
这是一个创建于 798 天前的主题,其中的信息可能已经有所发展或是发生改变。
众所周知,openai 太强了,以至于现在谈 AI 基本就等同于谈 chatGPT 或 GPT4 ,但是呢,我个人的感情很复杂,一方面我是 chatGPT 的重度用户,也很喜欢 openai ,但是,我依然不希望看到未来是一个只有 openai 的世界
在几个月前我曾经用 chatglm-6b 训练过我自己的数字克隆: https://v2ex.com/t/931521#reply161
此后的开源模型开始井喷,但其质量和 GPT 的差距依然巨大,我开始琢磨,能否通过微调的方式来增加开源通用大模型在某些垂直领域的表现,在尝试的过程中,我意识到,如果不降低训练的门槛,那这个可能性微乎其微,然后我和几个朋友就开始以兼职,远程,业余时间的方式完成了这个低门槛进行文本大模型训练微调的 Saas
这就是模迪手: https://www.modihand.com (好的我也是硅谷的粉丝,我心头的美剧前三
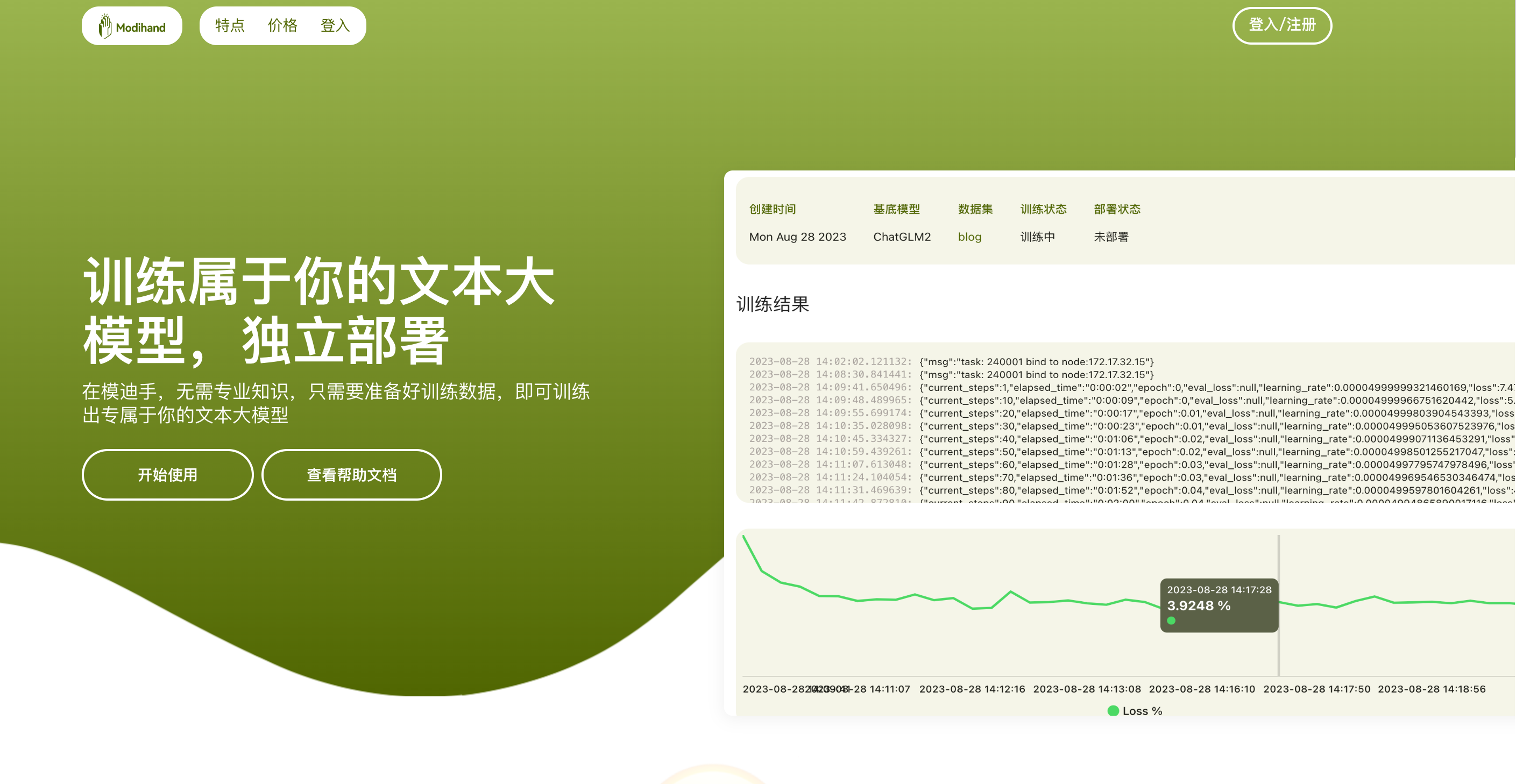
因为这是 V2EX ,所以我想我应该不用再详细说明训练和 embedding 的区别,虽然有很多人说「训练」的时候其实是在说 embedding 和 prompt 工程,但两者本质上就是完全不同的。训练改变了模型的参数,而 embedding 没有,只是从知识库匹配一段文本放到 prompt 里一起给模型。
模迪手简单易用,只需要准备好数据集,在网页上点点点,然后就可以训练了,训练完成后的模型,可以在线调用,也可以直接导出模型文件。
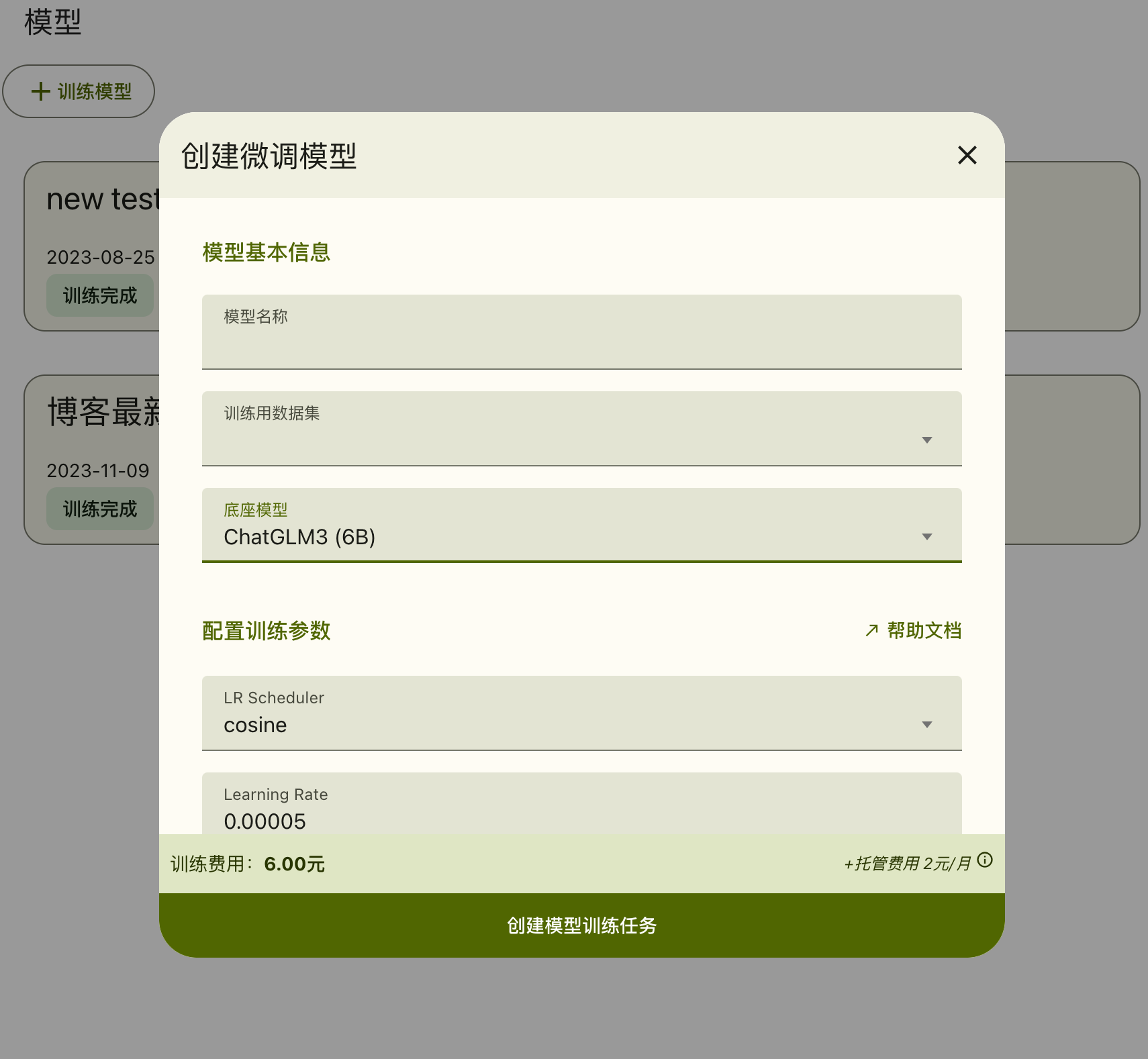
它的一些特点包括:
- 几乎无门槛实现文本模型训练
- 支持多种预置基底模型
- 无需担心算力,环境部署等问题
- 模型可代部署,支持 API 接口
- 所有模型均提供完整的导出(可部署在自己的 PC 或显卡服务器上)
当然目前也存在一些问题:
- 国内访问较慢
- 部分超参数不支持控制
- 很多基底模型还没有支持
- 文档完善度 60%
- 定价策略比较粗糙
考虑到现在 openai 的强大,这个拥抱开源大模型的项目其实前景很不确定,但我觉得它至少帮我解决了很多问题,我也觉得需要有这么一个东西(我还没有看到类似的)
如果大家有有趣的想法或者有意思的数据集,可以评论或直接通过这个表单填写一下,我们可以提供模迪手的免费算力,让你能够训练出来玩玩看(我之前的一个不算太成功的例子: https://v2ex.com/t/945834#reply18
 |
1
nnccree 2023 年 11 月 14 日
为啥网站没有加上英文,面向海外用户?
|
 |
3
my6777637 2023 年 11 月 14 日
好酷,先 mark ,后面玩玩
训练好后,对外服务的接口会和 openai 的接口保持一致吗?(方便平替) |
 |
4
vulgur 2023 年 11 月 14 日
Always blue !
|
 |
5
graetdk OP @my6777637 感谢!我们提供的接口并不建议用于实际业务,仅仅是提供一个测试,后续可能会有更稳定的部署系统,但还是推荐用户训练好模型之后下载,自己部署
|
 |
7
milukun 2023 年 11 月 14 日
COOL
|
 |
8
cijianzy 2023 年 11 月 14 日
吼!
|
 |
10
nno 2023 年 11 月 14 日
微调没啥价值,会严重损坏模型的性能
|
|
11
graetdk OP @nno 之前的模型微调后丧失某一方面能力的情况比较明显,但现在的模型都好了很多,另一方面如果需要加强的是模型的特定能力,那损失其它(不需要的)泛化能力也不是不能接受
|
12
jr55475f112iz2tu 2023 年 11 月 14 日
感觉有点看头
我看文档里的训练集举例都是一问一答的知识性对话,如果是像动画里的连续多轮对话数据,也可以作为训练集吗? |
 |
14
titanhw 2023 年 11 月 14 日
希望可以加入 qwen-14b 模型,这个模型对比起来效果还是可以的
|
 |
16
baka 2023 年 11 月 15 日
智谱和百川的模型拿到商业化授权了吗?
|
17
jr55475f112iz2tu 2023 年 11 月 15 日
@graetdk 可以举个例子吗?
|
|
18
graetdk OP @baka 虽然拿到了,但是其实我觉得这个不需要商业授权,因为本质上是算力服务,类似于某些云服务器提供模型镜像或者 GUI 给你操作差不多
|
 |
19
LeoSpeaker 2023 年 11 月 15 日
大文本生成模型 推荐用哪个模型呢?
|
|
20
graetdk OP @LeoSpeaker 我个人是 chatGLM 的粉丝,并且目前我觉得 chatGLM3 是比较不错的
|
 |
21
w9ay 2023 年 11 月 15 日
现在是有多少显卡支撑这个网站?
|
|
22
LeoSpeaker 2023 年 11 月 17 日
@graetdk 还请教您个问题,目前我也在研究了下 chatGLM ,确实很好用,请问您当前的训练是多少显卡呢?
|
 |
23
Eacls 2023 年 12 月 12 日
我也是硅谷的铁粉,Pied Piper 反复的起起伏伏作为同样是创业者来看真的是精彩和刺激,当年的光荣岁月到最后却像是一点痕迹都没有留下过一样。Always blue ~ Always blue !
|