
这是一个创建于 786 天前的主题,其中的信息可能已经有所发展或是发生改变。
wget https://github.com/xiexiexx/PPLA/raw/main/billionsort/billionsort.cpp
clang++ -O3 billionsort.cpp
./a.out
- redmi note12t 7+gen2 16+1t miui14.0.25 termux witout root
有没有 8gen3 和 9300 的老哥跑一下让我长长见识
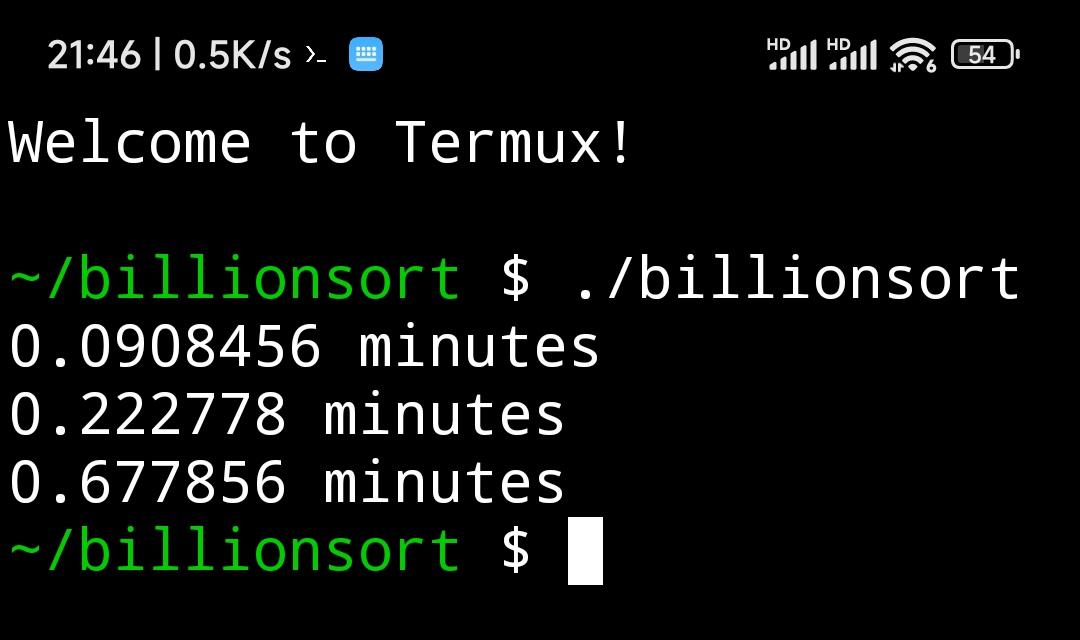
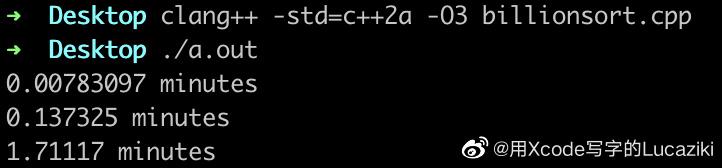
- iphone11 a13 4+128g ios17.1.1 a-shell 跑的 1 亿
[Documents]$ ./1x_millionsort_with_output 100
Data size: 100000000
0.0027 minutes
0.02695 minutes
0.478667 minutes
- 7700k 32g xubuntu2204
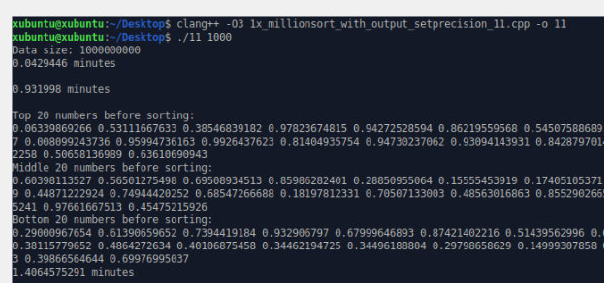
第 1 条附言 · 2023 年 11 月 26 日
- 浮点性能快表达不准确,换个问题,为啥这台手机上这么快呢?
 |
1
pubby 2023 年 11 月 24 日
$ uname -a
Darwin Mac-mini.local 22.6.0 Darwin Kernel Version 22.6.0: Wed Oct 4 21:25:26 PDT 2023; root:xnu-8796.141.3.701.17~4/RELEASE_X86_64 x86_64 $ sysctl machdep.cpu.brand_string machdep.cpu.brand_string: Intel(R) Core(TM) i9-9900T CPU @ 2.10GHz $ ./a.out 0.0942143 minutes 0.277907 minutes 2.31389 minutes |
 |
4
kikitte 2023 年 11 月 24 日
AMD 5950x ArchLinux
[kikitte@archlinux test]$ clang++ -O3 billionsort.cpp [kikitte@archlinux test]$ ./a.out 0.0128345 minutes 0.954518 minutes 1.46679 minutes |
 |
5
hefish 2023 年 11 月 24 日
这个 sort 也跟 cpu 线程数有关吧
|
 |
6
penzi 2023 年 11 月 24 日
首先这个 sort 是单线程的
|
 |
7
lslqtz 2023 年 11 月 24 日
M1 Pro 感觉差不多.
这是单核浮点吧. |
 |
10
beetlerx 2023 年 11 月 24 日
OS: Debian GNU/Linux trixie/sid x86_64
CPU: AMD Ryzen 7 7840H w/ Radeon 780M Graphics (16) @ 5.137GHz $ clang++-16 -std=c++2a -O3 ./billionsort.cpp $ ./a.out 0.00709458 minutes 0.757148 minutes 1.45406 minutes 看起来 7840H 单核浮点可以和 5950x 掰掰 |
 |
11
Philippa 2023 年 11 月 24 日
.., larry@DESKTOP-OVBIJM9
....,,:;+ccllll --------------------- ...,,+:; cllllllllllllllllll OS: Windows 10 רҵ□□ x86_64 ,cclllllllllll lllllllllllllllllll Host: ASUS llllllllllllll lllllllllllllllllll Kernel: 10.0.19045 llllllllllllll lllllllllllllllllll Uptime: 14 hours, 59 mins llllllllllllll lllllllllllllllllll Packages: 3 (scoop) llllllllllllll lllllllllllllllllll Shell: bash 5.2.15 llllllllllllll lllllllllllllllllll Resolution: 3840x2160 DE: Aero llllllllllllll lllllllllllllllllll WM: Explorer llllllllllllll lllllllllllllllllll WM Theme: Custom llllllllllllll lllllllllllllllllll Terminal: Windows Terminal llllllllllllll lllllllllllllllllll CPU: AMD Ryzen 9 7950X3D (32) @ 4.200GHz llllllllllllll lllllllllllllllllll GPU: Caption `'ccllllllllll lllllllllllllllllll GPU: NVIDIA GeForce RTX 4090 `' \*:: :ccllllllllllllllll GPU ````''*::cll Memory: 16818MiB / 130802MiB `` clang++ -std=c++2a -O3 main.cpp 0.0153925 minutes 0.683383 minutes 1.30065 minutes 不是很懂,为什么这么慢 |
|
14
penzi 2023 年 11 月 24 日
|
|
16
penzi 2023 年 11 月 24 日 这能叫做"浮点性能"吗,下面的回帖很多人也被误导了
|
 |
20
bigtan 2023 年 11 月 24 日
我这个 14700KF 怎么这么慢
0.0179123 minutes 0.263897 minutes 3.26288 minutes |
 |
24
lwjef OP @maggch97 #22 ...跑了好多次 可以参考这里 https://weibo.com/5819320755/NtlsOeNah
|
 |
26
forgottenPerson 2023 年 11 月 25 日 via Android
Xiaomi 11 termux without root
0.133285 minutes 0.286336 minutes 1.66493 minutes |
 |
29
billlee 2023 年 11 月 25 日
这和浮点有关系吗?测的是缓存和内存性能
|
|
31
Philippa 2023 年 11 月 25 日
7950x3D 加了编译优化后……
clang++ -std=c++2a -O3 -Ofast -march=native -funroll-loops -flto main.cpp 0.0153663 minutes 0.0828322 minutes 1.29281 minutes |
 |
32
nuk 2023 年 11 月 25 日
感觉和浮点数的精度有关,建议生成 1.0 2.0 3.0 ...的浮点数组,然后用整数随机数把他们打乱。如果随机数分布均匀的话,排序时间应该是稳定的。
|
 |
33
felixlong 2023 年 11 月 25 日
分配 7.5G 内存。然后只字不提每台设备的内存大小,那还比个毛线啊。
|
 |
34
BBBOND 2023 年 11 月 25 日 via Android
s23 跑完闪退了,爆内存了吧
|
|
35
bigtan 2023 年 11 月 25 日
|
 |
36
xiaotianhu 2023 年 11 月 25 日
2017 的 16 寸 MBP ,2.6G 的 i7-6920HQ
0.069159 minutes 0.151773 minutes 2.32275 minutes 比手机都慢啊~ |
 |
37
xiaofeilongyy555 2023 年 11 月 25 日
xiaomi 13ultra 8gen2 16+512 termux without root 性能模式
0.0415852 minutes 0.114332 minutes 0.441386 minutes |
|
38
xiaofeilongyy555 2023 年 11 月 25 日
13u 清理缓存后有进一步提升
0.0221216 minutes 0.118988 minutes 0.465569 minutes |
 |
39
L4Linux 2023 年 11 月 25 日 via Android
用标准库里面的函数来比 fpu 性能没啥意义。
|
 |
40
bsfx2 2023 年 11 月 25 日
基础款 M3 (24 GB)
$ ./a.out 0.00883733 minutes 0.108414 minutes 1.31298 minutes |
|
41
penzi 2023 年 11 月 25 日
@xiaofeilongyy555 和楼主一样的 cortex X2 的大核,那看来这个核心跑这个任务异乎寻常的快。比上面另一个小米 11 888 的 cortex x1 快了不止一倍
|
|
42
xiaofeilongyy555 2023 年 11 月 25 日
@maggch97 8gen2 用的是 3.2 GHz – Cortex-X3 ,888 是 2.84GHz (Cortex-X1)
|
|
43
penzi 2023 年 11 月 25 日
@xiaofeilongyy555 不知道有没有非小米机型的数据
|
|
44
lwjef OP |
 |
46
lovestudykid 2023 年 11 月 25 日
看到 iPhone 11 比 M1 Max 快的时候就应该明白一定是哪里出了问题
|
|
47
lovestudykid 2023 年 11 月 25 日
@lovestudykid 看错了,跑的不是一个东西...
|
 |
48
tool2d 2023 年 11 月 25 日
2014 年的 PC 电脑
0.021993 minutes 0.132118 minutes 1.66888 minutes 打不过年轻人了。 |
 |
49
msg7086 2023 年 11 月 25 日
浮点性能不是应该看 AVX/AVX512 之类 SIMD 跑浮点的性能吗?
|
|
50
L4Linux 2023 年 11 月 25 日 via Android
@lwjef 先控制一下变量吧。你难不成觉得 std::vector 实现都是一样的、而且是 header only 的?
|
 |
51
c0xt30a 2023 年 11 月 25 日
单线程,而且是 sort ,跟浮点数表现无关,主要看 CPU 频率的样子。
|
 |
52
katsusan 2023 年 11 月 25 日
同 arch 比较,像 Zen 和 xxLake 看指令吞吐延迟. 如果是 x86 和 arm 相比,这时候都是 tight loop,x86 的前端解码瓶颈被弱化,应该不会比 arm 阵营差那么多.
|
 |
53
dahakawang 2023 年 11 月 25 日
7.4G 的数据量,即便不考虑内存不够的情况,也有可能是内存性能 bounded 的原因,不妨试试比较用 cache 大小的数据量进行多轮 benchmark ?
|
 |
54
iwdmb 2023 年 11 月 25 日
$ lscpu | grep Model\ name
Model name: 13th Gen Intel(R) Core(TM) i7-13700K $ ./billionsort 0.0281303 minutes 0.0913962 minutes 1.14076 minutes |
|
55
iwdmb 2023 年 11 月 25 日
 |
 |
56
Rorysky 2023 年 11 月 25 日
莫非你是 算法老师?
|
 |
57
e3c78a97e0f8 2023 年 11 月 25 日
浮点性能都是看加减乘除乃至线性代数的,哪有用浮点数比较来定义浮点性能的
|
 |
58
Donahue 2023 年 11 月 25 日
|
|
59
lwjef OP 浮点性能快表达不准确,换个问题,为啥这台手机上这么快呢?
@msg7086 #49 是的,高通这么快可能是 Hexagon DSP 有加速 @L4Linux #50 具体细节我是真不懂,但是快是为啥 @c0xt30a #51 高通的频率也不是最强的啊 @katsusan #52 高通和苹果 m1 比数据上也有差距 @dahakawang #53 高通的内存性能从前两个时间来看相较 x86 和 m1 不太行,为啥最后一个时间那么短。。。 @Rorysky #56 这个程序是算法老师写的,估计是为了测试 std::sort 的时间复杂度是线性对数 O(nlogn) @e3c78a97e0f8 #57 是的,是我表达错误,你说的没问题 |
|
60
billlee 2023 年 11 月 26 日
会不会是随机数生成器有区别,先预先生成一个固定的数据序列保存在文件里,各个平台用同一份数据跑排序试试?
|
 |
61
cyy911 2023 年 11 月 26 日
M3MAX
0.00784537 minutes 0.113421 minutes 1.39678 minutes |
|
62
cyy911 2023 年 11 月 26 日
8Gen3
0.0407101 0.131629 2.03484 是不是降频了啊 |
 |
63
holulu 2023 年 11 月 26 日
随机生成的数组乱序程度都不一样,std::sort 的排序过程也不一样。这个代码即使在同一个机器上跑多次,结果都会差距很大。应该用同一份数据在不同机器上跑的结果来比较才有意义。
|
 |
64
paopjian 2023 年 11 月 26 日
risc 短指令的优势?试试有没有其他高级指令的?
|
 |
65
xixun 2023 年 11 月 26 日 via iPhone
高通有堆浮点吧,跑分好看
|
 |
66
hez2010 2023 年 11 月 26 日
Windows 11, i7-13700K, DDR5 内存但频率只有 4000MHz:
msvc /O2: 0.0217156 minutes 0.072249 minutes 1.54053 minutes clang -O3: 0.021577 minutes 0.0523916 minutes 1.54663 minutes |
 |
67
memorycancel 2023 年 11 月 27 日
12th Gen Intel(R) Core(TM) i9-12900T
❯ ./a.out 0.0288894 minutes 0.760386 minutes 1.34341 minutes |