
这是一个创建于 1727 天前的主题,其中的信息可能已经有所发展或是发生改变。
昨天突然想起某天看到微信读书(记忆不清了)为了防止用户复制,采用了一种方式,把每个字都绝对定位,从而达到视觉上通顺,实际上是乱序的。大概如下图所示。
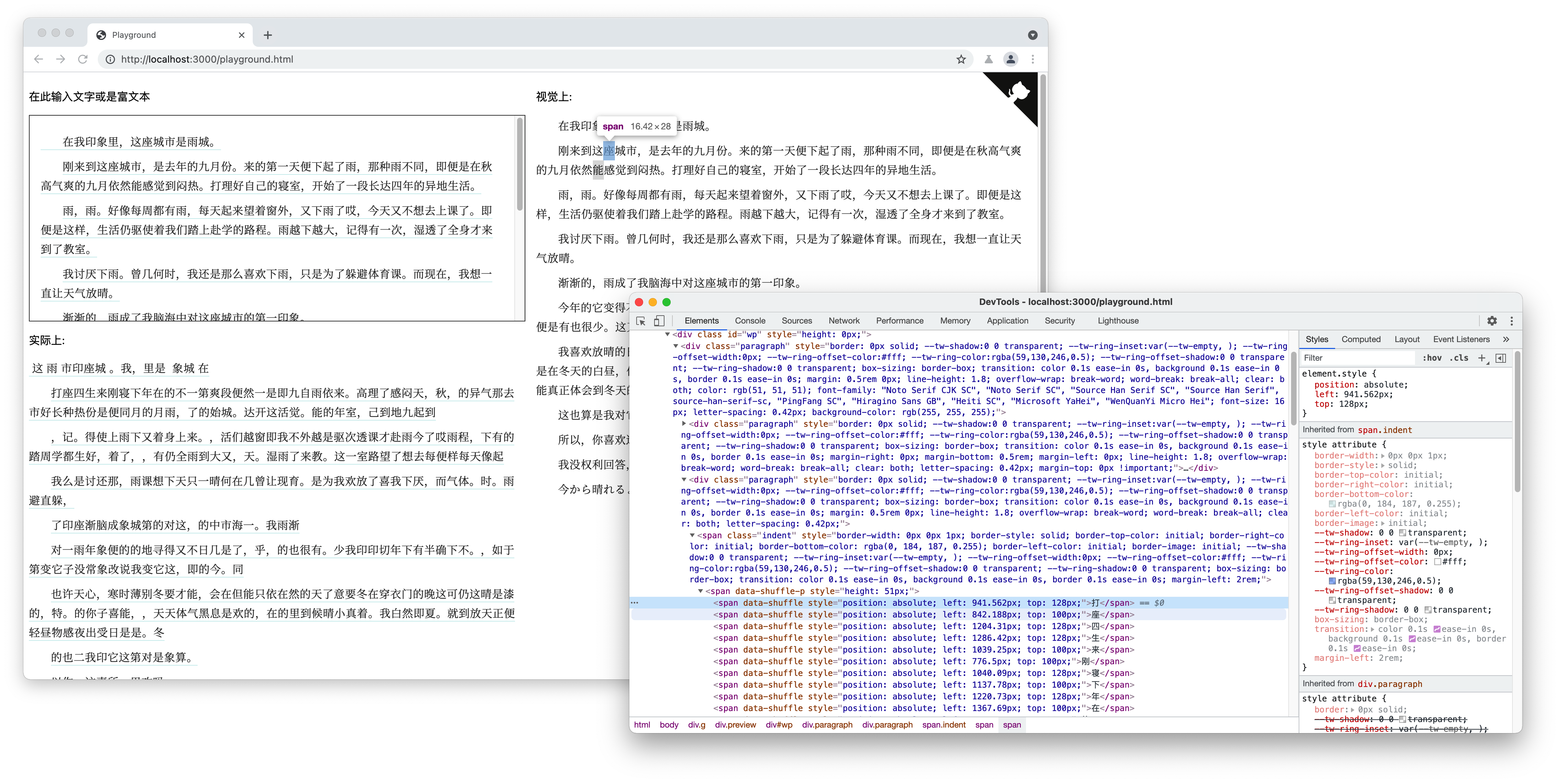
然后我尝试用 OCR 软件去识别,标准字体的话准确率很高不稀奇。我又换了一个手写体去试。macOS 自带的手札体。
意外发现不规则字体识别率也很高。
 |
1
Maboroshii 2021 年 5 月 12 日
有意思
|
 |
2
imdong 2021 年 5 月 12 日
之前做过一个小说网站的识别,也是类似的方式,我的做法是:
从 html 中取出每个字的位置,然后按行列排序,最后重新整理顺序就可以还原了. 而且从你截图来看的话,比那个网站还少了基础 css 样式偏移,那个是每个字都有一个 class 和 style 的,两个变量的漂移相加的. |
|
3
Maboroshii 2021 年 5 月 12 日
不过试了下浏览器缩放,混淆后的内容的位置就跑了
|
 |
4
tukon479 OP @Maboroshii 对,因为绝对定位,所以 resize 要加监听器,重新计算
|
 |
6
est 2021 年 5 月 12 日
2012 年,cv 届发生了一件大事,人类的命运就从此发生了巨大改变。以至于到了 9 年后的今天,LZ 才发帖感叹技术进步如此之快
|
|
7
imdong 2021 年 5 月 12 日
(content => {
let span_list = content.querySelectorAll('span'), map = [], full_text = ""; span_list.forEach(span => { let left = parseInt(span.style.left), top = parseInt(span.style.top); map[top] = map[top] || []; map[top][left] = span.innerText; }); map.forEach(line => { line.forEach(text => { full_text += text }); }) console.log(full_text) })(document.getElementById('renderTargetContent')) |
 |
8
goodryb 2021 年 5 月 12 日
居然还有这种操作,第一次听说
|
 |
9
murmur 2021 年 5 月 12 日
如果考虑到做字体替换和位置改动的,应该也有其他反扒策略把
|

|
13
tukon479 OP @q197 mac 上的 TextSniper https://textsniper.app/
|