const struct _libc_functions libc_funcs = {
.version = 1,
.atfork_prepare = libSystem_atfork_prepare,
.atfork_parent = libSystem_atfork_parent,
.atfork_child = libSystem_atfork_child,
};
接下来 libSystem, dyld 和 xnu 会有一系列复杂的互相调用。《Mac OS X Internals》书中介绍的版本比较旧,新的代码和书中所说的稍有不同,但是原理是差不多的。这一部分直接阅读源码比较困难,所以我选择放弃,直接阅读书里的结论就好。XD
大家可以到这里参考原文
void libSystem_atfork_child(void) { // first call hardwired fork child handlers for Libsystem components // in the order of library initalization above _dyld_fork_child(); _pthread_atfork_child(); _mach_fork_child(); _malloc_fork_child(); _libc_fork_child(); // _arc4_fork_child calls malloc dispatch_atfork_child(); #if defined(HAVE_SYSTEM_CORESERVICES) _libcoreservices_fork_child(); #endif _asl_fork_child(); _notify_fork_child(); xpc_atfork_child(); _libtrace_fork_child(); _libSC_info_fork_child();// second call client parent handlers registered with pthread_atfork() _pthread_atfork_child_handlers();
}
用户空间准备完了就开始进入内核的 fork() 函数了,实现在 bsd/kern/kern_fork.c:
int fork(proc_t parent_proc, __unused struct fork_args *uap, int32_t *retval)
返回值 0 为成功,其他就是错误码。
第一个参数 parent_proc 就是调用 fork 的那个 process,第二个参数 uap 已经弃置不用了,第三个参数就是返回的 pid。父进程会收到 hardcoded 的 0。
关键实现在 fork1() 函数:
int
fork1(proc_t parent_proc, thread_t *child_threadp, int kind, coalition_t *coalitions)
这个函数上来先取父进程的 thread 和 uthread,接着取当前用户 ID kauth_getruid(),也就是我们通过 ps 看到的当前进程由哪个用户创建的信息,我们在 shell 里经常需要 sudo 也就是切换成 root 身份来跑一个进程,这个权限就是通过 kauth 模块管理。
接下来判断当前进程数是否超限,没问题就继续。
count = chgproccnt(uid, 1);
这里把当前用户进程数 + 1,我想到内核启动的时候,也 hardcode 了一句 + 1 给 launchd 这个进程。接着会判断用户的进程数上限是否超限。
接下来是安全检查,判断当前用户是否有权限 fork 新的进程,没问题就开始 switch kind 了,一共有三种类型:
/* process creation arguments */
#define PROC_CREATE_FORK 0 /* independent child (running) */
#define PROC_CREATE_SPAWN 1 /* independent child (suspended) */
#define PROC_CREATE_VFORK 2 /* child borrows context */
其中 vfork() 是 fork() 的变种,大部分 Unix-like 系统都有这两种 fork,区别是 vfork 创建的子进程会 block 住父进程,一直等到子进程跑完 exit 然后父进程才会继续,fork 则不会,可自行编译运行我们上文的小 demo。
至于 spawn 则是给 posix_spawn() 用的,跟 fork() 类似,但是 fork 会继承(或者说复制)父进程的很多资源比如内存,而 spawn 不会。可以参考 Linxu 关于 POSIX Spawn 的文档,简单理解为是给那些性能比较低的设备(比如嵌入式设备)用的。
我们继续看 fork():
cloneproc() // 创建新的 Mach Task (task_t), Unix Process (proc_t) 以及 thread_
forkproc()
proc_t 然后把父进程的信息都塞给他pid 然后赋值给新的 proc_tinherit_memory 如果为 true,则 vm_map 也会 fork 一份,否则就是重新创建一个 vm_map 然后赋值。fork() 进来的为 true, posix_spawn() 为 false。fork_create_child() 创建新的线程 thread_tprocdup() 这个在书中有提但是新版内核已去掉thread_dup()
machine_thread_dup() 不同的架构各有实现,主要是复制了当前线程的寄存器信息,FPU 信息等硬件相关的上下文信息。task_clear_return_wait()
thread_wakeup()thread_wakeup_with_result()
```
#define thread_wakeup_with_result(x, z) \
thread_wakeup_prim((x), FALSE, (z))
```
thread_wakeup_prim()
书中曰最终会进入 thread_resume() 但是我又没找到从哪里进入的🤦♂️。
execve()实现在 bsd/kern/kern_exec.c,我们来个示例代码看看:
#include <stdio.h> #include <sys/types.h> #include <unistd.h> #include <stdlib.h> #include <errno.h> #include <sys/wait.h>int main() { pid_t pid; int status, died;
pid = fork(); if (pid == 0) { printf("%s\n", "parent"); } else { int ret = execve("/bin/date",0,0); printf("%d\n", ret); }
}
输出如下:
➜ ./a.out
parent
Wed Nov 6 18:55:45 CST 2019
可以看到子进程已经被 /bin/date 覆盖了。同样的,这个函数也有用户空间和内核空间实现,上面示例我们用的接口是 POSIX 定义的:
int execve(const char * __file, char * const * __argv, char * const * __envp);
接受文件路径参数,参数列表和环境参数。
到了内核这个函数则是:
// bsd/kern/kern_exec.c
int
execve(proc_t p, struct execve_args *uap, int32_t *retval)
p 是当前进程,uap 是用户空间传过来的参数,有三个:
uap->fname 文件名uap->argp 参数列表uap->envp 环境参数对应用户空间里我们传的三个参数。最后 retval 是给上层的返回值,函数自身返回 0 则成功。
该函数的主要实现在 __mac_execve()。
先组装一个 image_params 数据结构:
struct image_params { user_addr_t ip_user_fname; /* argument */ user_addr_t ip_user_argv; /* argument */ user_addr_t ip_user_envv; /* argument */ int ip_seg; /* segment for arguments */ struct vnode *ip_vp; /* file */ struct vnode_attr *ip_vattr; /* run file attributes */ struct vnode_attr *ip_origvattr; /* invocation file attributes */ cpu_type_t ip_origcputype; /* cputype of invocation file */ cpu_subtype_t ip_origcpusubtype; /* subtype of invocation file */ char *ip_vdata; /* file data (up to one page) */ int ip_flags; /* image flags */ int ip_argc; /* argument count */ int ip_envc; /* environment count */ int ip_applec; /* apple vector count */char *ip_startargv; /* argument vector beginning */ char *ip_endargv; /* end of argv/start of envv */ char *ip_endenvv; /* end of envv/start of applev */ char *ip_strings; /* base address for strings */ char *ip_strendp; /* current end pointer */ int ip_argspace; /* remaining space of NCARGS limit (argv+envv) */ int ip_strspace; /* remaining total string space */ user_size_t ip_arch_offset; /* subfile offset in ip_vp */ user_size_t ip_arch_size; /* subfile length in ip_vp */ char ip_interp_buffer[IMG_SHSIZE]; /* interpreter buffer space */ int ip_interp_sugid_fd; /* fd for sugid script */ /* Next two fields are for support of architecture translation... */ struct vfs_context *ip_vfs_context; /* VFS context */ struct nameidata *ip_ndp; /* current nameidata */ thread_t ip_new_thread; /* thread for spawn/vfork */ struct label *ip_execlabelp; /* label of the executable */ struct label *ip_scriptlabelp; /* label of the script */ struct vnode *ip_scriptvp; /* script */ unsigned int ip_csflags; /* code signing flags */ int ip_mac_return; /* return code from mac policy checks */ void *ip_px_sa; void *ip_px_sfa; void *ip_px_spa; void *ip_px_smpx; /* MAC-specific spawn attrs. */ void *ip_px_persona; /* persona args */ void *ip_cs_error; /* codesigning error reason */ uint64_t ip_dyld_fsid; uint64_t ip_dyld_fsobjid;
};
组装完了之后就 active 一下 image:
static int
exec_activate_image(struct image_params *imgp)
这个函数主要是分配内存,权限检查,通过 namei() 方法找到该二进制文件,使用 vn 接口(跟文件系统无关的抽象接口)读取文件头,最多读一页。
error = vn_rdwr(UIO_READ, imgp->ip_vp, imgp->ip_vdata, PAGE_SIZE, 0,
UIO_SYSSPACE, IO_NODELOCKED,
vfs_context_ucred(imgp->ip_vfs_context),
&resid, vfs_context_proc(imgp->ip_vfs_context));
读到文件头信息之后再循环走一遍,判断是否如下三种:
{ exec_mach_imgact, "Mach-o Binary" }, // 普通的单架构 Mach-o 二进制文件
{ exec_fat_imgact, "Fat Binary" }, // 多架构 Mach-o 二进制文件
{ exec_shell_imgact, "Interpreter Script" }, // 脚本
找到了就使用对应 imgact 转成函数指针然后调用它,传入 imgp 参数。
error = (*execsw[i].ex_imgact)(imgp);
我们直接看 exec_mach_imgact():
static int
exec_mach_imgact(struct image_params *imgp)
这个函数最重要的地方是:
lret = load_machfile(imgp, mach_header, thread, &map, &load_result);
load_machfile() 实现在 bsd/kern/mach_loader.c 里面。负责分配物理内存和虚拟内存,如果有 ASLR (就是内存 offset 加个随机偏移,默认开)就随机一下,然后解析 Mach-o 文件,根据 Mach-o 文件的 load commands 信息把二进制数据装进内存。
其中用到了 parse_machfile() 方法处理 Mach-o 文件里的 load commands。我们知道有了 ASLR 之后大家的入口都从 LC_UNIXTHREAD 变成了 LC_MAIN。这个方法就把这些信息都保存到 load_result_t 里面然后返回, load_result_t 里包含了 threadstate,里面就有 entry_point 信息。
load mach file 结束后 activate_exec_state()
static int
activate_exec_state(task_t task, proc_t p, thread_t thread, load_result_t *result)
这个函数会调用 thread_setentrypoint() 把之前函数入口 entry_point 地址塞进 eip 寄存器于是函数就愉快地被调用了。
thread_setentrypoint(thread, result->entry_point);
// i386 实现
#define CAST_DOWN_EXPLICIT( type, addr ) ( ((type)((uintptr_t) (addr))) )
/*
-
thread_setentrypoint:
-
-
Sets the user PC into the machine
dependent thread state info.
*/
void
thread_setentrypoint(thread_t thread, mach_vm_address_t entry)
{
pal_register_cache_state(thread, DIRTY);
if (thread_is_64bit_addr(thread)) {
x86_saved_state64_t *iss64;
iss64 = USER_REGS64(thread);
iss64->isf.rip = (uint64_t)entry;
} else {
x86_saved_state32_t *iss32;
iss32 = USER_REGS32(thread);
iss32->eip = CAST_DOWN_EXPLICIT(unsigned int, entry);
}
}
这里涉及 i386 架构的寄存器设计,以底下的 32 位为例,eip 就是 PC 寄存器(Program Counter Register)。
#define REG_PC EIP
#define REG_FP EBP
#define REG_SP UESP
#define REG_PS EFL
#define REG_R0 EAX
#define REG_R1 EDX
在 i386 或曰 x86 架构里面,这个寄存器就是下一个指令会访问到的内存地址。于是我们将它设置为函数入口,该函数就开始了。
LC_MAIN 的 entryoff有了 ASLR 之后入口地址不再是静态的偏移量而是每次都会随机一下。如果是以前的入口在 LC_UNIXTHREAD 的,这时候取 entry point 就直接赋值。
但是 LC_MAIN 入口的却会传给 LC_LOAD_DYLINKER 段里面指定使用的 dyld。由于 Release App 基本都会去掉 debugging symbol 放进 dSYM,方便起见我们直接看我的 Debug 版的 Just Focus for Mac:
Load command 11
cmd LC_MAIN
cmdsize 24
entryoff 535536
stacksize 0
entryoff 这个偏移量是基于文件初始位置的。
535536 转成 hex 就是 0x000082BF0,再加上 macOS 上的基准地址 0x100000000 就是 0x100082BF0。方便起见我们直接用 MachOView 来看看 (__TEXT,__text) 段里的数据
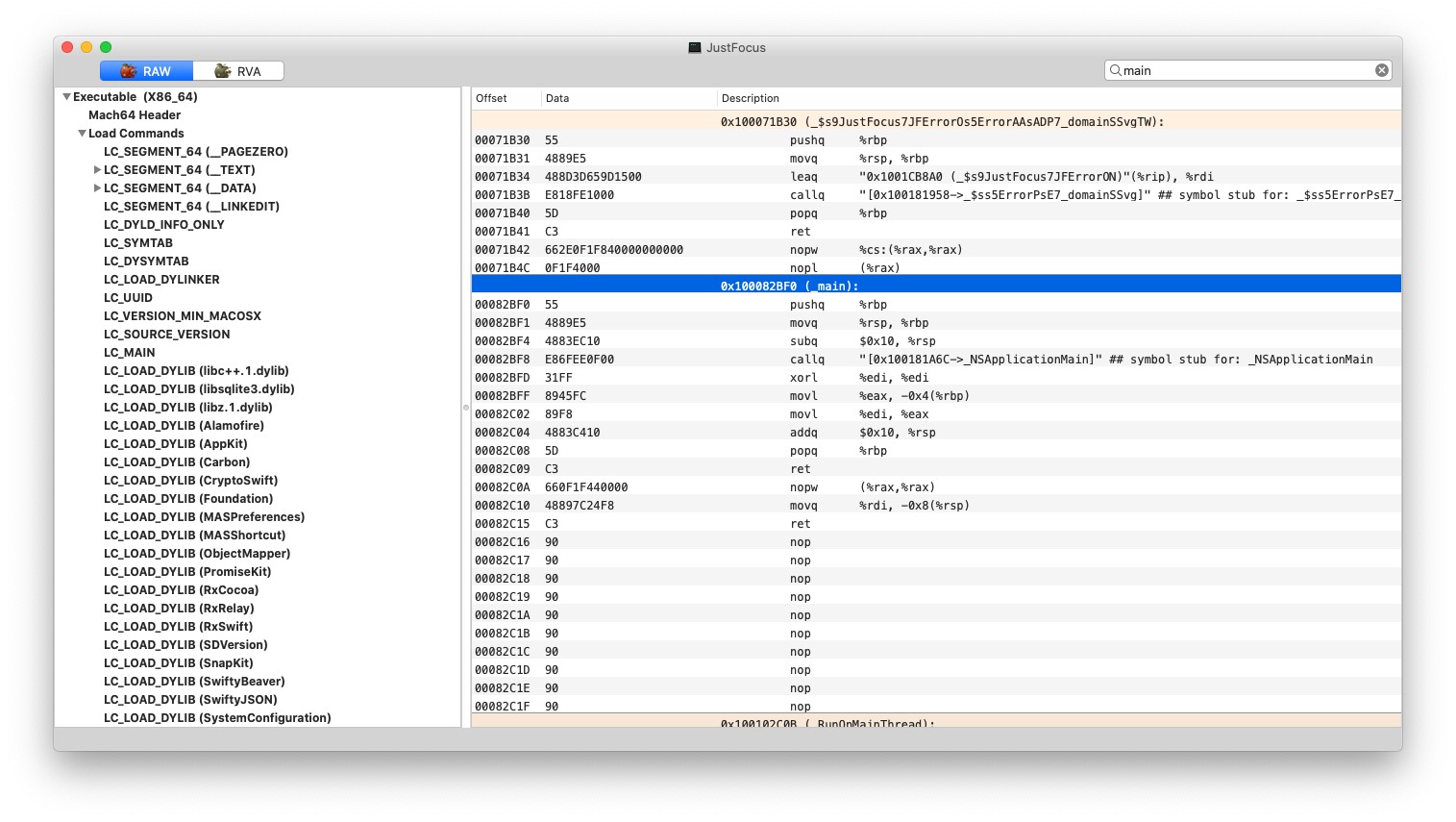
可以看到这里就是我们的 _main() 函数入口。当然这些数值都是静态的,当 App 被加入内存时,内核会计算偏移量所以运行时的地址还得再加上那个偏移量。
接下来 parser_machinefile() 就会去调用 load_dylinker(),初始化一些 dylddata 然后又回去调用 parse_machinefile() 一次。这一次,parse 的不是别人,而是 LC_LOAD_DYLINKER 里指定的 dyld,比如上面的 /usr/lib/dyld。
这个家伙当然不用 LC_MAIN 而是 LC_UNIXTHREAD 啦:
Load command 12
cmd LC_UNIXTHREAD
cmdsize 184
flavor x86_THREAD_STATE64
count x86_THREAD_STATE64_COUNT
rax 0x0000000000000000 rbx 0x0000000000000000 rcx 0x0000000000000000
rdx 0x0000000000000000 rdi 0x0000000000000000 rsi 0x0000000000000000
rbp 0x0000000000000000 rsp 0x0000000000000000 r8 0x0000000000000000
r9 0x0000000000000000 r10 0x0000000000000000 r11 0x0000000000000000
r12 0x0000000000000000 r13 0x0000000000000000 r14 0x0000000000000000
r15 0x0000000000000000 rip 0x0000000000001000
rflags 0x0000000000000000 cs 0x0000000000000000 fs 0x0000000000000000
于是设置好 entry point,通过 dyld 起飞!
内核的 fork() 和 exec() 任务到给 thread 设置 entry point 之后就结束了。至于为什么往寄存器里塞一个函数指针地址它就开始跑起来,那就涉及到汇编,CPU 如何执行指令了。阮一峰的科普文章《汇编语言入门教程》写得很浅显易懂可以参考一下。
接下来我们切换到 dyld 的源码。dyld 在模拟器和真机上有不同的启动入口:
// configs/dyld.xcconfig
ENTRY[sdk=simulator] = -Wl,-e,_start_sim ENTRY[sdk=iphoneos*] = -Wl,-e,__dyld_start ENTRY[sdk=macosx*] = -Wl,-e,__dyld_start
入口函数的实现是汇编,在 dyldStartup.s 文件。我们可以搜索关键词 call:
// i386 实现 .text .align 4, 0x90 .globl __dyld_start __dyld_start: popl %edx # edx = mh of app pushl $0 # push a zero for debugger end of frames marker movl %esp,%ebp # pointer to base of kernel frame andl $-16,%esp # force SSE alignment subl $32,%esp # room for locals and outgoing parameterscall L__dyld_start_picbaseL__dyld_start_picbase:
popl %ebx # set %ebx to runtime value of picbasemovl Lmh-L__dyld_start_picbase(%ebx), %ecx # ecx = prefered load address movl __dyld_start_static_picbase-L__dyld_start_picbase(%ebx), %eax subl %eax, %ebx # ebx = slide = L__dyld_start_picbase - [__dyld_start_static_picbase] addl %ebx, %ecx # ecx = actual load address # call dyldbootstrap::start(app_mh, argc, argv, slide, dyld_mh, &startGlue) movl %edx,(%esp) # param1 = app_mh movl 4(%ebp),%eax movl %eax,4(%esp) # param2 = argc lea 8(%ebp),%eax movl %eax,8(%esp) # param3 = argv movl %ebx,12(%esp) # param4 = slide movl %ecx,16(%esp) # param5 = actual load address lea 28(%esp),%eax movl %eax,20(%esp) # param6 = &startGlue call __ZN13dyldbootstrap5startEPK12macho_headeriPPKclS2_Pm movl 28(%esp),%edx cmpl $0,%edx jne Lnew # clean up stack and jump to "start" in main executable movl %ebp,%esp # restore the unaligned stack pointer addl $4,%esp # remove debugger end frame marker movl $0,%ebp # restore ebp back to zero jmp *%eax # jump to the entry point # LC_MAIN case, set up stack for call to main()
Lnew: movl 4(%ebp),%ebx movl %ebx,(%esp) # main param1 = argc leal 8(%ebp),%ecx movl %ecx,4(%esp) # main param2 = argv leal 0x4(%ecx,%ebx,4),%ebx movl %ebx,8(%esp) # main param3 = env
所以在我们的 App 的函数入口被调用之前,dyldbootstrap::start(app_mh, argc, argv, slide, dyld_mh, &startGlue)函数会先被调用,它的返回值是真正 App 的函数入口,比如说 main()。
uintptr_t start(const struct macho_header* appsMachHeader, int argc, const char* argv[],
intptr_t slide, const struct macho_header* dyldsMachHeader,
uintptr_t* startGlue)
这个函数调用了 dyld::_main() 这个函数才是重点,上面不同架构的汇编都会进这里,只是参数各有不同。这个函数会 load 所有的动态库 image,初始化,最后再拿到真正的 App 入口,然后返回。最后汇编代码里就会 jmp 到 App 入口,于是 App 就愉快地启动了。
如果你在 Activity Monitor App 里选中一个进程,点左上角的感叹号,你可以看到当前进程的 Parent Process。然后你就会发现基本上所有你通过 Finder, Launchpad 之类的方式启动的 App(命令行的 open 也是),它们的 parent process 都是 launchd (当然 App 自行创建的子进程就不是,比如 Google Chrome Helper)。在 iOS 的 Crash Log 里,App 的 parent process 也是 launchd。
在 macOS 上我们可以使用系统提供的 Launch Service 来启动其他 App,最终也是由 launchd 来完成 fork() 和 execve()。
launchd 的 parent process 是 kernel_task。kernel_task 进程就是内核进程本程了,在内核启动时自行创建,实现在 bsd/kern/bsd_init.c 的 bsd_init(void) 函数。
launchd 是 Mac OS X Tiger 10.4 开始引入的特性,在 Kernel 启动时创建,然后它负责创建其他系统守护进程(Daemons),也负责创建系统登录界面。
还有另一个服务是 launchctl,可以跟 launchd 进行 IPC 通信,经常被用来做开机启动任务。LaunchControl.app 就是非常好的 launchctl/launchd 图形界面。
Unix 的 fork() 和 execve() 方法在上学的时候学校曾经教过。但是一则当时的讲解还比较偏高级抽象,二则年代久远已经记不太清了,所以回顾学习这一段的时候还是费了点力气去了解诸如汇编、寄存器之类的概念。Apple 开源的代码还是很多的,除了内核,大量的系统服务也都开源了,非常有助学习。最近学习内核代码,一边看代码一边跟着书本理解,总让我有一种“源码在手,天下我有”的错觉。XD

经过前两篇提到的尝试之后,终于来到 BPF 了。由于 nstat 在内核中定义为私有接口,所以它的数据虽然现成,用起来却一点也不简单。那么有没有更厉害一点的方法呢?
朋友听说我在学习这方面的技术,于是推荐了一个关键词: BPF。我们知道抓包界有一个大名鼎鼎的工具叫做 tcpdump,它的核心原理就是使用了 BPF 技术(基于 pcap 接口)。
我阅读了 1992 年 BPF 发表的论文,顺带发现了
的 PDF,才知道原来 TCPDump 是 Steve McCanne 1988 年在加州大学伯克利分校选修编译器课程的时候,跟其他同学一起做的,BPF 可以看做是当时他们做tcpdump 时顺手开发的。有点像我们上大学时老师要求做的大作业,只不过人家的大作业是改变世界的大作业😂。
当时 Steve 和同学组成一个四个人的 Research Group:
其中 Steve McCanne 和 Van Jacobson 负责网络抓包的部分(他们俩也是论文的作者)。他们开始用 Sun 的抓包工具但是用起来非常抓狂,于是他们决定写一个自己的工具,也就是后来的 tcpdump。其中跑在 Unix 内核的部分就是 BPF,Berkeley Packet Filter 的缩写,最后于 1992 年 12 月发表论文。
Packet Filter 这种技术是为了网络监控程序设计的,我们知道内核空间与用户空间的虚拟内存实现不同,如果要从内核传递数据到用户空间需要经过地址空间转换,还要 copy 数据,是一种比较耗时的操作。(这里 Unix 和 Linux 的虚拟内存实现还不一样,我尚未仔细学习,目前只知道操作耗时。)
为了减少 copy 操作,早期有些 Unix 系统提供了包过滤技术,比如 CMU/Stanford Packet Filter。BPF 论文发表的时候称性能比 Sun's NIT 快 100 倍,吊打所有对手。这篇论文并不长有兴趣的读者可以看一下: The BSD Packet Filter: A New Architecture for User-level Packet Capture
根据我的阅读理解,Packet Filter 技术应该都会提供 pseudo-machine (伪代码虚拟机)把 bytecode (字节码)转为机器码,也就是虚拟机,著名的虚拟机比如 Java 的 JVM,把源码转成 .class 的字节码然后每个平台各自跑个虚拟机从而实现跨平台。BPF 的操作也是通过 bytecode 编写。FreeBSD, NetBSD 都提供了 JIT 编译器给 BPF,Linux 也有不过默认是关的。
由于 BPF 设计的时候摒弃了以前 Packet Filter 基于栈设计(Stack based)的虚拟机的做法(比如 JVM 就是),改为使用基于寄存器(Register based)设计的虚拟机,充分利用了当时还算新技术的 CPU RISC (精简指令集)的优势。(题外: RISC 的发明者 David Patterson 也是加州大学伯克利分校的)
另外 BPF 还做了一个看似非常小的改进:在内核层接到 device interface 丢过来的包时就进行 filter,不需要的包直接丢弃,不会多出任何无效 copy。从而比旧时代的技术有着显著的性能优势。论文中他们还提到 BPF 的多项优化细节,这里不再赘述,有兴趣的读者可自行阅读论文。
总而言之 BPF 技术提供了一个原始接口,可以获取 Data Link Level (数据链路层)的数据包,并且支持数据包过滤,由于采用虚拟机在内核层直接执行 bytecode,所以过滤逻辑实际上跑在内核层,性能十分优越。在 OSI 模型中,Link Level 是最接近物理层的了,在这一层抓包当然是最王道的选择啦。
P.S. 系统内核是没必要走 Packet Filter 的,这个技术是给用户空间的 App 用的,内核本来就有所有数据包,所以 nstat 不会用到这些技术。
如第一节所说,bpf 在内核层实现了一个可以执行 bpf 字节码的虚拟机,所以理论上我们可以裸写 bpf 指令,跟写汇编差不多。XNU 的 BSD 部分实现了 bpf,需要引入头文件:
#import <net/bpf.h>
以下是 BPF program 示例代码(来自 Mac OS X Internals):
int installFilter(int fd, unsigned char Protocol, unsigned short Port) { struct bpf_program bpfProgram = {0};/* Dump IPv4 packets matching Protocol and (for IPv4) Port only */ /* @param: fd - Open /dev/bpfX handle. */ const int IPHeaderOffset = 6 + 6 + 2; /* 14 */ /* Assuming Ethernet (DLT_EN10MB) frames, We have: * * Ethernet header = 14 = 6 (dest) + 6 (src) + 2 (ethertype) * Ethertype is 8-bits (BFP_P) at offset 12 * IP header len is at offset 14 of frame (lower 4 bytes). * We use BPF_MSH to isolate field and multiply by 4 * IP fragment data is 16-bits (BFP_H) at offset 6 of IP header, 20 from frame * IP protocol field is 8-bts (BFP_B) at offset 9 of IP header, 23 from frame * TCP source port is right after IP header (HLEN*4 bytes from IP header) * TCP destination port is two bytes later * * Note Port offset assumes that this Protocol == IPPROTO_TCP! * If it isn't, adapting this to UDP port is left as an exercise to the reader, * as is extending this to support IPv6, as well.. */struct bpf_insn insns[] = {
/* Uncomment this line to accept all packets (skip all checks) */ // BPF_STMT(BPF_RET + BPF_K, (u_int)-1), // Return -1 (packet accepted)
BPF_STMT(BPF_LD + BPF_H + BPF_ABS, 6+6), // Load ethertype 16-bits from 12 (6+6) BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, ETHERTYPE_IP, 0, 10), // Test Ethertype or jump(10) to reject BPF_STMT(BPF_LD + BPF_B + BPF_ABS, 23), // Load protocol (= IP Header + 9 bytes) BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K , Protocol, 0, 8), // Test Protocol or jump(8) to reject BPF_STMT(BPF_LD + BPF_H + BPF_ABS, IPHeaderOffset+6),// Load fragment offset field BPF_JUMP(BPF_JMP + BPF_JSET+ BPF_K , 0x1fff, 6, 0), // Reject (jump 6) if more fragments BPF_STMT(BPF_LDX + BPF_B + BPF_MSH, IPHeaderOffset), // Load IP Header Len (x4), into BPF_IND BPF_STMT(BPF_LD + BPF_H + BPF_IND, IPHeaderOffset), // Skip hdrlen bytes, load TCP src BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K , Port, 2, 0), // Test src port, jump to "port" if true
/* If we're still here, we know it's an IPv4, unfragmented, TCP packet, but source port
- doesn't match - maybe destination port does? */
BPF_STMT(BPF_LD + BPF_H + BPF_IND, IPHeaderOffset+2), // Skip two more bytes, to load TCP dest /* port / BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K , Port, 0, 1), // If port matches, ok. Else reject / ok: / BPF_STMT(BPF_RET + BPF_K, (u_int)-1), // Return -1 (packet accepted) / reject: */ BPF_STMT(BPF_RET + BPF_K, 0) // Return 0 (packet rejected) };
先初始化一个 bpf_program 结构体:
struct bpf_program { u_int bf_len; struct bpf_insn *bf_insns; };
struct bpf_insn { u_short code; u_char jt; u_char jf; bpf_u_int32 k; };
然后编写指令 bpf_insn,看上去像写汇编一样差不多(虽然我不会)。
除了写 *pcap 的人之外,在 Unix 上,一般开发者都用 bpf 作者写的 libpacp 封装来操作 bpf。我在 macOS 10.15 Catalina (19A583) 上用 libpcap 实现了一个简单的抓包逻辑,我们可以看一下去掉错误处理的关键代码:
// 创建一个 bpf_program struct bpf_program fp;// 找一下 device interface char *dev = pcap_lookupdev(errbuf);
// 获取 IP 和 netmask bpf_u_int32 mask; bpf_u_int32 net; pcap_lookupnet(dev, &net, &mask, errbuf);
// 打开一个 pcap session pcap_t *handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
我们看下这个函数原型:
pcap_t *pcap_open_live(char *device, int snaplen, int promisc, int to_ms,
char *ebuf)
第一个参数 device 就是 pcap_lookupdev 拿到的 device 了,第二个 snaplen 是 pcap 可以捕获的最大长度,这里填 stdio.h 定义的值 BUFSIZ,也就是 1024 bytes(官网教程说的是 pcap.h 有但是我没找到,只在 stdio.h 里找到了)。
第三个参数 promisc 是 promiscuous mode 是否打开。promiscuous mode 中文翻译为混杂模式,没打开的时候我们只能获取目标地址为该 interface 的包,打开了之后经过它的包也可以被我们抓到。
第四个参数 to_ms 是设置超时时间,以 ms 为单位,填 0 就是不设置超时。
最后一个参数 ebuf 就是错误信息返回了。传入 char *errbuf[PCAP_ERRBUF_SIZE]; 就行。
上一篇我们讲过 PPP 和 Ethernet 包有所不同,如果你只想处理 Ethernet 包的话你可以通过 pcap_datalink() 接口判断 link-layer header。
if (pcap_datalink(handle) != DLT_EN10MB) {
fprintf(stderr, "Device %s doesn't provide Ethernet headers - not supported\n", dev);
return(2);
}
前面说过 bpf_program 里都是存的字节码指令,所以我们得编译一下:
char filter_exp[] = "port 23";
pcap_compile(handle, &fp, filter_exp, 0, net)
最后把 filter 设置好:
pcap_setfilter(handle, &fp)
然后我们就可以愉快地抓包了。使用 pcap_next() 可以获得一个 filter 过的包。
/* Grab a packet */
packet = pcap_next(handle, &header);
/* Print its length */
printf("Jacked a packet with length of [%d]\n", header.len);
/* And close the session */
pcap_close(handle);
完整示例可以参考 tcpdump 官网的这篇文章: Programming with pcap
一般情况下我们不会只抓一个包,我们可以用 pcap_loop() 来循环抓包:
int pcap_loop(pcap_t *p, int cnt, pcap_handler callback, u_char *user)
第一个参数就是上面创建的 handle 了,第二个参数 cnt 是说抓了多少个包之后回调给你。第三个函数 pcap_handler 就是你的回调函数,最后一个是上下文参数,透传的。
回调函数 pcap_handler 的原型如下:
typedef void (*pcap_handler)(u_char *arg, const struct pcap_pkthdr *, const u_char *packet);
第一个参数 arg 就是 pcap_loop() 注册时最后一个上下文参数,你自己传的。
第二个参数 pcap_pkthdr 是 pcap 包头,第三个参数 packet 就是网络包啦,解析这两个参数我们就能获得包信息。
struct pcap_pkthdr {
struct timeval ts; time stamp
bpf_u_int32 caplen; length of portion present
bpf_u_int32; lebgth this packet (off wire)
}
因为前面可以设置抓包阈值,所以包本身的时间放在 pcap_pkthdr 里面。
我们只关心外网 IP 包,不关心 ARP 包,另外 PPP 先不处理,所以过滤一下:
if (ntohs (eptr->ether_type) == ETHERTYPE_IP) {}
然后可以打印出来了:
int i; u_char *ptr; /* printing out hardware header info */ /* copied from Steven's UNP */ ptr = eptr->ether_dhost; i = ETHER_ADDR_LEN; printf(" Destination Address: "); do{ printf("%s%x",(i == ETHER_ADDR_LEN) ? " " : ":",*ptr++); }while(--i>0); printf("\n");
ptr = eptr->ether_shost; i = ETHER_ADDR_LEN; printf(" Source Address: "); do{ printf("%s%x",(i == ETHER_ADDR_LEN) ? " " : ":",*ptr++); }while(--i>0); printf("\n");
输出结果:
Ethernet type hex:800 dec:2048 is an IP packet
Destination Address: 0:0:c:7:ac:ec
Source Address: dc:a9:4:77:9c:41
Ethernet type hex:800 dec:2048 is an IP packet
Destination Address: 0:0:c:7:ac:ec
Source Address: dc:a9:4:77:9c:41
这样,所有的 IP packet 的 Mac 地址都被我们打印出来了。如果我想打印 IPv4 地址,以及 TCP 协议的端口呢?
TCP 是 IP 上层的协议,如果我们要抓 TCP 的包我们可以判断一下 IP packet 里的 protocol number。不过在那之前,我们要先从 packet 里面解出 IP 信息和 TCP 信息。我们参考一下整个包的内存结构:
| Variable | Location (in bytes) |
|---|---|
| Ethernet | x |
| IP | x + SIZE_ETHERNET |
| TCP | x + SIZE_ETHERNET + {IP header length} |
| payload | x + SIZE_ETHERNET + {IP header length} + {TCP header length} |
// 原型可见 bsd/netinet/ip.h
// 这里参考 https://www.tcpdump.org/pcap.html
struct sniff_ip {
#ifdef _IP_VHL
u_char ip_vhl; /* version << 4 | header length >> 2 */
#else
#if BYTE_ORDER == LITTLE_ENDIAN
u_int ip_hl:4, /* header length */
ip_v:4; /* version */
#endif
#if BYTE_ORDER == BIG_ENDIAN
u_int ip_v:4, /* version */
ip_hl:4; /* header length */
#endif
#endif /* not _IP_VHL */
u_char ip_tos; /* type of service */
u_short ip_len; /* total length */
u_short ip_id; /* identification */
u_short ip_off; /* fragment offset field */
#define IP_RF 0x8000 /* reserved fragment flag */
#define IP_DF 0x4000 /* dont fragment flag */
#define IP_MF 0x2000 /* more fragments flag */
#define IP_OFFMASK 0x1fff /* mask for fragmenting bits */
u_char ip_ttl; /* time to live */
u_char ip_p; /* protocol */
u_short ip_sum; /* checksum */
struct in_addr ip_src,ip_dst; /* source and dest address */
};
出于学习目的我们只看 Ethernet 包,Ethernet 包的包头规定是 14 byets,所以我们偏移 14 bytes 就能得到包体。
#define SIZE_ETHERNET 14
ip = (struct sniff_ip*)(packet + SIZE_ETHERNET);
IP 协议的规定比较复杂,他的 ip header 长度不是固定的,而是 4 字节长度的 word 的个数。
#define IP_HL(ip) (((ip)->ip_vhl) & 0x0f)
ip = (struct sniff_ip*)(packet + SIZE_ETHERNET); size_ip = IP_HL(ip)*4;
TCP header 也不是定长的,同样也是取 4 字节 word 长度的个数。
tcp = (struct sniff_tcp*)(packet + SIZE_ETHERNET + size_ip); size_tcp = TH_OFF(tcp)*4;
// 剩下的就是 payload 了 payload = (u_char *)(packet + SIZE_ETHERNET + size_ip + size_tcp);
fprintf(stdout,"IP: %s", inet_ntoa(ip->ip_src)); fprintf(stdout,"Port: %s", ntohs(tcp->th_sport));
fprintf(stdout,"IP: %s", inet_ntoa(ip->ip_dst)); fprintf(stdout,"Port: %s", ntohs(tcp->th_dport));
这样我们就获得所有 TCP 包的数据了。
这里使用 ntohs() 进行转换是因为网络层的 byte order 和 host (CPU 架构)的不一样,network byte order 是用大端(big-endian),host 则根据 CPU 架构来,从 Mac OS X 支持 i386 开始就是小端了(little-endian)。所以必须把内存里的数据转换一下才能得到正确的数值。
inet_ntoa() 则是把 network byte order 的结构体 in_addr 转换成一个 IPv4 的 string。
以上是如何使用 pcap() 接口抓包。由于我们在 link level 抓的包全都是 packet 数据,可以承载 TCP/UDP, IP/ARP, Ethernet/PPP 等多种非常"原始"的数据,所以处理起来非常感人。
作为学习之用我觉得挺好的,要付诸生产环境还需要不少功夫。
这些 packet 包本身是不带进程信息 pid 的,如果我们要把这些包跟进程关联到一起就还需要额外的处理。一种解决方法是根据每个 TCP 连接中系统给分配的 port,从系统调用反查该 port 对应的进程。但是有可能当我们去查询的时候这个连接已经断开了(虽然讲道理 bpf 截获数据包比真正接包的应用还早,但我们可以设置回调间隔,所以不一定),所以也不一定靠谱。我本来也研究了一下如何从系统获取所有 process 和对应分配的 port,但是很笨地跟上面那一堆 pcap 代码一起忘记 commit 了。所以我重新学习了一遍 pcap 使用,但是不想再去尝试 process 获取 port 了 XD。
网络层是我目前学习内核遇到最复杂的一部分,涉及的知识点太多,接口非常古老,缺乏文档,需要好好理解上述代码如何处理 packet 的话,我还得阅读 RFC 对 TCP/UDP/IP 等协议的规定。所以我选择了放弃,还是学点其他的知识好了。
在阅读 BPF 论文的时候,也对这些能做出厉害东西的程序员十分叹服。同时也觉得有些时候我们认为一些技术非常神秘难懂,觉得非常黑科技,但如果能有源码可读,能有论文可辅助,其实原理并不是很难。难的是发明这些技术的人,不仅能理解和掌握这么复杂的技术,而且能把这些离散的点连接起来创造出厉害的东西。

书接上回,我们讨论了如何使用 Unix 的 sysctl()接口以及 Unix Domain Socket 来获取系统 network interface 的流量信息。
我们是从 Activity Monitor.app 开始的,这个 App 不仅能显示整体网卡的流量,还能分进程显示。这回我们还是在 macOS 上实验,看看有没有方法也跟他一样实现进程流量监控。
先说结论: 以我的微末道行,暂未发现靠谱且简单实现方案。有简单的,不靠谱;有靠谱的,不简单。😂
希望知道简单靠谱方案的读者朋友可以分享一下。
使用 otool -l 我们可以看到 Activity Monitor.app 用了一个私有的系统库:
/System/Library/PrivateFrameworks/NetworkStatistics.framework/Versions/A/NetworkStatistics
这个库同时也用在了 macOS 的 nettop 命令上。所以如果我们直接调用这个库的 API 那就非常省时省力了。
使用 class-dump 把它的头文件 dump 出来:
class-dump /System/Library/PrivateFrameworks/NetworkStatistics.framework/Versions/A/NetworkStatistics
@interface NWStatisticsManager : NSObject
{}
- (BOOL)addAllUDP:(unsigned long long)arg1;
(BOOL)addAllTCP:(unsigned long long)arg1;
这个可疑的类和接口想必就是我们要寻找的答案了。接下来就是凭经验观察接口猜想看看这些接口怎么用了。我实验过可以非常轻松地获得进程 pid,进程名字 processName,和对应的 rxBytes, rtBytes。
首先,把 dump 出来的头文件引入自己的工程,同时把 NetworkStatistics.framework 加入 Link Binary With Libraries 列表。这一步比较简单各位可以自行 Google。
我们以 TCP 为例看看如何使用它的接口:
NWStatisticsManager *mgr = [[NWStatisticsManager alloc] init];
mgr.delegate = self;
[mgr addAllTCP:0];
加完 source 之后会通过回调告诉你所有的 TCP 连接的建立和销毁:
@protocol NWStatisticsManagerDelegate <NSObject>
@optional
- (void)statisticsManager:(NWStatisticsManager *)arg1 didReceiveDirectSystemInformation:(NSDictionary *)arg2;
- (void)statisticsManager:(NWStatisticsManager *)arg1 didRemoveSource:(NWStatisticsSource *)arg2;
(void)statisticsManager:(NWStatisticsManager *)arg1 didAddSource:(NWStatisticsSource *)arg2;
@end
我们获得 NWStatisticsSource 之后要加入它的 delegate 等待回调:
- (void)sourceDidReceiveCounts:(NWStatisticsSource *)arg1 { NWStatisticsTCPSource *tcp = (NWStatisticsTCPSource *)arg1; NWSTCPSnapshot *snapshot = [tcp currentSnapshot];NSLog(@"NWStatisticsManager rx: %llu", snapshot.rxBytes); NSLog(@"NWStatisticsManager tx: %llu", snapshot.txBytes); NSLog(@"NWStatisticsManager processName: %@", snapshot.processName); NSLog(@"NWStatisticsManager processID: %d", snapshot.processID);
}
有数据变化的时候这个回调会被 called 我们就可以愉快地获取各个进程的 tx/rx 数据了,不仅有 bytes, 还有 packets 数据。
但是正如前文所述,此法简单,却不靠谱。
NWStatisticsManager 作为一个非常上层的接口,经常变更。比如旧版本的接口就是 C 风格的:
void *NStatManagerCreate(CFAllocatorRef allocator, dispatch_queue_t queue, void (^)(void *)); void NStatManagerDestroy(void *manager);void NStatSourceSetRemovedBlock(void *source, void (^)()); void NStatSourceSetCountsBlock(void *source, void (^)(CFDictionaryRef)); void NStatSourceSetDescriptionBlock(void *source, void (^)(CFDictionaryRef));
void NStatManagerAddAllTCP(void *manager); void NStatManagerAddAllUDP(void *manager);
有兴趣的朋友可以参考这里: *OS Internals::User Space
接口变更就意味着一旦系统升级我们的代码就得跟着改,而且是从头猜一遍他的接口应该怎么用。又由于里面的实现是黑盒的,我们的猜想不一定对,所以很容易出现用错接口和 Crash。
留意到 NetworkStatistics.framework 里面用到的数据结构有 nstat_msg_hdr,据此我们猜测他用了内核的 nstat.h 里的接口。既然上层接口经常改,那么内核接口即使改应该也不会太频繁吧?直接上 nstat 可乎?
先说结论:相对比较靠谱,但是非常不简单。
我们需要的很多数据在内核代码里也被标记为 PRIVATE:
#define PRIVATE
这些私有的数据结构和 API 都不会公开到 Xcode 能引用的头文件里,比如说最重要的文件 ntstat.h 整个都是 private。所以为了让 Xcode 能编译通过,我们得把这个头文件手动 copy 过来,附带的还有 tcp.h, in_stat.h, net_api_stats.h 等多个文件。
跟上一篇讲 ppp connect 一样,我们需要创建一个 socket 跟内核进行 IPC 通信,不过这次不是用户空间的 AF_LOCAL 而是系统的 AF_SYSTEM/PF_SYSTEM。这是 Darwin XNU 专有的一种 Protocol Family,其他 Unix 系统并未实现。用于用户态的进程请求内核态进程的数据。
对于 PF_SYSTEM 类型的 socket,XNU 提供了两种协议,分别是: SYSPROTO_EVENT 和 SYSPROTO_CONTROL。详情可参考: http://newosxbook.com/bonus/vol1ch16.html
SYSPROTO_EVENT 用于监听内核提供的事件,通过 kev_request 传参,创建后 WiFi 切换、扫描事件,IP 地址更新等各种事件都会通过 socket 消息通知过来。
SYSPROTO_CONTROL 这个就是我们要找的主角了。这个 sockect 给用户空间和 XNU 内核空间的 providers 进程提供了控制通道,一般在 kernel extension 用的比较多,用户空间的 App 几乎没用到。并且,接口全部没有文档。
SYSPROTO_CONTROL 的 providers 用反域名作为 ID,一般都是 Apple 自己的代码,所以是 com.apple 开头,NetworkStatistics.framework 用到的 provider 叫做 com.apple.network.statistics。
我们需要使用 ioctl() 接口跟这个家伙通信,我们常用的 ifconfig 命令也是通过这个方法。
由于根本没有文档,所以如何创建并连接上这个东西就非常困难,对着 XNU 的 ntstat 实现代码看半天也没用,因为他是通过 ioctl 模块通信的。好在 Apple Open Source 有开源 netstat 的代码,我们可以通过它的代码学习一下,删掉错误处理之后代码如下:
struct sockaddr_ctl sc; struct ctl_info ctl; int fd; // 创建一个 PF_SYSTEM socket, protocol 为 SYSPROTO_CONTROL,用于 ioctl() 函数 fd = socket(PF_SYSTEM, SOCK_DGRAM, SYSPROTO_CONTROL);/* Get the control ID for statistics */ bzero(&ctl, sizeof(ctl)); strlcpy(ctl.ctl_name, NET_STAT_CONTROL_NAME, sizeof(ctl.ctl_name)); // 创建完 socket 之后要先调用 ioctl 获取 ctl_info,我们需要里面的 ctl_id 才能连接 socket ioctl(fd, CTLIOCGINFO, &ctl)
/* Connect to the statistics control / bzero(&sc, sizeof(sc)); sc.sc_len = sizeof(sc); sc.sc_family = AF_SYSTEM; sc.ss_sysaddr = SYSPROTO_CONTROL; sc.sc_id = ctl.ctl_id; sc.sc_unit = 0; // 连接 socket connect(fd, (struct sockaddr)&sc, sc.sc_len)
/* Set socket to non-blocking operation */ // 使用 fcntl() 函数把 socket 读取设置为非阻塞读取 fcntl(fd, F_SETFL, fcntl(fd, F_GETFL, 0) | O_NONBLOCK)
如此就成功创建了一个跟 "com.apple.network.statistics" 通信的 socket 了。
接下来要发送 add source 请求,跟上面使用 NWStatisticsManager 的时候差不多。netstat的源码是发一个 NSTAT_PROVIDER_IFNET 类型的请求:
nstat_msg_add_src_req *addreq; nstat_msg_src_added *addedmsg; nstat_ifnet_add_param *param; char buffer[sizeof(*addreq) + sizeof(*param)]; ssize_t result; const u_int32_t addreqsize = offsetof(struct nstat_msg_add_src, param) + sizeof(*param);/* Setup the add source request */ addreq = (nstat_msg_add_src_req )buffer; param = (nstat_ifnet_add_param)addreq->param; bzero(addreq, addreqsize); addreq->hdr.context = (uintptr_t)&buffer; addreq->hdr.type = NSTAT_MSG_TYPE_ADD_SRC; // 操作是 add source addreq->provider = NSTAT_PROVIDER_IFNET; // 关注的是 ifnet,还可以关注 TCP/UDP 等多个 provider bzero(param, sizeof(*param)); param->ifindex = ifparam->ifindex; param->threshold = ifparam->threshold;
/* Send the add source request */ result = send(fd, addreq, addreqsize, 0);
发送后收到的请求如下:
addedmsg = (nstat_msg_src_added *)buffer; result = recv(fd, addedmsg, sizeof(buffer), 0);// addedmsg->hdr.type == NSTAT_MSG_TYPE_SRC_ADDED
// 这里我们收到了一个 source 指针,发送NSTAT_MSG_TYPE_GET_SRC_DESC请求时需要用到这个指针 outsrc = addedmsg->srcref;
检查 interface 状态的部分我们就不看了,也是一样发个请求收个消息,我们直接看 src descriptor 的。
nstat_msg_get_src_description *dreq; nstat_msg_src_description *drsp; char buffer[sizeof(*drsp) + sizeof(*ifdesc)]; ssize_t result; const u_int32_t descsize = offsetof(struct nstat_msg_src_description, data) + sizeof(nstat_ifnet_descriptor);dreq = (nstat_msg_get_src_description *)buffer; bzero(dreq, sizeof(*dreq)); dreq->hdr.type = NSTAT_MSG_TYPE_GET_SRC_DESC; dreq->srcref = srcref; // 这个就是刚才上一步收到的 source 指针 result = send(fd, dreq, sizeof(*dreq), 0);
// 这里接收到 nstat_msg_src_description 了 drsp = (nstat_msg_src_description *)buffer; result = recv(fd, drsp, sizeof(buffer), 0);
// link_status_type 还可以判断是 WiFi 还是 cellular // ifdesc.link_status.link_status_type == NSTAT_IFNET_DESC_LINK_STATUS_TYPE_WIFI
最后把 WiFi 信息打印一下:
en0: 17:38:02 interface state:
wifi status: link_quality_metric: 0 ul_effective_bandwidth: 6695 ul_max_bandwidth: 237641040 ul_min_latency: -1 ul_effective_latency: 0 ul_max_latency: 0 ul_retxt_level: 4(high) ul_bytes_lost: -1 ul_error_rate: 0 dl_effective_bandwidth: 2955 dl_max_bandwidth: 237641040 dl_min_latency: -1 dl_effective_latency: 0 dl_max_latency: 0 dl_error_rate: 8533 config_frequency: 2 config_multicast_rate: -1 scan_count: -1 scan_duration: -1
netstat 命令没有打印所有进程信息,但是如果我们阅读 XNU 源码,这个 provider 支持返回 nstat_tcp_descriptor 这种数据,里面可是带了 pid 的。我们可以试着获取 TCP Descriptor 看看。
这里我还是只能靠经验瞎猜,同时阅读 XNU 关于 ntstat 的实现代码,没有特别好的方法。如果读者朋友有比较聪明的方法请分享一下,非常需要😂。
我们看到 nstat_tcp_descriptor 这个数据的 copy 在 nstat_tcp_copy_descriptor() 函数,这个函数的指针被赋值给 nstat_tcp_provider.nstat_copy_descriptor。所以我们需要这个 tcp_provider 给我们这些信息。
所以我们猜测,先添加 tcp provider source,然后进行再获取他的 src description 就能获得这些数据。实验核心代码如下:
nstat_msg_add_all_srcs *addreq;char buffer[sizeof(*addreq)]; ssize_t result; const u_int32_t addreqsize = sizeof(struct nstat_msg_add_all_srcs);
/* Setup the add source request */ addreq = (nstat_msg_add_all_srcs *)buffer; bzero(addreq, addreqsize); addreq->hdr.length = sizeof(nstat_msg_add_all_srcs); addreq->hdr.context = 3; // 随便填 addreq->hdr.type = NSTAT_MSG_TYPE_ADD_ALL_SRCS; // 所有 sources addreq->provider = NSTAT_PROVIDER_TCP_KERNEL;
result = send(fd, addreq, addreqsize, 0);
一开始填 NSTAT_MSG_TYPE_SYSINFO_COUNTS 这个最大值,我一直收到 error。且确认就是在 nstat_control_begin_query() 函数里返回的 EAGAIN 错误码:
// man 2 intro | less -Ip EAGAIN
35 EAGAIN Resource temporarily unavailable. This is a temporary condi-
tion and later calls to the same routine may complete normally.
正准备放弃的时候,看到 libnstat 这个用 C++ 实现的库在这里填的参数是 2。他的头文件定义是 NSTAT_PROVIDER_TCP = 2 但我看到的 XNU 头文件却把内核空间与用户空间分开了:
enum
{
NSTAT_PROVIDER_NONE = 0
,NSTAT_PROVIDER_ROUTE = 1
,NSTAT_PROVIDER_TCP_KERNEL = 2
,NSTAT_PROVIDER_TCP_USERLAND = 3
,NSTAT_PROVIDER_UDP_KERNEL = 4
,NSTAT_PROVIDER_UDP_USERLAND = 5
,NSTAT_PROVIDER_IFNET = 6
,NSTAT_PROVIDER_SYSINFO = 7
};
换成 NSTAT_PROVIDER_TCP_KERNEL 之后能成功连接上 socket,但是 get src description 却返回错误的数据。本想继续研究但是看到 libnstat 项目里针对不同版本的内核也用了不同的头文件和 cpp 实现,说明 Apple 对这部分代码的修改也还算比较频繁的。目前我使用的系统版本是 macOS Catalina 10.15 (19A583),xnu 版本是: 6153.11.26~2。libnstat 项目准备了 5 个不同版本的 nstat.h 文件,他的项目里最新的是 xnu-4570.1.46。所以有理由猜想是内核又更新了这部分代码,不过无论如何,到这一步已经可以证明结论:
使用 nstat.h 的接口,不仅非常复杂,而且也不靠谱。
没想到 nstat 相关的内容也这么复杂,学习起来还是挺费劲的。本章我们通过 class-dump 私有库 NetworkStatistics.framework 的头文件接口,凭经验猜测和实验,用上了这个相对上层的接口,实现了网络包统计。
接着我们尝试往下一层,通过 ioctl() 接口,使用 PF_SYSTEM 这种 XNU 独有的 socket 跟内核通信,从 com.apple.network.statistics 这个 provider 那里读取网络统计信息。
但是这两种方法首先都使用到系统的私有方法,并且这两个东西历史上都有过比较大的 API 变动。framework 的接口好猜但变化频繁,nstat 的接口变化稍微少一点但是几乎没有文档,学习起来非常痛苦。
总而言之就是这两个方法都不靠谱,那么有没有其他更有意思的方法呢?下一篇我们来试试 BPF (Berkeley Packet Filter)。
P.S. 传 req 的时候我发现仅存可供参考的代码都没有传 hdr.length,同时内核代码有一段注释,说为了兼容旧版 client 的实现,拿到 hdr.length 如果为空就补刀一下。所以是内核本来为了兼容旧版的补刀逻辑让现在新实现的人都不填 length 了。😂

可以说这个世界有了网络之后,重新了计算机。网络是目前所有 PC 和手机设备不可或缺的东西。同时飞速发展的互联网行业也让这一层的技术更迭迅速,衍生出无数计算机网络技术。
由于涉及的概念和技术点太多,所以一时半会我也不知从何学起,看到 Activity Monitor.app 的 Network 一项系统能够统计的数据挺多的,不如就试试做拿跟他一样的信息看看。
讲道理我们的 App 和系统自带的 App 都是跑在用户空间的,大家用的 API 也差不多,他能做到我们也能做到对吧。
事实证明我还是太天真了😂。
有学过计算机网络的朋友应该都听说过 OSI Model(Open Systems Interconnection model),把计算机网络分为七层:
| # | Layer |
|---|---|
| 7 | Application (应用层, HTTP) |
| 6 | Presentation (表现层, HTTP) |
| 5 | Session (会话层, HTTP) |
| 4 | Transport (传输层, TCP) |
| 3 | Network (网络层, IP) |
| 2 | Data link (链路层, Frames) |
| 1 | Physical (物理层,Bits) |
这是 ISO 提出的逻辑分层标准,好处是分层隔离之后,各层的技术自行更新时不会影响到其他层的逻辑,比如最底层的 Physical Layer (物理层)发展到现在的万兆光纤,它只需要关心 Bits 怎么传输就行,上层的逻辑几乎不需要更新。
但是人们实现这个分层标准的时候也并不完全按照分层来,比如最上面的几层,应用层(Application Layer)提供面向用户的协议比如 HTTP,其中数据压缩本来是表现层(Presentation Layer)的事情但是 HTTP 支持 Compression。然后 TLS/SSL 在传输层但是它支持加解密。
实际上 TCP/IP Model (Internet protocol suite) 的四层模型比 OSI 七层简化了一些,也相对比较贴近大家的使用习惯。
| # | Layer |
|---|---|
| 4 | Application Layer (应用层, HTTP/ IMAP…) |
| 3 | Transport Layer (传输层, TCP/UDP…) |
| 2 | Internet Layer (网络层, IP/ICMP…) |
| 1 | Link Layer (链路层, MAC/PPP…) |
以 OSI 七层模型来看,XNU 内核负责的主要是第 2 到第 5 层, TCP/IP 模型则是 1 到 3 层(我们熟悉的 URLSession 是上层提供的,不在内核实现)。
第 2 层里 XNU 提供了网络相关的 interface。如果在终端运行 ifconfig 的话大家会看到一堆信息,以 en0, lo0 开头的。这些是 device interface names,对应了物理或者虚拟网卡,这些设备不在 /dev 里表现,用户空间如果要访问它们就必须通过 Unix domain socket 进行通信(有别于 IP socket,下文将有描述)。
所以如果我们要统计一台机器的网络流量,我们可以通过获取主要网卡的流量信息来解决。
开源的系统监控软件 GKrellM 项目在 macOS 上的实现就是通过 sysctl() 获取网卡数据来统计网络流量,实现入口在 src/sysdeps/bsd-common.c 里的 void gkrellm_sys_net_read_data(void) 函数。
我们在本 macOS 内核系列的第一篇有提到过利用 sysctl() 函数可以从内核获取很多有用的系统信息,同时系统也提供了 sysctl 命令可以在终端运行。sysctl 基本上是所有类 Unix 系统的标准命令之一。在 XNU 内核中,sysctl以及网络相关的接口由 BSD 内核实现。
另一个非常常见的命令是 ifconfig,运行它可以获取我们所有网卡(network interface)信息。ifconfig 的代码是开源的可以在这里找到。
系统内核会维护一份以树形 MIB (management information base)形式存储的数据,里面包含了硬件信息、网络统计信息等一大堆数据,sysctl 接口会读取 MIB 数据然后返回。我们也可以通过别的接口来获取这些数据(下文将有介绍),但是 sysctl 接口很方便也很快。
sysctl的 MIB 存储划分为多种类型,内存 vm, 网络 net, 硬件 hw 之类的。可以通过 sysctl -A 命令打出来。
sysctl 不仅可以读数据,也可以写数据。该函数原型 XNU 没有注释,我们(可以参考这里)在 Linux 上的定义:
int sysctl (int *name,
int nlen,
void *oldval,
size_t *oldlenp,
void *newval,
size_t newlen);
name: 一个整数的数组,里面是查询参数nlen: 第一个参数里有多少个整数oldval: 存储的数据通过这个指针返回,有可能为 NULLoldlenp: 存储的数据的长度newval: 用该参数写入新数据到 MIB,传 NULL 则不修改newlen: 新数据的长度在 GKrellM 里获取网卡信息的实现分为两步,第一步先取数据长度 oldlenp:
static int mib_net[] = { CTL_NET, PF_ROUTE, 0, 0, NET_RT_IFLIST, 0 }; static char *buf; static int alloc; size_t needed;
if (sysctl(mib_net, 6, NULL, &needed, NULL, 0) < 0) return;
第二步,取到长度之后分配一个足够长的内存然后正式读数据:
if (alloc < needed) { if (buf != NULL) free(buf); buf = malloc(needed); if (buf == NULL) return; alloc = needed; }
if (sysctl(mib_net, 6, buf, &needed, NULL, 0) < 0) return;
net 前缀在宏定义里是 CTL_NET。
PF_ROUTE 是路由表相关的操作。前缀 PF_ 是 Protocol Family 的意思,对应的还有 AF_ Address Family。在 XNU 里,PF_ 和 AF_ 的定义是完全一样的(Linux 也是)。
前面说跟 interface 打交道得通过 Unix domain socket(跟 IP socket 稍有不同),要创建 一个 Unix domain socket,第一个参数就是 Protocol Famil。我们知道 XNU 包含了 Mach 内核和 FreeBSD 内核,它本身最常用的 IPC 方式是 Mach 内核提供的 Mach Port 方式,BSD 提供的这种 socket 方式其实比较少见。
BSD 中创建 socket 使用 socket() 函数:
int socket (int family, int type, int protocol);
第一个参数是 family,指的其实是 Protocol Family,也就是 PF_ 开头的参数,但实际上我们可以用 AF_ 来代替,这是一个历史遗留产物。在的书中提到:
(This PF_INET thing is a close relative of the AF_INET that you can use when initializing the sin_family field in your struct sockaddr_in. In fact, they’re so closely related that they actually have the same value, and many programmers will call socket() and pass AF_INET as the first argument instead of PF_INET. Now, get some milk and cookies, because it’s time for a story. Once upon a time, a long time ago, it was thought that maybe an address family (what the “AF” in “AF_INET” stands for) might support several protocols that were referred to by their protocol family (what the “PF” in “PF_INET” stands for). That didn’t happen. And they all lived happily ever after, The End. So the most correct thing to do is to use AF_INET in your struct sockaddr_in and PF_INET in your call to socket().)
大意是说以前大家曾经试图在 socket 上抽象出一个 Protocol Family 的概念,允许一个 Address Family 支持多种协议。但是这件事情一直没人实现过😂,所以遗留了这么个东西。Unix 和 Linux 的定义都是直接把 PF_ 开头的宏定义为同名的 AF_ 宏。
第二个参数是 socket 类型:
/*
* Types
*/
#define SOCK_STREAM 1 /* stream socket */
#define SOCK_DGRAM 2 /* datagram socket */
#define SOCK_RAW 3 /* raw-protocol interface */
#if !defined(_POSIX_C_SOURCE) || defined(_DARWIN_C_SOURCE)
#define SOCK_RDM 4 /* reliably-delivered message */
#endif /* (!_POSIX_C_SOURCE || _DARWIN_C_SOURCE) */
#define SOCK_SEQPACKET 5 /* sequenced packet stream */
第三个是协议类型,比如 UDP, TCP:
// bsd/netinet/in.h
#define IPPROTO_UDP 17 /* user datagram protocol / #define IPPROTO_TCP 6 / tcp */
bsd/netinet/in.h 里还定义了上百个,我已放弃学习🤦♂️。
在 IPv4 网络中,第一个参数我们传 PF_INET,IP 地址会保存在 sockaddr_in 结构体中:
struct sockaddr_in {
short sin_family;
u_short sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
IPv6 则是 PF_INET6,XNU 的相关定义在 bsd/netinet/in.h。
PF_ROUTE 获取的是系统路由表相关的信息,XNU 没什么文档,但是这是一个 BSD 标准,所以我们可以参考 NetBSD 关于网络的文档。BSD 中关于路由表的实现分为三个部分,以 Radix Tree (基数树)存储的数据库 net/radix.c,提供查询和修改接口的 net/route.c,以及提供给上层的 socket 接口 net/rtsock.c。系统的 route(8) 命令有用到 PF_ROUTE,可以到 Apple Open Source 找到源码。
在用户空间,我们和路由表的交互都是通过 protocol family 为 PF_ROUTE 的 socket 来跟 network interface 通信的。
BSD 的 Network Routing 层负责转发数据包 packet 到目标网关,涉及到 ARP 解析(也就是 IP 地址与 Mac 地址的映射)。比如说一个 TCP/IP 协议的包到了路由这一层,就会根据 IP 地址寻找到目标网卡,把包发过去,比如发到 WiFi 网卡。所以我们可以通过路由这一层获得某一个网卡上所有的收发包数据,从而实现流量监控。
我们通过 sysctl() 接口获取信息的时候,这个 socket 是由内核创建的,我们只需要传参数就行。可以参考 FreeBSD 关于 sysctl(3) 的文档。
static int mib_net[] = { CTL_NET, PF_ROUTE, 0, 0, NET_RT_IFLIST, 0 };
留意到这里其实传了六个参数,CTL_NET 和 PF_ROUTE 已经解释过了。第三参数 0 是 hardcoded 的,以前留给 Protocol Family 的。第四个是 Address Family,这里填 0 可以表示获取所有 Family。第五个和第六个是有关联的,具体参考 FreeBSD 文档,我们只要知道传 NET_RT_IFLIST 时后面一个传 0。
最近阅读内核代码,碰到这种有历史的 C 接口感觉都非常依赖文档,如果没有文档几乎寸步难行。T_T
The NET_RT_IFLISTL is like NET_RT_IFLIST, just returning message
header structs with additional fields allowing the interface to
be extended without breaking binary compatibility.The NET_RT_IFLISTL uses 'l' versions of the message header struc-
tures: struct if_msghdrl and struct ifa_msghdrl.
根据文档,NET_RT_IFLIST 会返回 message header structs,用的是这个结构体 if_msghdr。
struct if_msghdr {
u_short ifm_msglen; /* to skip over non-understood messages */
u_char ifm_version; /* future binary compatibility */
u_char ifm_type; /* message type */
int ifm_addrs; /* like rtm_addrs */
int ifm_flags; /* value of if_flags */
u_short ifm_index; /* index for associated ifp */
struct if_data ifm_data; /* statistics and other data about if */
};
sysctl 返回的是一个数组,包含多个 if_msghdr 结构体,ifm_msglen 用于指针偏移量。我们可以通过一个循环来取每个 message header。
struct if_msghdr *ifmsg = (struct if_msghdr *)currentData;
if (ifmsg->ifm_type != RTM_IFINFO) {
currentData += ifmsg->ifm_msglen;
continue;
}
这里只关心 RTM_IFINFO 这种类型,相关定义还有十几个,在 bsd/net/route.h 的 RTM_ 开头的宏。
if (ifmsg->ifm_flags & IFF_LOOPBACK) {
currentData += ifmsg->ifm_msglen;
continue;
}
我们只关心真正和互联网通信的 interface,所以过滤本地 loopback 网络。这里我们可以简单理解包含了 localhost 的特殊网卡(可以参考这里),如果你在终端运行 ifconfig 看到 lo 开头的就是 loopback interface。
struct sockaddr_dl *sdl = (struct sockaddr_dl *)(ifmsg + 1);
if (sdl->sdl_family != AF_LINK) {
currentData += ifmsg->ifm_msglen;
continue;
}
把 ifmsg 这个 if_msghdr + 1 我们得到 Header 之后的内存地址,也就是 sockaddr_dl 数据,这个数据是 Link-Level sockaddr。我们先取 sdl_family,如果是 AF_LINK 就说明我们的结构体取对了。这里取得 sockaddr_dl 之后, sdl_data 的前 sdl_nlen 长度的数据就是他的名字,后面的是 ll address。
/*
* Structure of a Link-Level sockaddr:
*/
struct sockaddr_dl {
u_char sdl_len; /* Total length of sockaddr */
u_char sdl_family; /* AF_LINK */
u_short sdl_index; /* if != 0, system given index for interface */
u_char sdl_type; /* interface type */
u_char sdl_nlen; /* interface name length, no trailing 0 reqd. */
u_char sdl_alen; /* link level address length */
u_char sdl_slen; /* link layer selector length */
char sdl_data[12]; /* minimum work area, can be larger;
* contains both if name and ll address */
#ifndef __APPLE__
/* For TokenRing */
u_short sdl_rcf; /* source routing control */
u_short sdl_route[16]; /* source routing information */
#endif
};
我们直接读 sdl_data 里 sdl_nlen 这么长的数据,得到 interface name:
NSString *interfaceName = [[NSString alloc] initWithBytes:sdl->sdl_data length:sdl->sdl_nlen encoding:NSASCIIStringEncoding];
接下来检查这个 interface 有没有在跑:
if (ifmsg->ifm_flags & IFF_UP)
然后就可以读 ifmsg 的 if_data 数据了:
/*
* Structure describing information about an interface
* which may be of interest to management entities.
*/
struct if_data {
/* generic interface information */
u_char ifi_type; /* ethernet, tokenring, etc */
u_char ifi_typelen; /* Length of frame type id */
u_char ifi_physical; /* e.g., AUI, Thinnet, 10base-T, etc */
u_char ifi_addrlen; /* media address length */
u_char ifi_hdrlen; /* media header length */
u_char ifi_recvquota; /* polling quota for receive intrs */
u_char ifi_xmitquota; /* polling quota for xmit intrs */
u_char ifi_unused1; /* for future use */
u_int32_t ifi_mtu; /* maximum transmission unit */
u_int32_t ifi_metric; /* routing metric (external only) */
u_int32_t ifi_baudrate; /* linespeed */
/* volatile statistics */
u_int32_t ifi_ipackets; /* packets received on interface */
u_int32_t ifi_ierrors; /* input errors on interface */
u_int32_t ifi_opackets; /* packets sent on interface */
u_int32_t ifi_oerrors; /* output errors on interface */
u_int32_t ifi_collisions; /* collisions on csma interfaces */
u_int32_t ifi_ibytes; /* total number of octets received */
u_int32_t ifi_obytes; /* total number of octets sent */
u_int32_t ifi_imcasts; /* packets received via multicast */
u_int32_t ifi_omcasts; /* packets sent via multicast */
u_int32_t ifi_iqdrops; /* dropped on input, this interface */
u_int32_t ifi_noproto; /* destined for unsupported protocol */
u_int32_t ifi_recvtiming; /* usec spent receiving when timing */
u_int32_t ifi_xmittiming; /* usec spent xmitting when timing */
struct IF_DATA_TIMEVAL ifi_lastchange; /* time of last administrative change */
u_int32_t ifi_unused2; /* used to be the default_proto */
u_int32_t ifi_hwassist; /* HW offload capabilities */
u_int32_t ifi_reserved1; /* for future use */
u_int32_t ifi_reserved2; /* for future use */
};
我们只统计流量所以只关心这两个数值:
u_int32_t ifi_ibytes; /* total number of octets received */
u_int32_t ifi_obytes; /* total number of octets sent */
跟获取 CPU 信息的原理差不多,上面的数据是一个累计数值,但是我们要计算的是一个瞬时速率,所以得获取两次数据作比较。
这里 ifi_ibytes 和 ifi_obytes 使用 u_int32_t 存的,但是内核在计算这个数值的时候会一直累加,也就是说这个数据会 overflow (溢出)。计数增长的方法在 XNU 源码的 bsd/net/kip_interface.c 里面:
if (s->bytes_in != 0)
atomic_add_64(&ifp->if_data.ifi_ibytes, s->bytes_in);
所以如果我们要计算数据累加量的话,要自己处理这个 u_int32_t 的大小变化,如果发现保存的上一次的 ifi_ibytes 大于新的数值,说明新的数值已经溢出变小了。
P.S. 所有的网络监控软件都无法统计到历史数据,只能统计他开始监控那一刻起的数据。系统内核因为是第一个启动的,所以它能统计到的数据一定比我们多。
以上的处理是针对非 PPP 连接的 interface 的数据处理,PPP interface 比较麻烦,需要自建 socket 跟 interface 通信。在开始 PPP 连接处理之前,我们先岔开看看 interface naming。
留意到在 macOS 上运行 ifconfig 和在 Linux 上看到的 interface 命名规则有点不同:
# macOS lo0: … gif0: … stf0: … en0: … en1: … bridge0: … p2p0: … awdl0: … llw0: … utun0: … utun1: …Ubuntu
eth0: … lo0: …
interface 命名规则是由操作系统自己实现的,BSD 和 Linux 各有自己的规则。早期的 Linux 系统会只有 eth[0123…],根据内核启动时发现这些硬件的序号来命名。后来才加了 Consistent Network Device Naming feature。
在 Unix 系统上,这些 interface 会根据不同的类别有不同的前缀,《Mac OS X and iOS Internals》这本书的 Chap 17,Layer II: INTERFACES 对此命名规则有过介绍。大家可以参考看看。
主要分为两大类,一类是 XNU 原生支持的 interfaces,比如 bridge 和 lo。另一类是通过 Kernel Extension 支持的 interfaces,比如 en 和 ppp。
en 的支持在 IONetworkingFamily kext 里,对应的是 Ethernet (以太网)标准,在我的 MacBook 上 en0 是无线网卡,如果接上有线网卡会多出来一个 en1,前缀是类型,后缀数字区分不同硬件。
ppp 在 PPP kext 里,支持 PPP 点对点协议。平时我们最常见到这个协议的应用就是 PPPoE (Point-to-Point Protocol over Ethernet) 了,这个协议主要是在 Ethernet 协议上加了一层身份认证和传输加密,这样电信运营商才可以知道你的帐号,判断你有没有交钱。如果你的机器通过 WiFi 连接到家里的路由器,那么我们只管看 en interface 的数据就好,但是你也有可能直接通过你的 Mac PPPoE 拨号上网,那就得统计 PPP 端口了。
PPP interface 的数据处理起来比较麻烦,sysctl() 并没有直接返回数据,我们得另起一个 UNIX domain socket 跟它进行 IPC 通信(参考 MenuMeters的实现)。
UNIX domain socket 跟现在常见的 IP socket 不一样,不过接口差不多。UNIX domain socket 是 UNIX 独有的 IPC 通信方式,出现比 IP socket 还在,它可以用本地文件系统的路径作为 socket 地址(虽然不是真的文件,大部分都在 /var/run 里面),可以直接通过 socket 传文件。当然 Mach Port 也可以传 file descriptor,我们之前的文章也有介绍过。不过Mach Port 和这种特殊 socket 都不是 POSIX 标准。
// PPP local socket path #define kPPPSocketPath "/var/run/pppconfd\0"
pppconfdSocket = socket(AF_LOCAL, SOCK_STREAM, 0); struct sockaddr_un socketaddr = { 0, AF_LOCAL, kPPPSocketPath }; if (connect(pppconfdSocket, (struct sockaddr *)&socketaddr, (socklen_t)sizeof(socketaddr))) { NSLog(@"MenuMeterNetPPP unable to establish socket for pppconfd. Abort."); return nil; }
首先创建一个 UNIX domain socket,然后连接到 pppconfd:
int pppconfdSocket = socket(AF_LOCAL, SOCK_STREAM, 0);
struct sockaddr_un socketaddr = { 0, AF_LOCAL, kPPPSocketPath };
if (connect(pppconfdSocket, (struct sockaddr *)&socketaddr, (socklen_t)sizeof(socketaddr))) {
NSLog(@"MenuMeterNetPPP unable to establish socket for pppconfd. Abort.");
return nil;
}
AF_LOCAL 就是 UNIX domain socket 类型,这种类型的 socket 只支持 SOCK_STREAM + TCP 或者 SOCK_DGRAM + UDP,所以第三个参数可以不传。接下来通过 connect 函数连接两个 socket。
// Create the filehandle
pppconfdHandle = [[NSFileHandle alloc] initWithFileDescriptor:pppconfdSocket];
if (!pppconfdHandle) {
NSLog(@"MenuMeterNetPPP unable to establish file handle for pppconfd. Abort.");
return nil;
}
ObjC 的 NSFileHandle 可以来做 socket 通信,一个 writeData: 一个 readDataOfLength: 一发已收。
- (NSData *)pppconfdExecMessage:(NSData *)message {// Write the data [pppconfdHandle writeData:message]; // Read back the reply headers NSData *header = [pppconfdHandle readDataOfLength:sizeof(struct ppp_msg_hdr)]; if ([header length]) { struct ppp_msg_hdr *header_message = (struct ppp_msg_hdr *)[header bytes]; if (header_message && header_message->m_len) { NSData *reply = [pppconfdHandle readDataOfLength:header_message->m_len]; if ([reply length] && !header_message->m_result) { return reply; } } } // Get here we got nothing return nil;
} // pppconfdExecMessage
接下来先查一下 interface status,我们跟 pppconfd 发一个 PPP 消息:
struct msg { struct ppp_msg_hdr hdr; unsigned char data[MAXDATASIZE]; };/* PPP message paquets */ struct ppp_msg_hdr { u_int16_t m_flags; // special flags u_int16_t m_type; // type of the message u_int32_t m_result; // error code of notification message u_int32_t m_cookie; // user param u_int32_t m_link; // link for this message u_int32_t m_len; // len of the following data };
struct ppp_msg { u_int16_t m_flags; // special flags u_int16_t m_type; // type of the message u_int32_t m_result; // error code of notification message u_int32_t m_cookie; // user param, or error num for event u_int32_t m_link; // link for this message u_int32_t m_len; // len of the following data u_char m_data[1]; // msg data sent or received };
PPP 的实现不在 XNU 内核范围内,但也是开源的,可以到这里下载源码。可以看到不管是 struct msg 还是 struct ppp_msg 他的内存布局都是一样的,前面是 header 后面是数据。
看到我们跟 PPP 通信需要带一个 m_link 参数,因为 PPP 协议是基于 link 进行数据传输的。PPP 协议主要由三个部分组成:
其中 LCP 协议规定了 PPP 端口通过 link 传输。并且,PPP 协议支持一点对多点通信,这也是为什么我们家里的宽带有可能通过多拨实现带宽翻倍的原因。多连接协议称为 Multi-Link PPPoE (MLPPP)。
所以要跟 pppconfd 通信前我们还需要先拿到当前的 link:
// Get the link id for the interface
struct ppp_msg_hdr idMsg = { 0, PPP_GETLINKBYIFNAME, 0, 0, -1, (u_int32_t)[ifnameData length] };
NSMutableData *idMsgData = [NSMutableData dataWithBytes:&idMsg length:sizeof(idMsg)];
[idMsgData appendData:ifnameData];
NSData *idReply = [self pppconfdExecMessage:idMsgData];
uint32_t linkID = 0;
if ([idReply length] != sizeof(uint32_t)) return nil;
[idReply getBytes:&linkID];
传入 message type PPP_GETLINKBYIFNAME,带一个 ifname 表示对应的 interface。PPP 源码中对应的实现在这个函数:
static
void socket_getlinkbyifname(struct client *client, struct msg *msg, void **reply)
非常简单,遍历所有端口匹配一下然后 copy 信息返回。
这个函数里的实现用到一个 bytes 转换函数叫做 htonl(),因为 host byte order 和 network byte order 的排序不一样。上层几乎不需要管,但是在后续使用 bpf/pcap 抓包实现的时候就需要自己手动转换这些数据了。
获得 linkID 之后就可以问 PPP 要这条 link 的收发包数据了:
// Now get status of that link
struct ppp_msg_hdr statusMsg = { 0, PPP_STATUS, 0, 0, linkID, 0 };
NSData *statusReply = [self pppconfdExecMessage:[NSData dataWithBytes:&statusMsg length:sizeof(statusMsg)]];
if ([statusReply length] != sizeof(struct ppp_status)) return nil;
struct ppp_status *pppStatus = (struct ppp_status *)[statusReply bytes];
if (pppStatus->status == PPP_RUNNING) {
// pppStatus->s.run.inBytes
// pppStatus->s.run.outBytes
// pppStatus->s.run.timeElapsed
// pppStatus->s.run.timeRemaining
}
数据处理跟上面非 PPP Connection 的一样, PPP_STATUS 在 PPP 源码中对应的实现在:
static
void socket_status(struct client *client, struct msg *msg, void **reply)
本来网络抓包的学习除了通过 sysctl() 接口和 pppconfd 的 socket 通信之外,我还尝试了 NetworkStatistics.framework,NStat, BPF/pcap 等多种实现。但是没想到第一种实现就已经这么复杂,所以我们把剩下的内容分开多篇来学习。
计算机网络的出现是革命性的,互联网已经重塑了整个世界。相应的,他的蓬勃发展也带来技术的蓬勃发展。虽然历史遗留的问题很多,也有些设计上的缺陷经常被人用于恶意攻击(比如 ARP 的设计就非常不安全),但是以我微弱的能力,对于这些计算机先辈的设计只有滔滔景仰的敬意,以及,缺少文档时阅读起来的痛苦😂。

前面几篇关于 XNU 内核学习的文章里,经常会提到有些数据来自启动时外部传入的参数,比如 mem_size。因为内核本身也是一个巨大的程序,它也会被编译成二进制,然后在系统启动的时候加载到内存里,提供给上层诸如多核 CPU 运算,虚拟内存,线程,进程等一系列能力。
那么问题来了,内核是在什么时候被加载到内存里的呢?谁来负责调用内核的入口函数呢?整个计算的启动过程是怎样的呢?
我在阅读了 Amit Singh 的《Mac OS X Internals》一书中跟启动相关的章节之后,想以此文总结记录一下。希望看到详细内容的读者朋友们,我个人非常推荐 Amit 这本书,内容深入浅出,通俗易读。
我们知道系统内核也是一堆代码,XNU 内核就是 C 写的(I/O Kit 部分是 C++),最终会编译成一个二进制。在 macOS 上唯一能执行的二进制格式是 Mach-O。
全称是 Mach object file format,但是较真起来这个文件格式跟 Mach 内核没有半毛钱关系 XD。因为在 XNU 中,文件系统是由 BSD 实现的,Mach 并不识别任何文件系统。
在 macOS 操作的设计中,我们可以访问磁盘上的任何一个文件(当然有权限控制),所以我们也可以找到内核这个二进制,就是 /System/Library/Kernels/kernel。理论上你可以删掉这个文件,或者自己编译一个内核替换他,但是我不建议你这么做😂。
比 OS X 10.11 El Capitan 更早的系统直接就在 /mach_kernel
所以要让内核这个大程序跑起来,首先得有人把这个文件读取后放进内存里,找到入口,然后调用,这个过程大概是这样的:
ROM 即 Read Only Memory,在 PC 中通常是嵌在主板上的一块芯片。有自己折腾过 PC 攒机经验的小伙伴们肯定听说过 BIOS 这个东西。它的全称是 Basic Input/Output Service。CPU 从 ROM 中读取的就是 BIOS,在 Mac 上用的是 Intel 的 Extensible Firmware Interface(EFI) 接口,更老的 PowerPC CPU 则用的是 Open Firmware。
这个接口和硬件强相关,所以是由硬件厂商制定的标准。EFI 是英特尔制定的,目前已经交给 Unified EFI Forum 来维护,接口也改名为 UEFI。
因为这个东西并不是硬件 Hardware,也不是上层跑的软件 Software,所以取了个介乎中间的名字固件 Firmware。这东西是写在硬件上的,有些可以被擦写替换,有些则不可以。之前很火的利用 iOS Firmware 漏洞来越狱的工具非常强大的一点就在于此:这个固件写在硬件上,Apple 无法通过 OTA 让旧机器更新固件,也就无法修复漏洞,所以越狱对于旧机器会一直有效。
这期间你甚至可以基于这个简单的系统开发软件,除了越狱之外还有很多可以做的。《Mac OS X Internals》提到 Open Firmware 还自带了 telnet, tftp 等工具,有点意思。
在 Mac 上以前用的是 BootX,后来 Apple 的所有产品,包括 iOS 都升级为 iBoot 了。这个东西~~也被编译为 Mach-O 文件~~是一个 efi 文件,可以参考这里。这文件就放在这里 /System/Library/CoreServices/boot.efi。代码是闭源的,之前有人放出了泄漏代码在 GitHub 上:https://github.com/h1x0rz3r0/iBoot。不过现在仓库被关闭了。
BootX 的代码是开源的,可以在这里找到: https://opensource.apple.com/tarballs/BootX/
BootX 负责初始化内核运行环境和加载内核,具体的分析可以看《Mac OS X Internals》的 4.10 章节。
前面已经讲过 kernel 是一个 Mach-O 文件,这个文件的结构大概是这样的:

开始加载内核之前,系统提供了 otool 这个工具用于分析 Mach-O 文件,这个有意思我们可以介绍一下。
# file 命令查看 kernel 的文件格式 ➜ Kernels file kernel kernel: Mach-O 64-bit executable x86_64otool 命令 -h 看一下 Mach Header 信息
➜ Kernels otool -hv kernel Mach header magic cputype cpusubtype caps filetype ncmds sizeofcmds flags MH_MAGIC_64 X86_64 ALL 0x00 EXECUTE 18 3968 NOUNDEFS PIE
otool 代码是开源的,可以在这里找到。当我们运行 otool 命令时,会掉进它的 main() 函数,解析一大堆 -h 之类的 flag 之后,会调用内核的 open() 方法打开文件,位于 bsd/vfs/vsf_syscalls.c。
BSD 的 Mach-O 文件读取实现在这个函数:
int
open1(vfs_context_t ctx, struct nameidata *ndp, int uflags,
struct vnode_attr *vap, fp_allocfn_t fp_zalloc, void *cra,
int32_t *retval)
otool -h 取得的是 Mach Header 信息,结构体如下:
/* * The 64-bit mach header appears at the very beginning of object files for * 64-bit architectures. */ struct mach_header_64 { uint32_t magic; /* mach magic number identifier */ cpu_type_t cputype; /* cpu specifier */ cpu_subtype_t cpusubtype; /* machine specifier */ uint32_t filetype; /* type of file */ uint32_t ncmds; /* number of load commands */ uint32_t sizeofcmds; /* the size of all the load commands */ uint32_t flags; /* flags */ uint32_t reserved; /* reserved */ };
/* Constant for the magic field of the mach_header_64 (64-bit architectures) / #define MH_MAGIC_64 0xfeedfacf / the 64-bit mach magic number */
MH_MAGIC_64 和 MH_CIGAM_64 是不同大小端系统定义的常数,莫名有点喜感。
CPU Type 和 SubType 都在 XNU 代码里定义,位于 osfmk/mach/machine.h,一堆 hardcode 的定义。诸如 CPU Type CPU_TYPE_POWERPC64 或者 CPU_TYPE_x86_64 之类的,满满的历史痕迹。SubType 则是虽然大家都是 POWERPC 但也有可能不兼容,如果所有都兼容就是 CPU_SUBTYPE_POWERPC_ALL
filetype 定义在 EXTERNAL_HEADERS/mach-o/loader.h。kernel 打出来是 2,也即是 MH_EXECUTE,可执行文件。
ncmds 是 load commands 有多少条, sizeofcmds 是所有 load commands 加起来的 size,以字节为单位。
详细的 Header 说明这里有篇文章大家可以参考一下: aidansteele/osx-abi-macho-file-format-reference: Mirror of OS X ABI Mach-O File Format Reference。
Load command 就跟在 Mach Header 后面,应该算作 Header 的一部分,再往下就是编译好的二进制文件了。
Load Command 描述了文件的逻辑结构,以及文件在内存里的布局信息。内核执行 Mach-O 文件的实现在 bsd/kern/kern_exec.c,入口是 execve() 方法。在 parse_machfile() 方法中会遍历所有的 load commands 然后执行不同的命令,遇到 LC_MAIN 就会执行 load_main(),创建一个线程,加载函数主入口。
eip 寄存器(下一条指令)Load command 是有很多不同类型的。以前 LC_THREAD 或者 LC_UNIXTHREAD 是函数入口,不过从 10.8 开始就改成 LC_MAIN 了。
现在我们用 otool -l 看看 kernel 的 load commands。
# otool 命令 -l 查看 load commands
➜ Kernels otool -l kernel
kernel:
Mach header
magic cputype cpusubtype caps filetype ncmds sizeofcmds flags
0xfeedfacf 16777223 3 0x00 2 18 3968 0x00200001
Load command 0
cmd LC_SEGMENT_64
cmdsize 392
segname __TEXT
vmaddr 0xffffff8000200000
vmsize 0x0000000000a00000
fileoff 0
filesize 10485760
maxprot 0x00000005
initprot 0x00000005
nsects 4
flags 0x0
...
otool -l 的结果非常长,可以 >> 到一个文本文件再打开。内核比较特殊,入口不在 LC_MAIN 而是 LC_UNIXTHREAD。我们找到 LC_UNIXTHREAD 所在的地方:
Load command 15
cmd LC_UNIXTHREAD
cmdsize 184
flavor x86_THREAD_STATE64
count x86_THREAD_STATE64_COUNT
rax 0x0000000000000000 rbx 0x0000000000000000 rcx 0x0000000000000000
rdx 0x0000000000000000 rdi 0x0000000000000000 rsi 0x0000000000000000
rbp 0x0000000000000000 rsp 0x0000000000000000 r8 0x0000000000000000
r9 0x0000000000000000 r10 0x0000000000000000 r11 0x0000000000000000
r12 0x0000000000000000 r13 0x0000000000000000 r14 0x0000000000000000
r15 0x0000000000000000 rip 0xffffff8000197000
rflags 0x0000000000000000 cs 0x0000000000000000 fs 0x0000000000000000
gs 0x0000000000000000
其中 rip 寄存器里的地址 0xffffff8000197000 就是内核函数的入口。我们可以用 nm 工具列出内核的所有符号然后匹配一下:
➜ Kernels nm kernel | grep -i 197000
ffffff8000197000 S __start
ffffff8000197000 S _pstart
非常好,这样 XNU 内核就通过这个内存地址把 __start() 函数加载到内存里,愉快地开机了。
看到这里不知道大家有没有个疑惑,就是 BSD 读取 Mach-O 的实现我懂,但是 BSD 不是在 kernel 里面的吗,这时候 kernel 自己都还没被加载啊喂😂。
没错,上面描述的是普通 Mach-O 文件被内核加载的过程,但是内核自己是被 Bootloader 加载的,所以它的实现是在 Bootloader 里面。新的 iBoot 没有开源所以我们看看 BootX 的实现。
BootX 的整体入口在 bootx.tproj/sl.subproj/main.c 文件中:
const unsigned long StartTVector[2] = {(unsigned long)Start, 0};
StartTVector 指向 Start() 函数:
static void Start(void *unused1, void *unused2, ClientInterfacePtr ciPtr) { long newSP;// Move the Stack to a chunk of the BSS newSP = (long)gStackBaseAddr + sizeof(gStackBaseAddr) - 0x100; asm volatile("mr r1, %0" : : "r" (newSP));
Main(ciPtr); }
调用 Main(),里面调用 InitEverything(),然后通过 GetBootPaths() 拿到 kernel 文件路径,然后 DecodeKernel() 获得内核的主入口内存地址:
gKernelEntryPoint = ppcThreadState->srr0;
最后 CallKernel() 调用内核入口:
// Call the Kernel's entry point
(*(void (*)())gKernelEntryPoint)(gBootArgsAddr, kMacOSXSignature);
留意到这里内核的入口地址在 srr0 寄存器,这是老的 BootX 的代码,我们上面分析了一下 kernel 的 Mach-O 文件可以看到新的内核的入口是在 rip 寄存器上的。
nm 会输出一样地址的两个函数?留意到我们刚用 nm 工具 grep 的时候有两个 start 函数:
➜ Kernels nm kernel | grep -i 197000
ffffff8000197000 S __start
ffffff8000197000 S _pstart
这是为啥?原因是这两个函数的实现可能是完全一致的,然后被编译优化了。那么这两个函数的实现是怎样的呢?
这两个函数是用汇编实现的,位置在 osfmk/x86_64/start.s。里面包含了 32 位和 64 位的兼容代码,比较长且我自己也看不懂😂。
.code32
.text
.section __HIB, __text
.align ALIGN
.globl EXT(_start)
.globl EXT(pstart)
LEXT(_start)
LEXT(pstart)
不过可以看到上述代码声明了全局符号 _start 和 pstart 给链接器,并且 _start 和 pstart 底下的实现是一样的。所以编译优化后这两个函数的地址是一样的。
那么为什么入口是 _start 呢?因为链接器默认的入口就是 _start。Linux 链接器 ld 的默认入口就是 _start,Apple 用的 Darwin Linker (ld64) 也是。可以到这里看看 Darwin Linker 的源代码: https://opensource.apple.com/source/ld64/ld64-97.2/
如果想要自定义入口可以使用 -e 参数:
ld -e my_entry_point -o out a.o
LC_MAIN 和 entryoffMac OS X 10.8 以及 iOS 10.6 以后,ld64 就把 LC_UNIXTHREAD 改成 LC_MAIN 了,同时整个系统所有 App 都实现了 ASLR(Address space layout randomization)。
每次程序加载到内存的时候都会加上一个随机的偏移量,用于防止恶意程序的攻击。ASLR 是内核实现的,所以内核自身当然没法动态偏移。
我们用 otool -l 看看 TweetBot.app 的 Mach-O 文件。LC_MAIN 这个 cmd 不显示内存地址了,变成了 entryoff。
Load command 11
cmd LC_MAIN
cmdsize 24
entryoff 7084
stacksize 0
但是符号表还在 Mach-O 文件中,存于 __LINKEDIT。
entryoff 是入口函数相对于文件头的偏移量,16 进制为 0x1BAC。
再加上一个不同平台不一样的基准偏移量,在 Mac 上是 0x100000000,所以是 0x100001BAC。
方便起见,可以使用 MachOView 这个 App 打开 Mach-O 文件,但是 release App 一般都会去掉符号所以你也看不到这个地址对应的是不是 main 之类的函数。所以读者朋友可以自己编译一个 Debug 版来看,可参考 macOS 内核之一个 App 如何运行起来。
一个 App 如何启动可以参考这里: macOS 内核之一个 App 如何运行起来
其实 BIOS(UEFI) 启动时的硬件检查,Bootloader(BootX) 加载后做的事情,以及内核的主入口被调用之后,这一系列的操作都做了无数的事情。《Mac OS X Internals》书里对这些详细的步骤做了很好的解释,读起来对作者非常服气。
最近读内核代码总会发现各种曾经似懂非懂的概念在阻碍我继续学习,并且东看一下西看一下也不能形成很好的整体印象。所以阅读《Mac OS X Internals》这样的书是一种非常好的辅助。同时也建议读者朋友们不要只是读书,或者只是读代码。最好是两者结合动手实践一下,可以获得更深刻的理解。

在 macOS 内核之 CPU 占用率信息 | 枫言枫语 一文我们分析了 iOS 和 macOS 获取 CPU 占用信息的方法和内核的实现,本篇我们来看看内存信息的实现。
照例先从 iOS 开始。iOS 由于系统限制,App 层面只能获取自身的内存信息,无法获取其他 App 的内存信息。所以我们先看如何获取自己 App 的内存信息。
系统接口使用很简单,参考滴滴开源的 DoraemonKit 的实现如下:
+ (NSInteger)useMemoryForApp{
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
kern_return_t kernelReturn = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count);
if(kernelReturn == KERN_SUCCESS)
{
int64_t memoryUsageInByte = (int64_t) vmInfo.phys_footprint;
return memoryUsageInByte/1024/1024;
}
else
{
return -1;
}
}
//设备总的内存
(NSInteger)totalMemoryForDevice{
return [NSProcessInfo processInfo].physicalMemory/1024/1024;
}
关键 API 还是 task_info(),取当前进程的信息,第一个参数为当前进程的 mach port(可参考上一篇讲过对这个 mach port 构造的实现),传入参数 TASK_VM_INFO 获取虚拟内存信息,后两个参数是返回值,传引用。
可以看到 task_vm_info_data_t 里的 phys_footprint 就是当前进程的内存占用,以 byte 为单位。腾讯开源的 Matrix亦使用一致的实现。
footprint 这个术语在 Apple 的文档里有曰过: Technical Note TN2434: Minimizing your app's Memory Footprint
有了当前进程的内存,再获取整个手机的内存,比一下就有当前进程的内存占用率了。获取手机的物理内存信息可以用 NSProcessInfo 的 API,如上面 DoraemonKit 的实现。也可以像腾讯的 Matrix 一样用 sysctl() 的接口:
+ (int)getSysInfo:(uint)typeSpecifier
{
size_t size = sizeof(int);
int results;
int mib[2] = {CTL_HW, (int) typeSpecifier};
sysctl(mib, 2, &results, &size, NULL, 0);
return results;
}
(int)totalMemory
{
return [MatrixDeviceInfo getSysInfo:HW_PHYSMEM];
}
kern_return_t
task_info(
task_t task,
task_flavor_t flavor,
task_info_t task_info_out,
mach_msg_type_number_t *task_info_count)
这个函数位于 osfmk/kern/task.c 内部实现并不复杂,大家可以直接看源码。
函数的第一个参数是用作内核与发起系统调用的进程做 IPC 通信的 mach port,第二个参数是获取信息的类型,函数里一顿 switch-case 猛如虎,剩下就是回传数据了。
我们看看 TASK_VM_INFO 的 case,这个case 和 TASK_VM_INFO_PURGEABLE 共享逻辑,后者会多一些 purgeable_ 开头的数据返回。
首先内核会判断调用方是内核进程还是用户进程,内核进程取内核的 map,用户进程去该进程的 map,并加锁。接着就是一顿 map 信息读取了。最后解锁。
// osfmk/kern/ledger.c // 赋值 vm_info->phys_footprint = (mach_vm_size_t) get_task_phys_footprint(task);// 取自 task_ledgers uint64_t get_task_phys_footprint(task_t task) { kern_return_t ret; ledger_amount_t credit, debit;
ret = ledger_get_entries(task->ledger, task_ledgers.phys_footprint, &credit, &debit); if (KERN_SUCCESS == ret) { return (credit - debit); } return 0;
}
task_ledgers 是内核维护的对该进程的"账本",每次为该进程分配和释放内存页的时候就往账本上记录一笔,并且分了多个不同的种类。
// osfmk/kern/task.c
void
init_task_ledgers(void)
这个初始化函数里大概创建了 30 种不同类型的账本,phys_footprint 是其中一个。
// osfmk/i386/pmap.h // osfmk/arm/pmap.h// 增加操作,即分配内存,以页为单位 #define pmap_ledger_debit(p, e, a) ledger_debit((p)->ledger, e, a)
// 减少操作,即释放内存,以页为单位 #define pmap_ledger_credit(p, e, a) ledger_credit((p)->ledger, e, a)
每次内核为该进程分配和释放内存时就往上记录一笔,以此来追踪进程的内存占用。这里假设各位读者都已了解虚拟内存以及为何按内存页(Memory Page)来分配的相关知识,如果有疑问可 Google 之。
pmap Mach 内核用来管理内存的一整套系统,代码古老且复杂,一个函数动辄四、五百行。而且 pmap 对于不同的机器有不同的实现,代码中区分了 i386 和 arm 两种实现。本人才疏学浅,一时半会也学不会,只能日后再做学习。不过通过以上代码追踪,我们可以知道为何在 iOS 中读取 phys_footprint 就能得到当前进程的内存占用。
task_vm_info_data_ 数据结构task_vm_info_data_t 里除了 phys_footprint 还有很多别的东西,我们可以看看这个结构体的定义:
#define TASK_VM_INFO 22 #define TASK_VM_INFO_PURGEABLE 23struct task_vm_info { // 虚拟内存大小,以 byte 为单位 mach_vm_size_t virtual_size; // Memory Region 个数 integer_t region_count; // 内存分页大小 integer_t page_size; // 实际物理内存大小,以 byte 为单位 mach_vm_size_t resident_size; // _peak 记录峰值,写入时会作比较,比原来的大才会更新 mach_vm_size_t resident_size_peak;
// 带 _peak 的都是运行过程中记录峰值的 mach_vm_size_t device; mach_vm_size_t device_peak; mach_vm_size_t internal; mach_vm_size_t internal_peak; mach_vm_size_t external; mach_vm_size_t external_peak; mach_vm_size_t reusable; mach_vm_size_t reusable_peak; mach_vm_size_t purgeable_volatile_pmap; mach_vm_size_t purgeable_volatile_resident; mach_vm_size_t purgeable_volatile_virtual; mach_vm_size_t compressed; mach_vm_size_t compressed_peak; mach_vm_size_t compressed_lifetime; /* added for rev1 */ mach_vm_size_t phys_footprint; /* added for rev2 */ mach_vm_address_t min_address; mach_vm_address_t max_address;
}; typedef struct task_vm_info task_vm_info_data_t;
在 macOS 上我们在终端运行 vm_stat 可以看到以下内存信息输出输出:
➜ darwin-xnu git:(master) vm_stat
Mach Virtual Memory Statistics: (page size of 4096 bytes)
Pages free: 349761.
Pages active: 1152796.
Pages inactive: 1090213.
Pages speculative: 22734.
Pages throttled: 0.
Pages wired down: 979685.
Pages purgeable: 519551.
"Translation faults": 300522536.
Pages copy-on-write: 16414066.
Pages zero filled: 94760760.
Pages reactivated: 4424880.
Pages purged: 4220936.
File-backed pages: 480042.
Anonymous pages: 1785701.
Pages stored in compressor: 2062437.
Pages occupied by compressor: 598535.
Decompressions: 4489891.
Compressions: 11890969.
Pageins: 6923471.
Pageouts: 38335.
Swapins: 87588.
Swapouts: 432061.
这个系统命令就是通过 host_statistics64() 获取的,代码可见这里。使用的是这个接口:
// osfmk/kern/host.c
kern_return_t
host_statistics64(host_t host, host_flavor_t flavor, host_info64_t info, mach_msg_type_number_t * count)
照例第一个参数填 mach_host_self(),用于跟内核 IPC。第二个参数是取的系统统计信息类型,我们要取内存,所以填 HOST_VM_INFO64。剩下两个就是返回的数据了。
返回的数据类型会 cast 成 vm_statistics64_t
// osfmk/mach/vm_statistics.h/*
- vm_statistics64
- History:
- rev0 - original structure.
- rev1 - added purgable info (purgable_count and purges).
- rev2 - added speculative_count.
----- rev3 - changed name to vm_statistics64.
changed some fields in structure to 64-bit onarm, i386 and x86_64 architectures.- rev4 - require 64-bit alignment for efficient access
in the kernel. No change to reported data.*/
struct vm_statistics64 { natural_t free_count; /* # 空闲内存页数量,没有被占用的 / natural_t active_count; / # 活跃内存页数量,正在使用或者最近被使用 / natural_t inactive_count; / # 非活跃内存页数量,有数据,但是最近没有被使用过,下一个可能就要干掉他 / natural_t wire_count; / # 系统占用的内存页,不可被换出的 / uint64_t zero_fill_count; / # Filled with Zero Page 的页数 / uint64_t reactivations; / # 重新激活的页数 inactive to active / uint64_t pageins; / # 换入,写入内存 / uint64_t pageouts; / # 换出,写入磁盘 / uint64_t faults; / # Page fault 次数 / uint64_t cow_faults; / # of copy-on-writes / uint64_t lookups; / object cache lookups / uint64_t hits; / object cache hits / uint64_t purges; / # of pages purged / natural_t purgeable_count; / # of pages purgeable / / * NB: speculative pages are already accounted for in "free_count", * so "speculative_count" is the number of "free" pages that are * used to hold data that was read speculatively from disk but * haven't actually been used by anyone so far. * / natural_t speculative_count; / # of pages speculative */
/* added for rev1 */ uint64_t decompressions; /* # of pages decompressed */ uint64_t compressions; /* # of pages compressed */ uint64_t swapins; /* # of pages swapped in (via compression segments) */ uint64_t swapouts; /* # of pages swapped out (via compression segments) */ natural_t compressor_page_count; /* # 压缩过个内存 */ natural_t throttled_count; /* # of pages throttled */ natural_t external_page_count; /* # of pages that are file-backed (non-swap) mmap() 映射到磁盘文件的 */ natural_t internal_page_count; /* # of pages that are anonymous malloc() 分配的内存 */ uint64_t total_uncompressed_pages_in_compressor; /* # of pages (uncompressed) held within the compressor. */} attribute((aligned(8)));
typedef struct vm_statistics64 *vm_statistics64_t; typedef struct vm_statistics64 vm_statistics64_data_t;
Page Fault 中文翻译为缺页错误之类,其实就是要访问的内存分页已经在虚拟内存里,但是还没加载到物理内存。这时候如果访问合法就从磁盘加载到物理内存,如果不合法(访问 nullptr 之类)就 crash 这个进程。详细解释可以参考这里。
Filled with Zero Page: 操作系统会维护一个 page,里面填满了 0,叫做 zero page。当一个新页被分配的时候,系统就往这个页里填 zero page。我的理解是相当于清空数据保护,防止其他进程读取旧数据吧。
空闲内存计算
speculative pages 是 OS X 10.5 引入的一个内核特性。内核先占用了这些 page,但是还没被真的使用,相当于预约。比如说当一个 App 在顺序读取硬盘数据的时候,内核发现它读完了 1, 2, 3 块, 那么很可能它会读 4。这时候内核先预约一块内存页准备给未来有可能会出现的 4。大概是这么个理解,可以参考这里的回答。
在上面的注释中,speculative pages 是被计入 vm_stat.free_count 里的,所以 vm_stat 的实现里,空闲内存的计算减去了这一部分:
pstat((uint64_t) (vm_stat.free_count - vm_stat.speculative_count), 8);
以上我们就得到了系统内存信息了。不过通过 host_statistics64() 接口取到的数据加一起并不等于系统物理内存,这是由内核统计实现决定了,这里有一个讨论有兴趣可以看看。
有了 active_count, speculative_count 和 wired_count,我们就可以计算内存占用率了?还差一个 compressed。
Memory Compression
内存压缩技术是从 OS X Mavericks (10.9) 开始引入的(iOS 则是 iOS 7 开始),可以参考官方文档:OS X Mavericks Core Technology Overview。
简单理解为系统会在内存紧张的时候寻找 inactive memory pages 然后开始压缩,以 CPU 时间来换取内存空间。所以 compressed 也要算进使用中的内存。另外还需要记录被压缩的 page 的信息,记录在 compressor_page_count 里,这个也要算进来。
(active_count + wired_count + speculative_count + compressor_page_count) * page_size
这才是最终的系统内存占用情况,以 byte 为单位。这个接口 host_statistics() 在 iOS 亦适用。
Mac 上的 iStat Menus App 就是这样计算内存占用的,但是,Activity Monitor.app 却有点不同。留意到他的 Memory Used 有一项叫做 App Memory。这个是根据 internal_page_count 来计算的,所以 Activity Monitor.app 的计算是这样的:
(internal_page_count + wired_count + compressor_page_count) * page_size
KSCrash 是一个开源的 Crash 堆栈信息捕捉库,里面有两个关于内存的函数:
static uint64_t freeMemory(void) { vm_statistics_data_t vmStats = {}; vm_size_t pageSize = 0; if(VMStats(&vmStats, &pageSize)) { return ((uint64_t)pageSize) * vmStats.free_count; } return 0; }
static uint64_t usableMemory(void) { vm_statistics_data_t vmStats = {}; vm_size_t pageSize = 0; if(VMStats(&vmStats, &pageSize)) { return ((uint64_t)pageSize) * (vmStats.active_count + vmStats.inactive_count + vmStats.wire_count + vmStats.free_count); } return 0; }
freeMemory() 是直接返回的 free_count,usableMemory() 则是 active_count + inactive_count + wire_count + free_count。
根据这两个函数的实现我猜测 freeMemory() 是想表达当前空闲内存的意思,usableMemory() 则是整个系统一共可以使用的内存有多少。
理论上 usableMemory 可以用硬件信息代替,但实际上系统接口返回的数据加一起一般都比物理内存少。使用这种方式计算我猜可能也是想获得更准备的系统实际可用内存吧。
但是根据上文我们已经知道,free_count 还包含了 speculative_count,最好去掉。并且 iOS 7 开始还加入了 memory compression,所以还得加上这个。
KSCrash 用的接口是 host_statistics(),这个接口没有返回 compression 相关的信息,猜测应该是这个项目开始的时候还没有 host_statistics64() 接口,或者当时 iPhone 的 64 位机器还不够普及(iPhone 5s 开始有 64 位机器)。
不过我自己实践了一下,即使用 host_statistics64() 接口,加上 compressions 和 compressor_page_count 之后的结果和不加的结果差不多。也有可能当时我的手机并没有使用大量内存所以压缩效果不明显就是。
mem: 2712944640
mem2: 2712961024
参考 Apple 官方文档 About the Virtual Memory System,Mac 上会有换页行为,也就是当物理内存不够了,就把不活跃的内存页暂存到磁盘上,以此换取更多的内存空间。
具体的步骤是:
但是在 iOS 上,系统不会有 page out 行为。这大概是 Apple 当年把 Darwin 系统移植到手机上时遇到的最头痛的问题之一:没有 swap 空间。桌面操作系统发展了几十年,有非常成熟的硬件条件,但是手机并不是。手机自带的空间也很小,属于珍贵资源,同时跟桌面硬件比起来,手机的闪存 I/O 速度太慢。所以普遍手机的操作系统都没有设计 swap。
所以一旦空闲内存下降到边界,iOS 的内核就会把 inactive 且没有修改过的内存释放掉,而且还可能会给正在运行的 App 发出内存警告,让 App 及时释放内存不然就之间挂掉,也就是俗称的"爆内存"(OOM Out-of-Memory)。
负责把 iOS App 干掉的杀手叫做 jetsam,这个东西在 Mac 上没有。
这篇 No pressure, Mon! Handling low memory conditions in iOS and Mavericks 和这篇 iOS内存abort(Jetsam) 原理探究 | SatanWoo 对于 jetsam 有些解析。不过 jetsam 相关的代码非常长,直接看的话是真的眼花缭乱。
看完这两篇文章之后我发现几个地方不太清楚,所以还是自己去走了一遍,但是我从最终的 kill 那一步反推回去,读起来比从一开始看 memory status 一步步往下走要容易一些。所以有兴趣看这部分代码的朋友,建议也从 memorystatus_do_kill() 反推回去。
arm_init()kernel_bootstrap()machine_startup()kernel_bootstrap()kernel_bootstrap_thread()bsd_init()memorystatus_init()memorystatus_thread()memorystatus_act_aggressive()memorystatus_kill_top_process()memorystatus_kill_proc()memorystatus_do_kill()jetsam_do_kill()exit_with_reason()thread_terminate()thread_terminate_internal()thread_apc_ast()thread_terminate_self()threadcnt == 0 时调用 proc_exit()一共 20 层之多,内核代码果然年代久远。 XD
其中 #1-#8 都是初始化,memorystatus_init() 里面创建了多个(hardcoded 为 3 个)最高优先级的内核线程:
int max_jetsam_threads = JETSAM_THREADS_LIMIT; #define JETSAM_THREADS_LIMIT 3
kernel_thread_start_priority(memorystatus_thread, NULL, 95 /* MAXPRI_KERNEL */, &jetsam_threads[i].thread);
以下条件命中时,会采取行动:
static boolean_t
memorystatus_action_needed(void)
{
#if CONFIG_EMBEDDED
return (is_reason_thrashing(kill_under_pressure_cause) ||
is_reason_zone_map_exhaustion(kill_under_pressure_cause) ||
memorystatus_available_pages <= memorystatus_available_pages_pressure);
#else /* CONFIG_EMBEDDED */
return (is_reason_thrashing(kill_under_pressure_cause) ||
is_reason_zone_map_exhaustion(kill_under_pressure_cause));
#endif /* CONFIG_EMBEDDED */
}
thrashing
kill_under_pressure_cause 为 thrashing 的条件:
kMemorystatusKilledFCThrashing
kMemorystatusKilledVMCompressorThrashing
kMemorystatusKilledVMCompressorSpaceShortage
会在这里触发 compressor_needs_to_swap(void),当内存需要换页的时候,arm 架构的实现就会判断当前 vm compressor 状态然后抛出上述三种 cause 之一,按照我的理解应该是内存压缩都开始告急了。
ZoneMapExhaustion
kill_under_pressure_cause 为 zone_map_exhaustion 的条件:
kMemorystatusKilledZoneMapExhaustion
这种情况则是由 kill_process_in_largest_zone() 函数发起,如果能找到 alloc 了最大 zone 的一个进程就干掉他,不行就记录 cause,走 jetsam 流程。
memorystatus_available_pages <= memorystatus_available_pages_pressure
或者是可用内存页少于系统设定的阈值,这个阈值计算如下:
unsigned long pressure_threshold_percentage = 15; unsigned long delta_percentage = 5;
memorystatus_delta = delta_percentage * atop_64(max_mem) / 100; memorystatus_available_pages_pressure = (pressure_threshold_percentage / delta_percentage) * memorystatus_delta;
相当于 atop_64(max_mem) * 15 / 100 也就是最大内存的 15%。max_mem 是 arm_vm_init() 启动时传入的,应该就是硬件内存大小了。
memorystatus_thread() 会先取一波原因:
/* Cause */
enum {
kMemorystatusInvalid = JETSAM_REASON_INVALID,
kMemorystatusKilled = JETSAM_REASON_GENERIC,
kMemorystatusKilledHiwat = JETSAM_REASON_MEMORY_HIGHWATER,
kMemorystatusKilledVnodes = JETSAM_REASON_VNODE,
kMemorystatusKilledVMPageShortage = JETSAM_REASON_MEMORY_VMPAGESHORTAGE,
kMemorystatusKilledProcThrashing = JETSAM_REASON_MEMORY_PROCTHRASHING,
kMemorystatusKilledFCThrashing = JETSAM_REASON_MEMORY_FCTHRASHING,
kMemorystatusKilledPerProcessLimit = JETSAM_REASON_MEMORY_PERPROCESSLIMIT,
kMemorystatusKilledDiskSpaceShortage = JETSAM_REASON_MEMORY_DISK_SPACE_SHORTAGE,
kMemorystatusKilledIdleExit = JETSAM_REASON_MEMORY_IDLE_EXIT,
kMemorystatusKilledZoneMapExhaustion = JETSAM_REASON_ZONE_MAP_EXHAUSTION,
kMemorystatusKilledVMCompressorThrashing = JETSAM_REASON_MEMORY_VMCOMPRESSOR_THRASHING,
kMemorystatusKilledVMCompressorSpaceShortage = JETSAM_REASON_MEMORY_VMCOMPRESSOR_SPACE_SHORTAGE,
};
如果是上一节 memorystatus_action_needed() 里的原因则走 memorystatus_kill_hiwat_proc()。hiwat 就是 high water。这时候不会立刻杀掉该进程,而是判断一下 phys_footprint 是否超过 memstat_memlimit,超过就干掉。
这一步如果成功杀掉了,那么这个循环就先结束,如果杀失败了,那就要开始愤怒模式了:
static boolean_t
memorystatus_act_aggressive(uint32_t cause, os_reason_t jetsam_reason, int *jld_idle_kills, boolean_t *corpse_list_purged, boolean_t *post_snapshot)
vm_pressure_thread 也会监控 VM Pressure,判断是否要杀进程。
memorystatus_pages_update() 会触发 vm pressure 检查,非常多地方会触发这个函数,已无力读下去。
不过最终大家都会会走 memorystatus_do_kill() 调用 jetsam_do_kill(),进入 exit_with_reason() 带一个 SIGKILL 信号。比较有意思是它的代码最末尾是:
/* Last thread to terminate will call proc_exit() */ task_terminate_internal(task);return(0);
我还以为是在 task_terminate_internal() 发了退出信号,但是并没有,这里面只是清理了 IPC 空间,map 之类的内核信息。注释说最后一个线程会调用 proc_exit(),原来是在这里调用的:
while (p->exit_thread != self) { if (sig_try_locked(p) <= 0) { proc_transend(p, 1); os_reason_free(exit_reason);if (get_threadtask(self) != task) { proc_unlock(p); return(0); } proc_unlock(p); thread_terminate(self); if (!thread_can_terminate) { return 0; } thread_exception_return(); /* NOTREACHED */ } sig_lock_to_exit(p); }
遍历所有线程,然后都调用 thread_terminate() 结束线程,这个函数的实现里面有判断 threadcnt == 0 时就调用 proc_exit(),这里面就会发送我们熟悉的 SIGKILL 信号然后退出进程了。
但是这些信息内核却并没有抛给应用,所以应用也不知道自己 OOM 了。参考 Tencent/matrix 的实现,也只能用排除法。
if (info.isAppCrashed) {
// 普通 crash 捕获框架能抓到的 crash
s_rebootType = MatrixAppRebootTypeNormalCrash;
} else if (info.isAppQuitByUser) {
// 用户主动关闭,来自 UIApplicationWillTerminateNotification
s_rebootType = MatrixAppRebootTypeQuitByUser;
} else if (info.isAppQuitByExit) {
// 利用 atexit() 注册回调
s_rebootType = MatrixAppRebootTypeQuitByExit;
} else if (info.isAppWillSuspend || info.isAppBackgroundFetch) {
// App 主动调用的,matrix 的注释曰: notify the app will suspend, help improve the detection of the plugins
if (info.isAppSuspendKilled) {
s_rebootType = MatrixAppRebootTypeAppSuspendCrash;
} else {
s_rebootType = MatrixAppRebootTypeAppSuspendOOM;
}
} else if ([MatrixAppRebootAnalyzer isAppChange]) {
// App 升级了
s_rebootType = MatrixAppRebootTypeAPPVersionChange;
} else if ([MatrixAppRebootAnalyzer isOSChange]) {
// 系统升级了
s_rebootType = MatrixAppRebootTypeOSVersionChange;
} else if ([MatrixAppRebootAnalyzer isOSReboot]) {
// 系统重启了
s_rebootType = MatrixAppRebootTypeOSReboot;
} else if (info.isAppEnterBackground) {
// 排除以上情况,剩下的就认为是 OOM,在后台就是后台 OOM
s_rebootType = MatrixAppRebootTypeAppBackgroundOOM;
} else if (info.isAppEnterForeground) {
// 在前台,判断下是否死锁
if (info.isAppMainThreadBlocked) {
// 死锁,来自 matrix 的卡顿监控,跟内存无关
s_rebootType = MatrixAppRebootTypeAppForegroundDeadLoop;
s_lastDumpFileName = info.dumpFileName;
} else {
// 前台 OOM
s_rebootType = MatrixAppRebootTypeAppForegroundOOM;
s_lastDumpFileName = @"";
}
} else {
s_rebootType = MatrixAppRebootTypeOtherReason;
}
iOS/Mac 获取内存占用信息的接口比较简单,但是涉及的概念和实现却非常复杂和庞大,尤其是内核的实现,一个函数动不动就 500 行以上,如果没有配套的书籍讲解,阅读起来十分吃力。所以读这种类型的代码,还是找到关键函数往回推比较简单点。XDDD
P.S. 使用 kill -l 命令可以看到所有的 tty 信号。SIGHUP 是 1,SIGKILL 是 9。所以我们经常使用的 kill -9 <pid> 命令就是告诉该进程你被 Kill 了。
P.P.S. memorystatus_do_kill() 函数的参数叫做 victim_p XDDD

在 iOS/Mac 上开发 App,当我们需要性能监控能力的时候,往往需要 CPU 信息来辅助追查:比如当前时刻是否 CPU 高占导致 App 卡到掉渣之类。
iOS 由于系统的限制,在不越狱的情况下无法获知整个系统的 CPU 信息,只能拿到自己 App 的所有线程信息,然后把 CPU 时间全部加起来得到一个大概的数值以供参考。可以参考腾讯开源的Matrix 的实现。代码太长我们只看核心部分:
// 取当前进程基础信息,其实不取也没有关系 kr = task_info(mach_task_self(), TASK_BASIC_INFO, (task_info_t) tinfo, &task_info_count);// 取当前进程的所有线程 kr = task_threads(mach_task_self(), &thread_list, &thread_count); // 遍历所有线程,取一波 CPU 时间 for (j = 0; j < thread_count; j++) { // 取一下线程信息 thread_info_count = THREAD_INFO_MAX; kr = thread_info(thread_list[j], THREAD_BASIC_INFO, (thread_info_t) thinfo, &thread_info_count); basic_info_th = (thread_basic_info_t) thinfo; // 计算一下时间和 CPU Usage,需要除以一个 TH_USAGE_SCALE 的 scale factor if (!(basic_info_th->flags & TH_FLAGS_IDLE)) { tot_sec = tot_sec + basic_info_th->user_time.seconds + basic_info_th->system_time.seconds; tot_usec = tot_usec + basic_info_th->system_time.microseconds + basic_info_th->system_time.microseconds; tot_cpu = tot_cpu + basic_info_th->cpu_usage / (float) TH_USAGE_SCALE * 100.0; } } // 最后释放一下 kr = vm_deallocate(mach_task_self(), (vm_offset_t) thread_list, thread_count * sizeof(thread_t));
或者滴滴开源的 DoraemonKit 的实现,跟上面的实现基本是一样的,只是省略了task_info()和user_time, system_time的计算。
留意到我们需要把 cpu_usage 取得的值除以 TH_USAGE_SCALE 后才能获得一个准确的值。为啥?这个东西用来干啥子的?
我们直接看看 darwin-xnu 对 thread_info() 的实现。这个函数只是简单地加了个锁,真正的实现在 thread_info_internal()。位置在 osfmk/kern/thread.c。
如果参数为 THREAD_BASIC_INFO 则走 retrieve_thread_basic_info()。这个函数先取了一波系统 timer 的数据给 user_time 和 system_time,然后就是重头戏了:
#define TH_USAGE_SCALE 1000/* * To calculate cpu_usage, first correct for timer rate, * then for 5/8 ageing. The correction factor [3/5] is * (1/(5/8) - 1). */ basic_info->cpu_usage = 0;#if defined(CONFIG_SCHED_TIMESHARE_CORE) if (sched_tick_interval) { basic_info->cpu_usage = (integer_t)(((uint64_t)thread->cpu_usage * TH_USAGE_SCALE) / sched_tick_interval); basic_info->cpu_usage = (basic_info->cpu_usage * 3) / 5; } #endif
if (basic_info->cpu_usage > TH_USAGE_SCALE) basic_info->cpu_usage = TH_USAGE_SCALE;
CONFIG_SCHED_TIMESHARE_CORE 这个宏应该是分时调度线程的意思,sched_tick_interval 则是定义在 osfmk/kern/sched.h 的一个全局变量。在分时调度逻辑初始化的时候,这个值被赋值:
// void sched_timeshare_timebase_init(void)
/* scheduler tick interval / // #define USEC_PER_SEC 1000000ull / microseconds per second */ // #define SCHED_TICK_SHIFT 3 clock_interval_to_absolutetime_interval(USEC_PER_SEC >> SCHED_TICK_SHIFT, NSEC_PER_USEC, &abstime); assert((abstime >> 32) == 0 && (uint32_t)abstime != 0); sched_tick_interval = (uint32_t)abstime;
这个值就是分时调度时(Time)每次 tick 的时间间隔,关于 FreeBSD 的分时模型(Time-sharing) 这里有篇文章可以参考一下。
void clock_interval_to_absolutetime_interval(uint32_t interval, uint32_t scale_factor, uint64_t * result) { uint64_t nanosecs = (uint64_t) interval * scale_factor; uint64_t t64;*result = (t64 = nanosecs / NSEC_PER_SEC) * rtclock_sec_divisor; nanosecs -= (t64 * NSEC_PER_SEC); *result += (nanosecs * rtclock_sec_divisor) / NSEC_PER_SEC;
}
NSEC_PER_SEC 是每一秒中有多少的纳秒(参考这里)。nanosecs / NSEC_PER_SEC 就得到秒了。
rtclock_sec_divisor 比较有意思。首先是 RTC,Real-time clock,中文翻译为实时时钟,是一个小小的时钟芯片,一般装在主板上,使用 CMOS 电池。读者朋友如果有装过 PC 的话应该会在主板上看到一个纽扣电池的卡槽,这个东西可以给 RTC 模块供电。
rtclock_sec_divisor 这个数值来自于以下函数:
static void
timebase_callback(struct timebase_freq_t * freq)
其中 freq 这个参数不同的平台有不同的实现。在时钟模块初始化的时候,内核会注册一个回调 PE_register_timebase_callback(timebase_callback); arm 架构的是是持有这个 callback 然后从硬件读取到相关信息后通过 callback 函数传回去:
void PE_call_timebase_callback(void) { struct timebase_freq_t timebase_freq;timebase_freq.timebase_num = gPEClockFrequencyInfo.timebase_frequency_hz; timebase_freq.timebase_den = 1; if (gTimebaseCallback) gTimebaseCallback(&timebase_freq);
}
timebase_freq_t 结构体的定义如下:
struct timebase_freq_t {
unsigned long timebase_num; // numerator 分子
unsigned long timebase_den; // denominator 分母
};
这种表示时间的方法叫做 Time Base,中文翻译为“时基”(注意这里所谓的时基和示波器的稍有不同,这里主要用作一个计时单位)。上面说到整个计算机的时序系统是建立在 RTC 模块上的,这个东西最重要的核心是一个时钟振荡器。目前多采用频率为 32.768 kHz (2^15) 的石英晶体制作。
在 arm 架构(iPhone)的实现中,timebase_freq 的分母被 hardcode 为 1。
i386(Mac)则取了总线频率做了如下运算:
void PE_call_timebase_callback(void) { struct timebase_freq_t timebase_freq; unsigned long num, den, cnt;num = gPEClockFrequencyInfo.bus_clock_rate_num * gPEClockFrequencyInfo.bus_to_dec_rate_num; den = gPEClockFrequencyInfo.bus_clock_rate_den * gPEClockFrequencyInfo.bus_to_dec_rate_den;
cnt = 2; while (cnt <= den) { if ((num % cnt) || (den % cnt)) { cnt++; continue; }
num /= cnt; den /= cnt;}
timebase_freq.timebase_num = num; timebase_freq.timebase_den = den;
if (gTimebaseCallback) gTimebaseCallback(&timebase_freq); }
gPEClockFrequencyInfo 里的东西在系统启动时由外部传入,应该是硬件信息。其中 arm 架构的实现还根据硬件的不同写了一堆转换,比如三星的 s3c2410 处理器,OMAP 的 OMAP3430 之类的。不过不知道用来做什么,the iPhone Wiki倒是提供了一个线索,大意是 2009 年在 MacRumors有人发了 iPhone 原型机的照片引起大家讨论。由于在系统的 /System/Library/Caches/com.apple.kernelcaches 里有一些其他 CPU 的处理,猜测是当时苹果不晓得要用哪一种 CPU 比较好,是遗留的代码。虽无法求证但是好像很有道理。
在判断完一系列架构之后,如果都不符合就把 timebase_frequency_hz 设置为默认值 24000000,然后在再用 IOKit 接口取 timebase-frequency:
/* Find the time base frequency first. */
if (DTGetProperty(cpu, "timebase-frequency", (void **)&value, &size) == kSuccess) {
/*
* timebase_frequency_hz is only 32 bits, and
* the device tree should never provide 64
* bits so this if should never be taken.
*/
if (size == 8)
gPEClockFrequencyInfo.timebase_frequency_hz = *(unsigned long long *)value;
else
gPEClockFrequencyInfo.timebase_frequency_hz = *value;
}
i386 的实现比较简单,基本就是 vstart() 函数里的启动参数 boot_args_start 带过来。
gPEClockFrequencyInfo.timebase_frequency_hz = 1000000000; gPEClockFrequencyInfo.bus_frequency_hz = 100000000; gPEClockFrequencyInfo.bus_clock_rate_hz = gPEClockFrequencyInfo.bus_frequency_hz; gPEClockFrequencyInfo.dec_clock_rate_hz = gPEClockFrequencyInfo.timebase_frequency_hz;gPEClockFrequencyInfo.bus_clock_rate_num = gPEClockFrequencyInfo.bus_clock_rate_hz; gPEClockFrequencyInfo.bus_clock_rate_den = 1;
gPEClockFrequencyInfo.bus_to_dec_rate_num = 1; gPEClockFrequencyInfo.bus_to_dec_rate_den = gPEClockFrequencyInfo.bus_clock_rate_hz / gPEClockFrequencyInfo.dec_clock_rate_hz;
所以 bus_clock_rate_num 是 100000000,bus_clock_rate_den 是 1。
bus_to_dec_rate_num 是 1, bus_clock_rate_hz 是 100000000, dec_clock_rate_hz 是 1000000000,所以 bus_to_dec_rate_den 是 0.1,但是要留意gPEClockFrequencyInfo.bus_clock_rate_hz / gPEClockFrequencyInfo.dec_clock_rate_hz这个式子里面,这两个参数都是 unsigned long,所以会变成 0。于是
// 100000000*1 num = gPEClockFrequencyInfo.bus_clock_rate_num * gPEClockFrequencyInfo.bus_to_dec_rate_num;
// 1*0 den = gPEClockFrequencyInfo.bus_clock_rate_den * gPEClockFrequencyInfo.bus_to_dec_rate_den;
i386 的 time base 中分子是 100000000 而分母是 0。这让我非常费解,因为底下还要对 den 做计算:
cnt = 2; while (cnt <= den) { if ((num % cnt) || (den % cnt)) { cnt++; continue; }num /= cnt; den /= cnt;
}
这段代码就废了,而且在 timebase_callback(struct timebase_freq_t * freq) 函数的实现中,0 是非法的:
static void timebase_callback(struct timebase_freq_t * freq) { unsigned long numer, denom; uint64_t t64_1, t64_2; uint32_t divisor;if (freq->timebase_den < 1 || freq->timebase_den > 4 || freq->timebase_num < freq->timebase_den) panic("rtclock timebase_callback: invalid constant %ld / %ld", freq->timebase_num, freq->timebase_den); denom = freq->timebase_num; numer = freq->timebase_den * NSEC_PER_SEC; // reduce by the greatest common denominator to minimize overflow if (numer > denom) { t64_1 = numer; t64_2 = denom; } else { t64_1 = denom; t64_2 = numer; } while (t64_2 != 0) { uint64_t temp = t64_2; t64_2 = t64_1 % t64_2; t64_1 = temp; } numer /= t64_1; denom /= t64_1; rtclock_timebase_const.numer = (uint32_t)numer; rtclock_timebase_const.denom = (uint32_t)denom; divisor = (uint32_t)(freq->timebase_num / freq->timebase_den); rtclock_sec_divisor = divisor; rtclock_usec_divisor = divisor / USEC_PER_SEC;
}
为了防止是我脑内运算出的问题,我还实际 copy 了一遍这段代码跑了一下,bus_to_dec_rate_den 为 0 无疑。既已如此,不找到负责这个内核开发的人是无法知道问题的答案了。
但是不管怎样我们现在知道 sched_tick_interval 是系统线程调度用的时间间隔,和硬件时钟频率有关。一开始的问题 TH_USAGE_SCALE 是在内核处理线程调度时,用在 ageing 算法的一个值,hardcode 为 1000,我们除以这个值就能获得一个 CPU 使用百分比数值 basic_info_th->cpu_usage / (float) TH_USAGE_SCALE * 100.0。这里涉及系统的线程优先级调度和 ageing 算法,我还没有完全搞明白,可以参考 Mac OS X Internals: A Systems Approach 一书。
macOS 通过内核接口 host_processor_info() 可以取到 CPU Load Info,这个接口定义在 mach_host.h,实现在 osfmk/kern/host.c。
接口定义如下:
kern_return_t
host_processor_info(host_t host,
processor_flavor_t flavor,
natural_t * out_pcount,
processor_info_array_t * out_array,
mach_msg_type_number_t * out_array_count)
host 是一个 mach port,传 mach_host_self() 就行。如果不知道 Mach Port 是什么可以参考 macOS 内核系列的上一篇 1.1 章节。
这里岔开聊一下 mach_host_self() 的实现。
// libsyscall/mach/mach_legacy.c mach_port_t mach_host_self(void) { return host_self_trap(); }// osfmk/kern/ipc_host.c mach_port_name_t host_self_trap( __unused struct host_self_trap_args *args) { // 取以前当前发起系统调用的进程返回一个
task_t,实际上就是mach_port_t。参考 2.2。 task_t self = current_task(); // 开源代码里没有ipc_port_t的定义但是有ipc_port,字面意义上理解这是发送端的 mach port ipc_port_t sright; // port 名字,简单理解为 ID mach_port_name_t name;
// 内核用的一个互斥锁,加锁 itk_lock(self); // copy 一下传入的 port 参数,如果是 active 的就计数 +1,如果不是就置为 DEAD,就是整数 0 // itk_host 是进程创建的时候内核分配的一个 special port,这个在我们上一篇也有提到。这个创建的源头来自ipc_init(),它的最上游就是各平台自己实现的启动入口,比如 i386 的i386_init(),应该就是开机后干的事情了。 sright = ipc_port_copy_send(self->itk_host); itk_unlock(self); // 这里有一个 space 的概念,可以看下面对current_space()实现的解释。 // 这里通过 space 和 sright 查找到 name 然后内部实现里操作一堆 table 信息的更新,返回 nanme name = ipc_port_copyout_send(sright, current_space()); // 最后返回给上层 return name; }
这就是内核如何创建一个自己的 mach port 然后返回给上层的过程。
顺便看下 current_space() 的实现:
// osfmk/kern/ipc_tt.c kr = ipc_space_create(&ipc_table_entries[0], &space);
// osfmk/ipc/ipc_space.h #define current_space_fast() (current_task_fast()->itk_space) #define current_space() (current_space_fast())
这个 ipc_space_t 主要是用来存储一个表 ipc_space_t,这个表记录了一堆 IPC 相关信息 ipc_entry_t。根据我粗浅的理解,应该是里面有 name 和 entry 的 KV 对应关系,可以互相查询,之前我们说过 name 并不需要全局唯一,内核可以自行查找匹配到对应的进程(task),应该就是通过这个 space 维护的表。
// bsd/kern/kern_prot.c #include <kern/task.h> /* for current_task() */// libsyscall/mach/mach/mach_init.h extern mach_port_t mach_task_self_; #define mach_task_self() mach_task_self_ #define current_task() mach_task_self()
// libsyscall/mach/mach_init.c mach_port_t mach_task_self_ = MACH_PORT_NULL;
void mach_init_doit(void) { // Initialize cached mach ports defined in mach_init.h mach_task_self_ = task_self_trap(); // ... }
current_task() 比较费解的是一路追过去发现它定义为 task_self_trap(),而这个函数上来就先调用了 current_task(),死循环了。
// osfmk/kern/ipc_tt.c
mach_port_name_t
task_self_trap(
__unused struct task_self_trap_args *args)
{
task_t task = current_task();
//…
}
不过 libsyscall/mach/mach_init.c 里引用了 osfmk/mach/mach_traps.h 里的定义 extern mach_port_name_t task_self_trap(void);。也有可能他的实现并不在 ipc_tt.c 里,但是我根本找不到就是了。
回到 host_processor_info() 这个函数,第一个参数填写由内核生成的自己进程的 mach port 用于 IPC,第二个参数则有以下定义:
/*
* Currently defined information.
*/
typedef int processor_flavor_t;
#define PROCESSOR_BASIC_INFO 1 /* basic information */
#define PROCESSOR_CPU_LOAD_INFO 2 /* cpu load information */
#define PROCESSOR_PM_REGS_INFO 0x10000001 /* performance monitor register info */
#define PROCESSOR_TEMPERATURE 0x10000002 /* Processor core temperature */
我们需要 CPU 占用率所以选第二个 PROCESSOR_CPU_LOAD_INFO,剩下的三个参数都是 out 参数,传引用就行。
processor_info_array_t cpuInfo;
mach_msg_type_number_t numCpuInfo;
natural_t numCPUsU = 0U;
kern_return_t err = host_processor_info(mach_host_self(), PROCESSOR_CPU_LOAD_INFO, &numCPUsU, &cpuInfo, &numCpuInfo);
四个参数可以获得不同的信息但是都会回传 processor_info_array_t,这是一个变长数组(variable-sized inline array):
/* processor_info_t: variable-sized inline array that can
* contain:
* processor_basic_info_t: (5 ints) 可以参考 PROCESSOR_BASIC_INFO_COUNT
* processor_cpu_load_info_t:(4 ints) 最大是 CPU_STATE_MAX
* processor_machine_info_t :(12 ints)
* If other processor_info flavors are added, this definition
* may need to be changed. (See mach/processor_info.h) */
type processor_flavor_t = int;
type processor_info_t = array[*:12] of integer_t;
type processor_info_array_t = ^array[] of integer_t;
CPU 占用率的数组 index 定义如下:
#define CPU_STATE_MAX 4
#define CPU_STATE_USER 0 #define CPU_STATE_SYSTEM 1 #define CPU_STATE_IDLE 2 #define CPU_STATE_NICE 3
由于现在的 Mac 基本都是多核 CPU,比如我的 Intel Core i7 CPU 有四核八线程,所以这个接口会返回每个线程 4 个 State 一共 32 个数据。我们可以通过 for 循环来取:
for(unsigned i = 0U; i < numCPUs; ++i) {
uint32_t inUser = (uint32_t)cpuInfo[(CPU_STATE_MAX * i) + CPU_STATE_USER];
uint32_t inSystem = (uint32_t)cpuInfo[(CPU_STATE_MAX * i) + CPU_STATE_SYSTEM];
uint32_t inNice = (uint32_t)cpuInfo[(CPU_STATE_MAX * i) + CPU_STATE_NICE];
uint32_t inIdle = (uint32_t)cpuInfo[(CPU_STATE_MAX * i) + CPU_STATE_IDLE];
}
numCPUs 就是八核,可以通过 sysctl() 传入 hw.cpu 来取。关于 sysctl() 接口可以参考之前的一篇文章,这里不再赘述。
扩展: 超线程 Hyper-threading
以前的 CPU 是一个物理核心对应一个物理线程,这里的线程和我们应用层的线程概念不一样。应用层可以开上百个线程,但是一个 CPU 可能只有一个核心,那么他只能把时间分片给不同的逻辑线程运行,由于速度太快所以感受不出来。后来英特尔开发了超线程技术(Hyper-threading)可以在一个物理核心里模拟出两个线程。那么对于系统内核来说,就相当于物理核心多了一倍。所以 i7 处理器通过
sysctl()取到的 CPU 个数就是 8 个。
user 是用户层 CPU 占用,system 是系统占用,nice 是老系统的遗留属性,现在是 hardcode 返回 0,不过源码没有删掉,idle 就是空闲 CPU 了。
按照之前的风格我们应该直接进入源码,不过这里先卖个关子。通过 host_processor_info() 取到的数据都是整数。直觉上我们认为把所有核心的 user + system + idle 就是全部 CPU,占用比全部就是 CPU 占用率了。
非常合理,有理有据。赶紧试一试。结果出来的百分比很奇怪,基本都在 7% 左右。用 Xcode 编译大项目 iStat Menu 都 100% 了这个结果值还是 7%。一定是哪里出了问题。
于是我参考了 Hammerspoon 的代码,htop 的代码,确认取 CPU Load Info 肯定没问题。那么有问题的可能是我对数据的处理方式。
留意到 Hammerspoon 关于 cpuUsageTick() 的文档 有曰这个接口取到的数据是自系统最近一次启动以来的的 ticks 数据。
前面只说 host_processor_info() 的数组里全是整数但是没说单位是啥。那么 ticks 是什么呢?
准确来讲并不是 CPU ticks 而是 clock ticks,用于计算 CPU 时间的单位。一般会实现一个系统时钟,每隔一个非常短的时间间隔就发起一个 CPU 中断请求,把 tick 计数加一。
但是 host_processor_info() 接口返回的数字都不算大,比如 CPU 比较空闲时 idle 比较多,大概是 121033877。这个数字相比于 CPU 每秒的频率也太小了吧。当然真实的数字是可以大到爆掉 UInt64 的,内核肯定做了 scaled,所以内核到底是怎么实现的呢?
主要实现在 osfmk/kern/processor.c 里的以下方法:
kern_return_t
processor_info(
processor_t processor,
processor_flavor_t flavor,
host_t *host,
processor_info_t info,
mach_msg_type_number_t *count)
switch-case 一下遇到 PROCESSOR_CPU_LOAD_INFO 后直接去读取相应的数值。
cpu_load_info = (processor_cpu_load_info_t) info; if (precise_user_kernel_time) { // #define PROCESSOR_DATA(processor, member) \ // (processor)->processor_data.member // processor 通过 osfmk/kern/processor.h 定义的全局变量来取,这里相当于读 processor->processor_data.user_state // timer_data_t user_state; // 拿到 user_state 之后再除以 hz_tick_interval // 在 osfmk/kern/clock.c 的实现中 hz_tick_interval 等于 NSEC_PER_SEC / 100,也就是 1/100 纳秒 cpu_load_info->cpu_ticks[CPU_STATE_USER] = (uint32_t)(timer_grab(&PROCESSOR_DATA(processor, user_state)) / hz_tick_interval); cpu_load_info->cpu_ticks[CPU_STATE_SYSTEM] = (uint32_t)(timer_grab(&PROCESSOR_DATA(processor, system_state)) / hz_tick_interval); } else { uint64_t tval = timer_grab(&PROCESSOR_DATA(processor, user_state)) + timer_grab(&PROCESSOR_DATA(processor, system_state));cpu_load_info->cpu_ticks[CPU_STATE_USER] = (uint32_t)(tval / hz_tick_interval); cpu_load_info->cpu_ticks[CPU_STATE_SYSTEM] = 0;
}
hz_tick_interval = 1000000000ull / 100 也就是 10^7,所以我们得到的结果被缩小了 10^7 倍,也就解释了为什么数字这么小了。
2019-11-1 updated: 后来我发现这里理解 tick 有问题
上面 host_processor_info() 获得的数字是内核时钟的 tick,在 XNU 里 hardcoded 为:
/* * The hz hardware interval timer. */
int hz = 100; /* GET RID OF THIS !!! / int tick = (1000000 / 100); / GET RID OF THIS !!! */
也就是一秒钟有 100 ticks,每个 CPU 核心(虚拟)自行计算,我取了其中一个的数据可以算出 3.8hr,同时打印 uptime 为 4hr 56m,略少一点。这是因为当系统 sleep 的时候 CPU 是不计算 ticks 的。所以这个计算是正确的,目前 tick 就是 hardcoded 为 100 次每秒。
顺便这两句 GET RID OF THIS !!! 的注释跟其他的 XXX 注释一样蜜汁幽默。
在 processor_info() 函数里还有这么一段注释:
/*
* We capture the accumulated idle time twice over
* the course of this function, as well as the timestamps
* when each were last updated. Since these are
* all done using non-atomic racy mechanisms, the
* most we can infer is whether values are stable.
* timer_grab() is the only function that can be
* used reliably on another processor's per-processor
* data.
*/
大意是由于 idle 状态下的 processor 不会经常更新自己的 idle time,所以在该函数内针对 idle 这个数值,判断 idle state 与否并取了两次 idle time 和 time stamp,比较一下再返回给上层。
// 取一下 idle 的 timer idle_state = &PROCESSOR_DATA(processor, idle_state); // 取第一次 idle state 数据 idle_time_snapshot1 = timer_grab(idle_state); // 取第一次时间戳 idle_time_tstamp1 = idle_state->tstamp;if (PROCESSOR_DATA(processor, current_state) != idle_state) { // 如果当前核心不在 idle 状态,那就是忙咯,忙就说明会经常更新,那么可信赖,直接用 cpu_load_info->cpu_ticks[CPU_STATE_IDLE] = (uint32_t)(idle_time_snapshot1 / hz_tick_interval); } else if ((idle_time_snapshot1 != (idle_time_snapshot2 = timer_grab(idle_state))) || (idle_time_tstamp1 != (idle_time_tstamp2 = idle_state->tstamp))){ // 如果是 idle 状态,再抓一次 state 和 timestamp 看看数据是否一致 // 由于此时数据有可能是并发更新的,那么第二次的数据比较新,有可能是更值得信赖的数据,用第二个 cpu_load_info->cpu_ticks[CPU_STATE_IDLE] = (uint32_t)(idle_time_snapshot2 / hz_tick_interval); } else { // 这里同样是 idle 状态,但是数据没有变化,那么大概率没有在并发更新,数据是稳定的,也可以直接用上 idle_time_snapshot1 += mach_absolute_time() - idle_time_tstamp1;
cpu_load_info->cpu_ticks[CPU_STATE_IDLE] = (uint32_t)(idle_time_snapshot1 / hz_tick_interval);
}
这样忙时的数据和 idle 数据都有了,nice 数据就是 hardcode 的 0
cpu_load_info->cpu_ticks[CPU_STATE_NICE] = 0;
关于 NICE
在历史上 Unix 系统有一个 nice 状态用来表示一个进程的执行优先级,-20 最高,19 最低。但是 Apple 的 Darwin-XNU 现在已经弃用了。我试了一下 htop 在 Mac 上的 NI 一列全是 0,但是在 Ubuntu 上 NI 一列有 0, -20, 19, 5 各种数字都有。可以参考阅读维基百科或者这篇文章。
timer_grab 方法留意到上面的注释里有一句:
timer_grab() is the only function that can be used reliably on another processor's per-processor data.
此时使用 timer_grab() 函数是唯一可以读取另外一个 processor 的 per-processor data 也就是 processor->processor_data。但是为什么呢?为什么 timer_grab() 是唯一可靠的函数呢?
我们看看 timer_grab() 方法的定义:
/*
* Read the accumulated time of `timer`.
*/
#if defined(__LP64__)
static inline
uint64_t
timer_grab(timer_t timer)
{
return timer->all_bits;
}
#else /* defined(__LP64__) */
uint64_t timer_grab(timer_t timer);
#endif /* !defined(__LP64__) */
在 64 系统上用静态内敛函数在头文件里实现了,直接返回 all_bits。在非 64 位系统则只是声明没有实现。我搜了整个 XNU 开源代码也没有实现。但是有另一个版本实现可以参考一下:
static uint64_t safe_grab_timer_value(struct timer *t)
{
#if defined(__LP64__)
return t->all_bits;
#else
uint64_t time = t->high_bits; /* endian independent grab */
time = (time << 32) | t->low_bits;
return time;
#endif
}
其实这个 if-else 的区别只是因为 64 位和 32 位的区别而已:
struct timer {
uint64_t tstamp;
#if defined(__LP64__)
uint64_t all_bits;
#else /* defined(__LP64__) */
/* A check word on the high portion allows atomic updates. */
uint32_t low_bits;
uint32_t high_bits;
uint32_t high_bits_check;
#endif /* !defined(__LP64__) */
};
在 32 位系统上,内核用两个 uint32_t 来分开记录高位和低位数值,然后返回的时候拼成一个大的 64 位 uint64_t。一开始我以为 timer_grab() 是为了线程安全之类的,但是大家都只是读数值又不是写操作,而且看这个 safe 版本的实现,跟线程安全什么的没关系。所以应该只是因为要兼容,timer_grabe() 才是 only function。
Timer 计时的地方有点多,我还需要理解内核时钟的原理只能知道细节,这里大概看一下 Timer 的数据结构和 API。
struct timer {
uint64_t tstamp;
uint64_t all_bits;
};
非 64 位的直接不看了,原理是一样的,存储结构不同而已。最关键的是 tstamp 这个 time stamp。 timer_start() 时会记录当前时间戳,timer_stop(), timer_update(), timer_switch() 都会调用 timer_advance(),计算两次时间戳的差异,加到 all_bits 上面。
所以简单理解就是每次 CPU 把分配给了 user 或者 system 的时候,就会开启对应 timer 的计时,可以在二者之间切换时,或者闲时之类的变化就改变 timer 状态,更新计时数据。
传入的时间从 mach_absolute_time() 获得。
这个时间的实现 arm 和 i386 还不一样。
1386 的最终会到这里:
static inline uint64_t
rtc_nanotime_read(void)
{
return _rtc_nanotime_read(&pal_rtc_nanotime_info);
}
不过 _rtc_nanotime_read() 没有 C 实现,可能是汇编实现。但是反正读的是当前的 RTC 时间,以纳秒为单位。
arm 的实现则是:
uint64_t mach_absolute_time(void) { return ml_get_timebase(); }
uint64_t ml_get_timebase() { return (ml_get_hwclock() + getCpuDatap()->cpu_base_timebase); }
为什么要两者相加呢?因为 cpu_base_timebase 在初始化的赋值是这样的:
if (!from_boot && (cdp == &BootCpuData)) {
/*
* When we wake from sleep, we have no guarantee about the state
* of the hardware timebase. It may have kept ticking across sleep, or
* it may have reset.
*
* To deal with this, we calculate an offset to the clock that will
* produce a timebase value wake_abstime at the point the boot
* CPU calls cpu_timebase_init on wake.
*
* This ensures that mach_absolute_time() stops ticking across sleep.
*/
rtclock_base_abstime = wake_abstime - ml_get_hwclock();
}
cdp->cpu_base_timebase = rtclock_base_abstime;
rtclock_base_abstime 这个就是 uint64_t 的 RTC 时间,保存在 rtclock_data_t 的 rtc_base 结构体里,也是纳秒。
extern rtclock_data_t RTClockData;
#define rtclock_base_abstime RTClockData.rtc_base.abstime
这个初始化函数 void cpu_timebase_init(boolean_t from_boot) 会被调用多次,系统启动的时候可以直接取 rtclock_base_abstime,但是如果从睡眠中唤醒,有可能时钟已经不跑了,所以要计算一个差值。
初始化是 rtclock_base_abstime 为 0。在所有核心 sleep 时 ml_arm_sleep(void) 函数记录一个时间到 wake_abstime。这个值通过 ml_get_timebase() 获取,此时如果从未 sleep 过则为硬件时钟时间 ml_get_hwclock()。
当 CPU 被唤醒时计算差值 wake_abstime - ml_get_hwclock(),保存到 cpu_base_timebase。
这样当你读取 ml_get_timebase() 时就加上这段差值,结果得到的是上一次保存的 wake_abstime,相当于从上一次 sleep 的地方开始继续往前 tick。
虽然注释说有可能 hwclock() 在睡眠期间会继续 tick 也有可能不会,所以要修正,不过我还不清楚修正是为了什么。可能内核需要用到这个时间来做些什么事情吧。
回到一开始用 host_processor_info() 的数据来计算占用率不准问题,因为我们用的是历史数据,我们应该关注的是一小段时间内的 CPU 数据,比如取时间 t1 和时间 t2 的 cpu load,然后作差值。这个差值就反应了 t1 到 t2 之间 CPU 的占用情况。所以修正一下上面的做法,只需要取两次样本,然后相减,得到的数据再做一次忙时除以全部的 ticks 就能得到 CPU 占用率了。
Hammerspoon 里提供了一个用 LUA 封装的简单采用方法 hs.host.cpuUsage([period], [callback]) -> table 可供使用。
源码可以参考这里。
local convertToPercentages = function(result1, result2)
local result = {}
for k,v in pairs(result2) do
if k == "n" then
result.n = v
else
result[k] = {}
for k2, v2 in pairs(v) do
result[k][k2] = v2 - result1[k][k2]
end
local total = result[k].active + result[k].idle
for k2, _ in pairs(result[k]) do
result[k][k2] = (result[k][k2] / total) * 100.0
end
end
end
for i,v in pairs(result) do
if tostring(i) ~= "n" then
result[i] = setmetatable(v, { __tostring = __tostring_for_tables })
end
end
return result
end
非常简单地两个结果作差值。
本文从 iOS 和 Mac 取 CPU 占用率的接口出发,简单介绍了 Time Base 的概念,RTC 时钟,内核层维护 space 和 table 以记录 mach port 和进程相关信息,CPU Ticks 等内核层用到的东西。
操作系统越是往下走跟硬件设计打交道的东西就越多。平时做顶层面向用户的 App 开发基本不会碰到这些东西。对于 CPU 占用率这种代码,到 stackoverflow 抄一下就能用了。这并没有问题,但是探求一个系统接口的实现,寻找知其所以然的过程也十分有趣。
系统内核的实现有些地方需要高超的算法能力,比如线程调度模型,有些地方需要追去稳定,还有些地方可能用了 C/C++ 的语法糖之类的,看起来有点困难。但实际上和平时开发一个 App 需求的路子是一样的,就是分析一个问题,找到一个问题的解决方法而已。
当然了阅读和理解内核代码很容易,但是实践写出一个内核却是难如登天的一件事情,不仅非常强算法能力,也要求具备大型项目的管理能力。所以虽然我写不了内核,看一看这些神秘的 API 背后的实现也是很有意思的。
updated: osfmk 目录下的代码就是 Mach 内核部分,由于进程是在 Mach 内核实现的,所以我们可以通过 Mach 内核接口获取相关信息。host_info() 类型的接口都由 Mach 内核提供。