
这是一个创建于 1752 天前的主题,其中的信息可能已经有所发展或是发生改变。
书上说的不是很清楚,只说是编译器优化的结果。具体是什么原因呢?编译器再怎么优化 ready=true 不还得执行吗,怎么 while(!ready)就退出不了了呢?
public class NoVisibility {
private static boolean ready;
private static int number;
private static class ReaderThread extends Thread {
public void run() {
while (!ready);
System.out.println(number);
}
}
public static void main(String[] args) throws InterruptedException {
new ReaderThread().start();
Thread.sleep(1000);
number = 42;
ready = true;
Thread.sleep(10000);
}
}
 |
1
oska874 2021 年 4 月 3 日
while ( ready )直接优化成 while ( 1 )了,执行的时候和 ready 已经没关系了。
|
 |
2
lsry 2021 年 4 月 3 日 因为你 ready 在新建的线程和 main 线程中各有一个备份,在 main 线程中修改 ready 无法修改你新建线程的 ready 备份,如果让你新建的线程看到 main 修改的值,在前面加 volatile 即可。
|
 |
3
az467 2021 年 4 月 3 日
月经问题。。。
不是编译器优化,是 jvm 优化。 你没把 jvm 的 jit 关掉,所以 jvm 把 while (!ready); 优化成了 if (ready == false) while (true); |
 |
4
Kasumi20 2021 年 4 月 3 日
确实不是不是编译器优化,反编译回来是原来的代码。
那究竟是 2 楼还是 3 楼说的对呢 |
 |
5
PythonYXY 2021 年 4 月 3 日
建议了解下 Java 内存模型( JMM )
|
 |
6
ipwx 2021 年 4 月 3 日
没学过 Java,但是最近我写 C++,碰到这种多线程读写指示变量,我都是上 std::atomic 的。。。
|
 |
7
JohnZorn 2021 年 4 月 3 日
二楼说的对,Ready 要保证内存可见性
|
 |
8
Jooooooooo 2021 年 4 月 3 日
搜一下 jmm 有真相.
具体说和多核 cpu 看不见其它 cpu 的值有关系 ready=true cpu1 执行完, 执行 while(!ready) 的 cpu2 看不见 |
 |
9
yitingbai 2021 年 4 月 3 日
2 楼的解决方案没问题, 另外我试了一下,while()中写一行代码也可以停, java 搞了这么久, 今天学到了
|
 |
11
RicardoY 2021 年 4 月 3 日 via iPhone
可见性 看一下 Java 内存模型
|
|
12
RicardoY 2021 年 4 月 3 日 via iPhone
你 sleep 一下其实也可以 但是不知道为什么 sleep 可以 原子变量 /加锁 /volatile 是可以的
|
|
13
az467 2021 年 4 月 3 日 @ignor
了解一下 JMM,你就会知道这种优化非但没有错误,反而完全是正确的。 因为变量没有被 volatile 修饰,所以 jvm 不用保证变量在线程间的可见性。 既然不用保证,那当然可以完全不保证,甚至可以反过来“保证”变量完全不可见。 这就像很多人开了 gcc 的 O3 优化,然后惊奇地发现程序运行结果跟自己预期不一致。 不好意思,是你把代码写错了。 |
 |
14
brucewuio 2021 年 4 月 3 日
volatile 咯 内存可见性
|
 |
15
ignor 2021 年 4 月 3 日 via Android
@az467 感觉还是没太理解……
我所了解到的可见性,是指线程对变量的修改,能够“及时地”被其他线程所看到 所以 volatile 解决的应该是“及时地”的问题,而不是“能不能”的问题,也就是说,即使没有 volatile,这种修改也应该“能够”被观察到,只是时间上有延迟而已。因为它是个变量,应该是可以被修改的,所以这种“能够”不应该被优化掉才对吧? |
 |
17
ZeawinL 2021 年 4 月 3 日 via Android
这里是两个线程,线程 1 赋值后对线程 2 未必可见。
|
 |
19
wwqgtxx 2021 年 4 月 4 日 via iPhone
@ignor 因为作为优化器,并不能(准确说是并不会去)预测是否会有其他线程修改该变量,所以只要当前线程没不会有对该变量的修改操作,就能直接认定为该变量为常量
|
 |
20
francis59 2021 年 4 月 4 日 空循环被 JIT 优化了,禁用 JIT 就行,加 JVM 参数-Xint,在解释模式运行
|
|
21
francis59 2021 年 4 月 4 日
-Xint
Operate in interpreted-only mode. Compilation to native code is disabled, and all bytecodes are executed by the interpreter. The performance benefits offered by the Java HotSpot Client VM's adaptive compiler will not be present in this mode. |
 |
22
iseki 2021 年 4 月 4 日 via Android
你在那个 while 里 println 或者干点啥,多半就发现 ready 起作用了,所以我觉得不是 jit 优化了 ready,单纯缓存的问题
|
 |
24
lewis89 2021 年 4 月 4 日 是虚拟机的激进编译的问题,虚拟机编译的时候 认为 ready 是一个非 volatile 的 static 变量,
激进编译后的汇编代码就只从堆内存里面取了一次这个变量的值放到寄存器里面, 然后寄存器的值不会再被更新,所以就造成了死循环 具体参考这个 https://github.com/jonwinters/jmm-research 的第一节部分,有详细的汇编代码解释 |
|
25
lewis89 2021 年 4 月 4 日 |
|
26
lewis89 2021 年 4 月 4 日
|
 |
27
OliverDD 2021 年 4 月 4 日
这是内存一致性问题,解决办法好几个,原子变量、volatile 、甚至同步策略也可
|
 |
28
bugmakerxs 2021 年 4 月 4 日 via Android
直接看.class 命令看看,我记得能看到的
|
 |
29
BBCCBB 2021 年 4 月 4 日
看 jvm 内存模型和 volatile 做什么的就知道了.
每个线程都有自己的工作内存.. 不加 volatile, 变量被缓存在线程的工作内存中, 其他线程写入后也感知不到. |
 |
30
WngShhng 2021 年 4 月 4 日
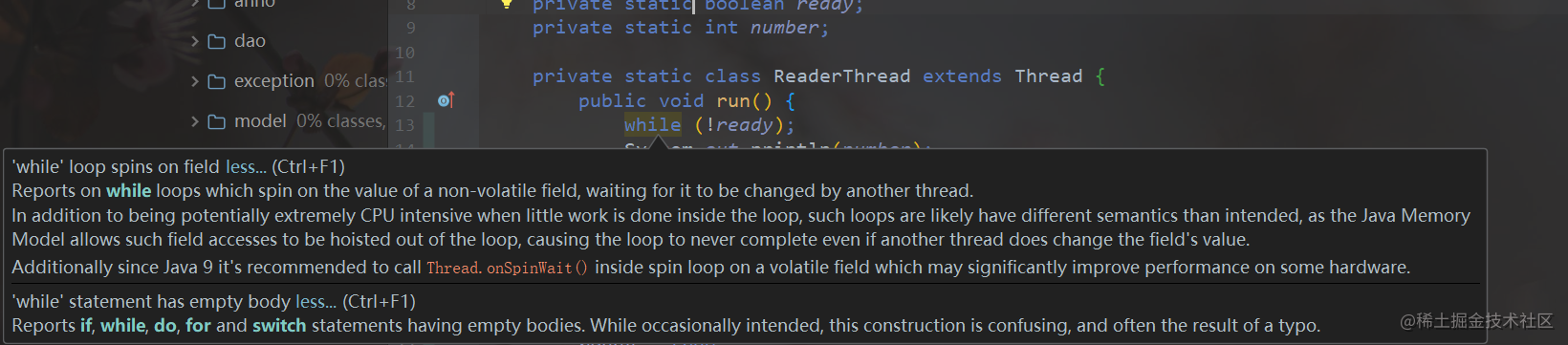
|
|
31
WngShhng 2021 年 4 月 4 日
@WngShhng
Reports on while loops which spin on the value of a non-volatile field, waiting for it to be changed by another thread. In addition to being potentially extremely CPU intensive when little work is done inside the loop, such loops are likely have different semantics than intended, as the Java Memory Model allows such field accesses to be hoisted out of the loop, causing the loop to never complete even if another thread does change the field's value. Additionally since Java 9 it's recommended to call Thread.onSpinWait() inside spin loop on a volatile field which may significantly improve performance on some hardware. |
 |
32
Martens 2021 年 4 月 4 日
ready 加上 volatile 修饰就行了, 保证 ready 变量的线程可见性......
|
 |
33
johnniang 2021 年 4 月 5 日 via Android
反编译一下就知道了。
|
 |
34
FrankHB 2021 年 4 月 5 日 怎么随便进一个楼都是各种不到点上的……
根本原因是 Java 语言不保证这里的调度公平性,所以明确允许把你 = true 饿死了不管。 这玩意儿跟可见性看起来表面上是有点关系,但不巧,Java 里这条恰恰是单独拎出来授权的: https://docs.oracle.com/javase/specs/jls/se16/html/jls-17.html#jls-17.4.9 Programs can hang if all threads are blocked or if the program can perform an unbounded number of actions without performing any external actions. 这样设计的理由,在 JSR-133 Chapter 13 里有提,是个妥协: https://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf (老实说这样设计挺欠扁的,虽然还有人居然认为这个“容易理解”: https://stefansf.de/post/non-termination-considered-harmful/ ←注意这人说的 C 和 C++ 在这里 undefined behavior 这个明确是错的。) @az467 你确定这问题真经? 和你说的恰恰相反,除了 JVM 自己高兴是不是愿意这样搞,这跟 JVM 没有半点关系。 关掉 JIT 也不保证一定顶用。 @ipwx C++ 和这个明显不一样。 C++ 是明确允许 forward prograss,反面允许把整个 while 直接优化没掉而不是 blocking: C++17 § 4.7.2 Forward progress ¶ 1 The implementation may assume that any thread will eventually do one of the following: - terminate, - make a call to a library I/O function, - perform an access through a volatile glvalue, or - perform a synchronization operation or an atomic operation. [Note: This is intended to allow compiler transformations such as removal of empty loops, even when termination cannot be proven. — end note] 虽然只是允许,所以实现上可能刚好一样…… 另外注意 C++ 这里是每线程内的约束。Java 的 volatile 自 JDK 1.4 后跟 C++11 的 std::atomic 语义类似,但这里 C++ 可是 volatile 就够了。 |
|
35
FrankHB 2021 年 4 月 5 日
(当然 C++ 的 volatile 就够了只是说看起来的死循环不被优化没掉,多线程还是该 atomic 就 atomic 该加锁就加锁,否则 data race 了死得更难看。)
|
|
36
ipwx 2021 年 4 月 5 日
@FrankHB 嘛嘛,我提一嘴 C++,主要是吐个嘈。我几乎不懂 Java 。
---- C++ 的 atomic 要保证的比 empty removal 要多了去了。譬如编译器或者 cpu 可以 out-of-order execution,可以在读取了某个变量以后假设它不变所以不读第二遍 etc 。。。。 后面那种情况用 volatile 还行,Out-of-order execution 用 volatile 就会死的很难看。。。这也是为啥我在写多线程程序从来不用 volatile (反正没卵用) |
|
37
ipwx 2021 年 4 月 5 日
... 用 atomic 的 memory fence 就能很好解决 out-of-execution 问题。
|
|
38
az467 2021 年 4 月 5 日
@FrankHB
啊? Chapter 13 的例子中程序有加锁,并且没有 external action,所以用 fairness 解释为什么程序可能会被优化成死循环。 原 po 的代码里甚至都没有出现过 synchronized/volatile,任何 happens before 关系都没有, 就算 Java 保证调度公平,难道 JIT 编译器就不优化了? |
|
39
FrankHB 2021 年 4 月 6 日
@az467 原问题是“说的不清楚……具体是什么原因呢?”光看这里,你回答一个具体实现的表现倒也算是对路。
但后面的疑问很明显是为什么允许这样做。拿实现行为就没解决问题。 关键是什么允许,直接的答案就是 JLS 里的规则。(事实上这段 JSR133 里也有。) 虽然跟你之后说的一样,最好看看整个 JMM,但直接原因是 JLS 就确定的,到这里跟 JVM 还不需要有关系。 (可能这里是该强调一下所谓编译器包括 JVM 的 JIT 而不只是 javac 。不过没看出一开始这里是不是有疑问。) 拿 JSR133 主要是说明背景。具体来说,用到的是 Chapter 13 里的第一段文字描述。 Figure 27 是一个典型的例子,有了 synchronize 都允许不让出 CPU,比这里的条件还强。(另外别忘了 happens before 在线程内就有效,不过这个和这里的问题没直接关系。) (后面那个 Figure 28 例子是反过来限制优化的,和这里也不直接相关。) 重新回顾重点:不是“优化”(而是为什么允许优化)。实际上考虑这里仍然不需要关心“编译器怎么优化”。说白了,编译器就算不是以优化的目的变换代码,直接编译成这样按规范也没话说。 没讲清楚这条线,讲实现细节只会更混乱。 用 volatile 等避免问题也是之后的延伸话题。 (道理上 happens before 也该弄明白,但尴尬的是这个只用线程内的就能直接踩上调度问题了,又不像 C/C++ 直接有 sequence before,还不如默认知道 program order 不言自明了……) |
