
这是一个创建于 1801 天前的主题,其中的信息可能已经有所发展或是发生改变。

大家好,我是吴敏。今天分享一个叫图数据库的技术产品。
什么是图和图数据库

先来介绍一下什么是图和图数据库,所谓的图和平常认知的图片其实不是同一个概念,图( Graph )在计算机科学里面是一种数据结构,这种数据结构有三个比较主要的概念:点、边和属性。
通俗的说,图结构还有其他的叫法,比如:网络结构、拓扑结构,大致上都是描述的同一种数据结构。
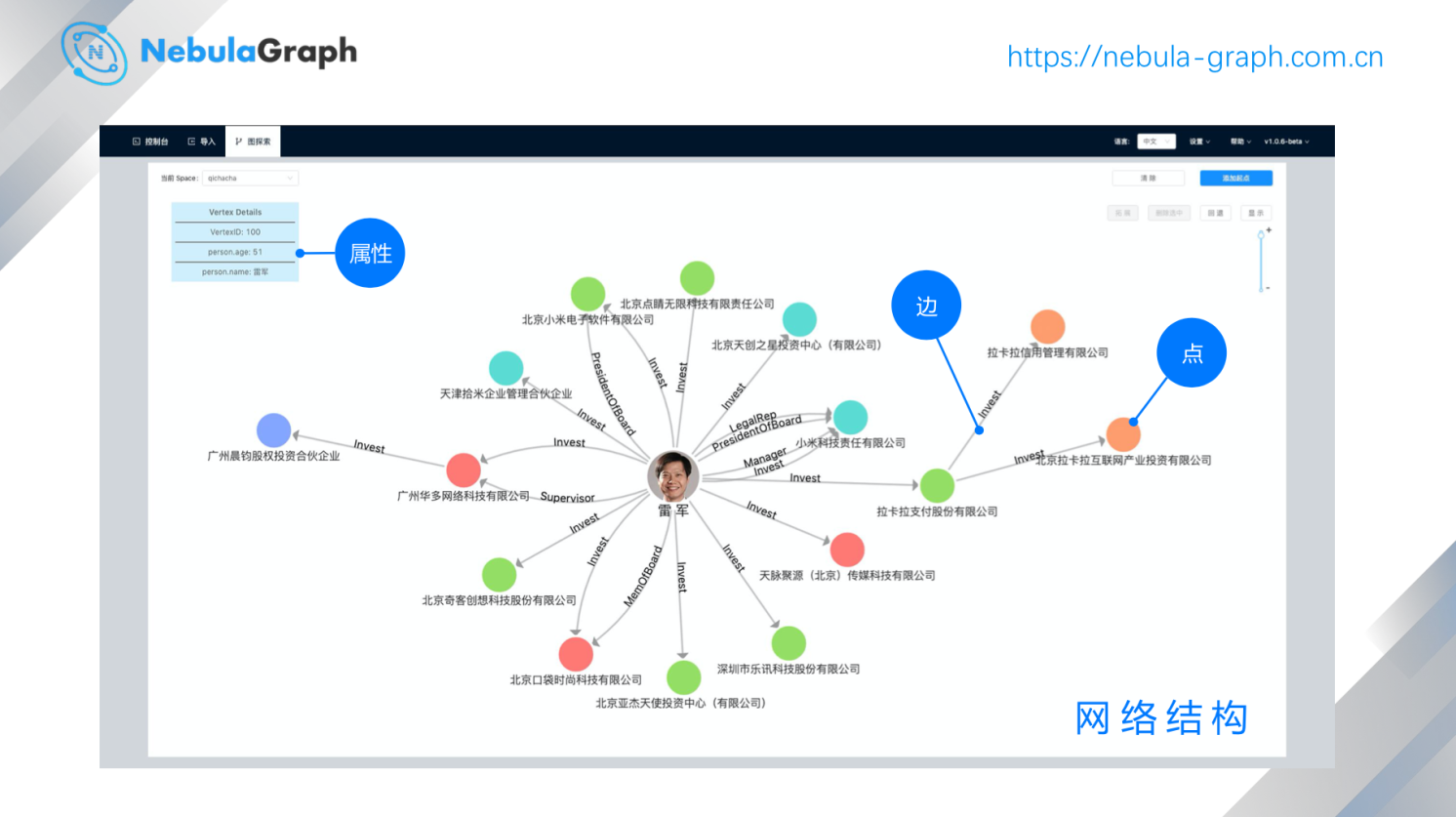
举个例子,上面这个图是典型的图结构(网络结构),人和公司,公司与公司都存在关联关系。这里面存在几个重要的概念,在网络结构中一家公司、一个人可以是一个点;还有另外一个概念是边,描述的是点与点之间的关系,对应上图中母公司和子公司之间的一个控股关系,也可以是某一个人是另外一个公司的董事长,这样的一个身份关系。点和边基本上组成一个网络结构。
图结构在工业界使用的时候还会加上一个概念就是属性。比如,中间的这个人(点)可以有他的身份证、性别、年龄属性,关系就是边上也可以有一些属性,比如说投资某家公司的投资金额、投资的比例、投资的时间等等,都可以构成这个投资关系的属性。
像基于上图这样的工商关系,微众银行、腾讯和我们( Nebula Graph )也都是有各自合作的项目。
图数据库的案例 1:反欺诈
下面来介绍下图的应用。
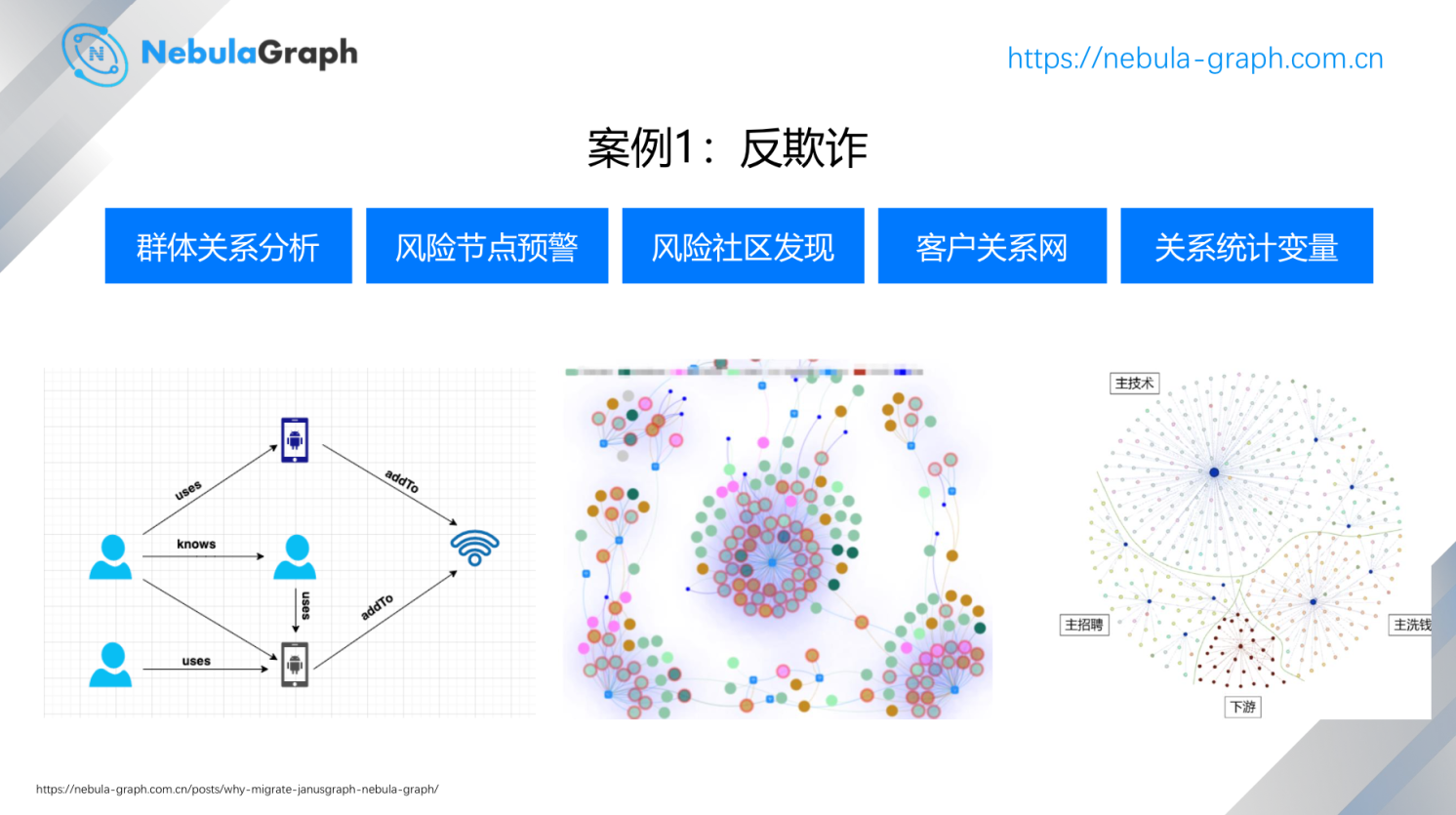
一般来说,图在安全场景里面的应用会比较多,上面这种图的中间部分是和 360 金融合作的一个项目,主要用于识别诈骗团伙。
具体来说,现在是互联网时代,很多 APP 支持申请贷款,不管是持牌或者持其他牌照的平台,都可以提供一定的贷款能力。与此同时,也存在团伙“作案”,当然抢银行的少,诈骗、骗贷的团伙多,而这些团伙是有特征的,可以通过一定的方式进行关联。
在左边的这个例子里,有些的黑产团伙,他们控制的账号会登录一些设备(手机),这些设备和 Wi-Fi 有关联关系。通过这样的 账号-设备-WiFi 关联关系可以识别出来这些团伙。这些团伙被识别出来后,如果团伙相关的人来贷款或者说是来申请授信时,在风控环节会先识别出来。
在中间这个例子里,红色的点是已知存在风险的账号,最中间的那个区域就是一个风险的团伙,这些节点就是被识别出来的风险节点,它们基于 Wi-Fi 关系将其他点关联到了一起。
360 金融通过用图的方法大概识别了接近 100 万个有风险的团伙,所以这些团伙哪怕换一个马甲或者其他设备也能第一时间把他们识别出来,进行屏蔽。右边案例图是一些受害人,蓝色的点是诈骗团伙,诈骗团伙还是有挺明显的特征存在的。
图数据库的案例 2:公司信用分

上面的例子主要是识别有风险的人,在这个例子里主要讲下 BOSS 直聘的公司风控。在上图中显示了 BOSS 直聘的一些公司,有些公司是很早入驻 BOSS 直聘平台,有些是新注册的。当中存在部分公司不一定可信,需要对这些公司作区分给一定信用分。比如说,公司信用等级好的对它的运营策略会放松点,信用等级差的公司对它的运营审核严格些。因为有不停的新的公司在注册,可以通过不同的运营方式得到这些公司的不同信息,上图这里用的是同这些公司有关联关系的关系公司。举个例子,我新注册一家公司的时候,这家公司还是会和其它公司有一些互动和关联,例如:该公司的分公司,或是公司同失信被执行人之间有关联关系,通过一轮轮的迭代算出风险评级和信用评级,为新出来的公司提供一个启动初始信用分,这个方法类似于网页权重中使用的 Page Rank 。每天晚上 BOSS 直聘会跑几百万社区的权重。
图数据库的案例 3:可信设备
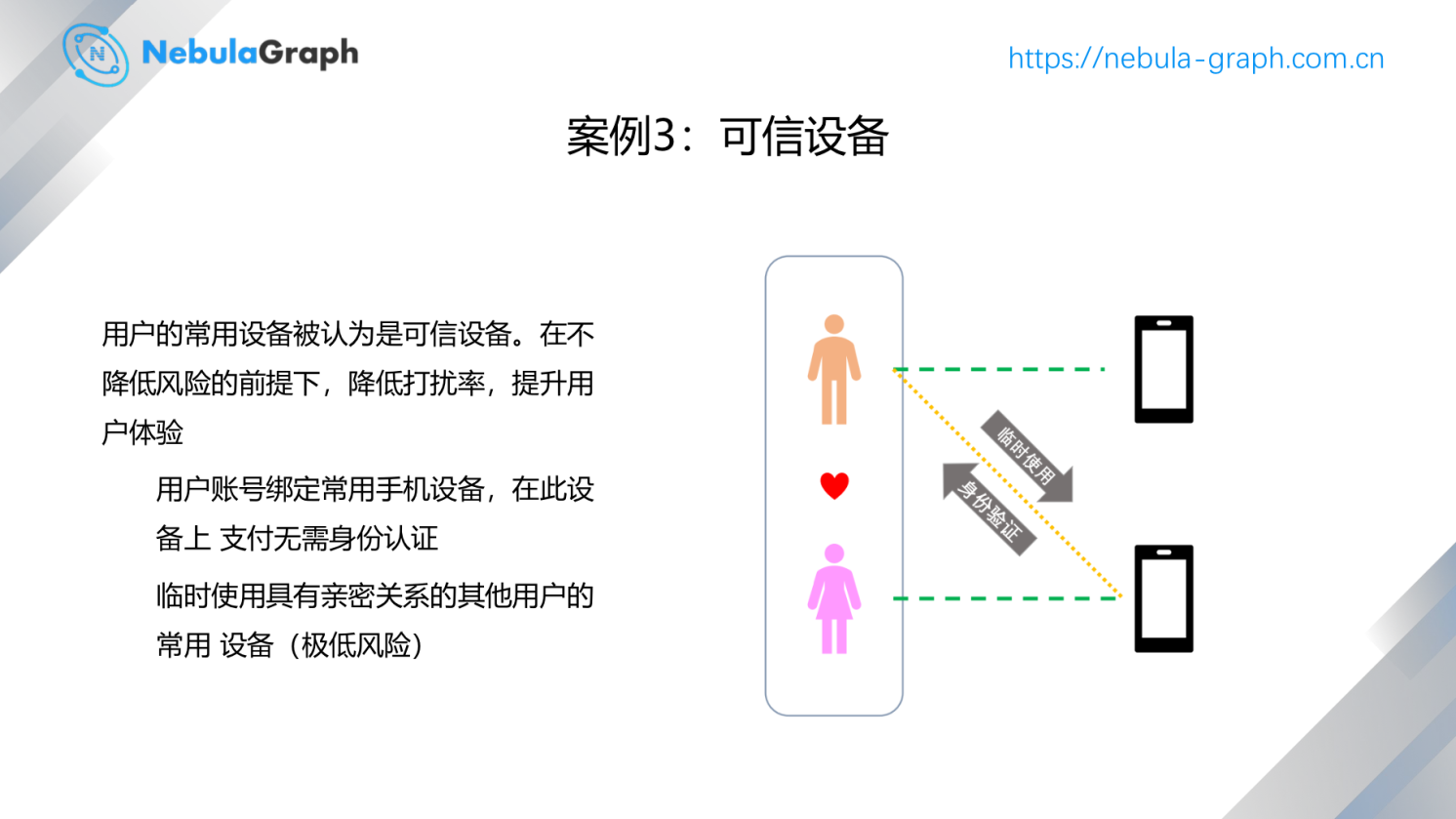
这个例子比较直观。现在每个人基本上都有手机,然后会有常用的手机设备,也可能你会临时换一个设备。这个常用设备下,鉴权的要求比较低。而用临时设备鉴权的要求较高,风控等级较高。还有一种情况就是家人临时使用彼此的设备,这种情况下的鉴权要求可以不需要那么高。因为只要换一个新设备就判断为高风险场景的话,其实对于用户的侵入和打扰很明显。
图数据库的案例 4:智能助理
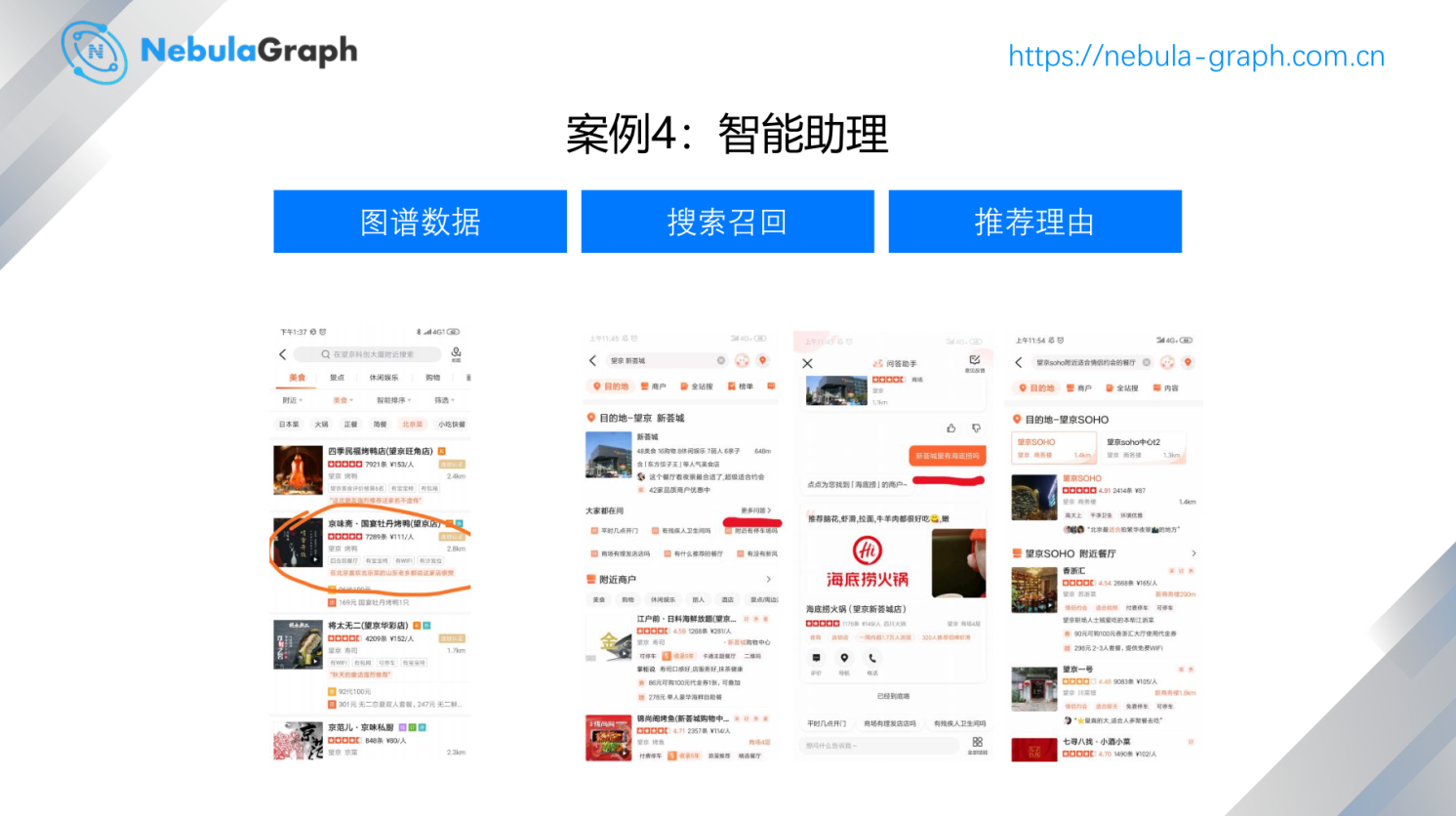
这个是和美团合作的项目,本身其实是有两方面,一方面是和知识图谱相关,一方面是和深度学习相关。目前来说大多数公司的推荐系统都有基于深度学习的模型。那么会存在一个问题:这个推荐出来的内容可解释性差。简单来说,用户不知道为什么产生这样的列表。因此,美团结合图谱做了一些应用,把所有的菜、地点、人、人与人之间的关系还有这些东西组成大的网,当深度学习模型算出推荐列表之后,取用户和商家之间所有可能的关系,取出一条路径或者多条路径的,在多条路径之间做一些加权或者说计算一些路径规则分,呈现给用户看上去更可理解的理由。比如,这里挺有意思的理由,叫“在北京喜欢北京菜的山东老乡都说这家店很赞”,看到这个理由的时候,你会觉得这个推荐略微合理。当然类似的方法也可以用于像问答机器人这样的 KBQA 的系统。
图数据库的案例 5:外部作弊与刷单
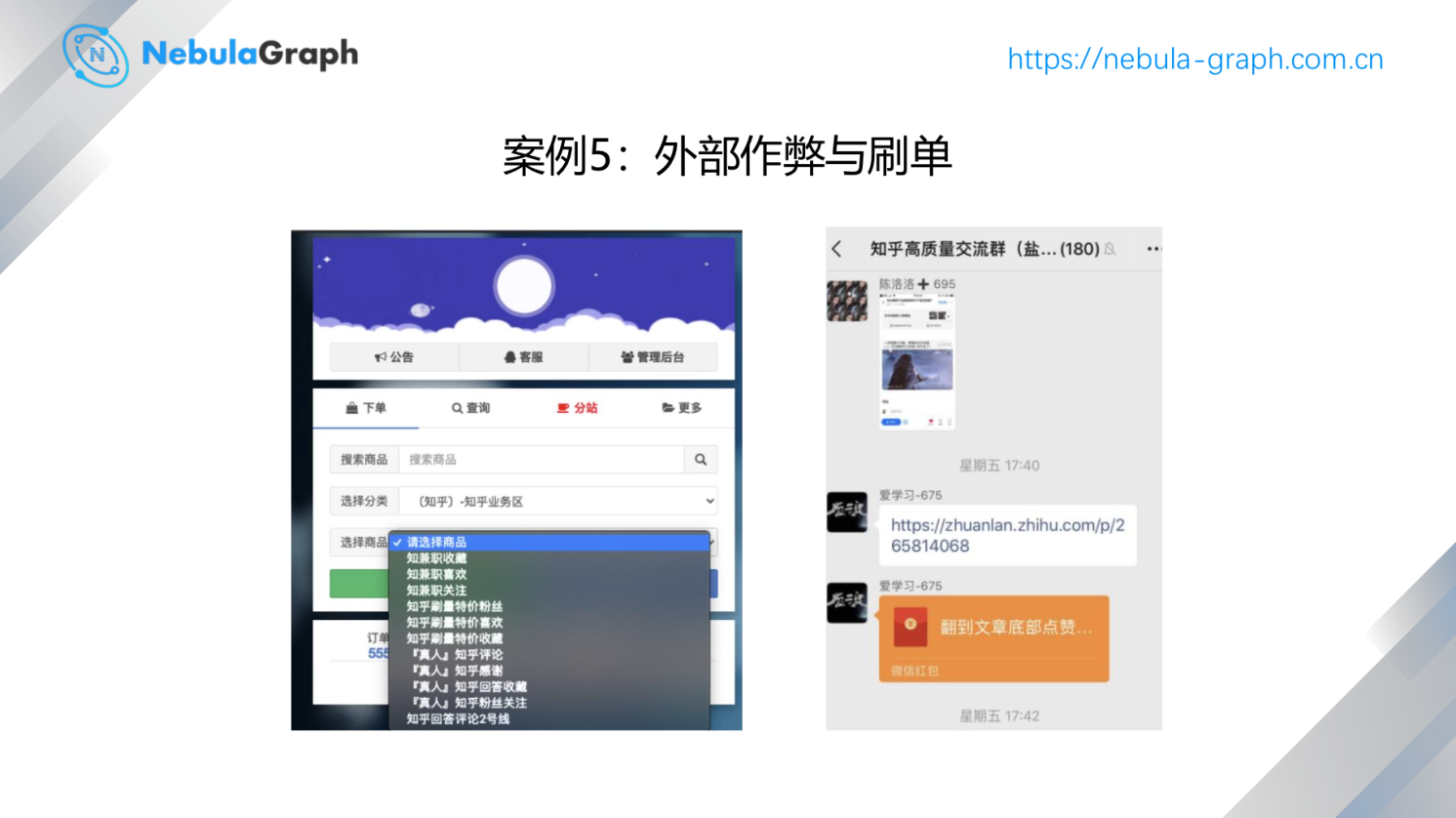
这是一个刷单的例子,其实很多公司会有运营经费,特别是对新用户会有运营经费,但是这会招来一些羊毛党。这些专业的羊毛党技术很好,他们来薅羊毛的速度比一般的消费者速度快很多,一般前期的大多数的运营经费不是给新用户用掉而是给羊毛党薅走了,羊毛党一般就是那些人,把他们识别出来之后,就可以降低运营经费被薅走的概率。
图数据库的案例 6:数据治理系统
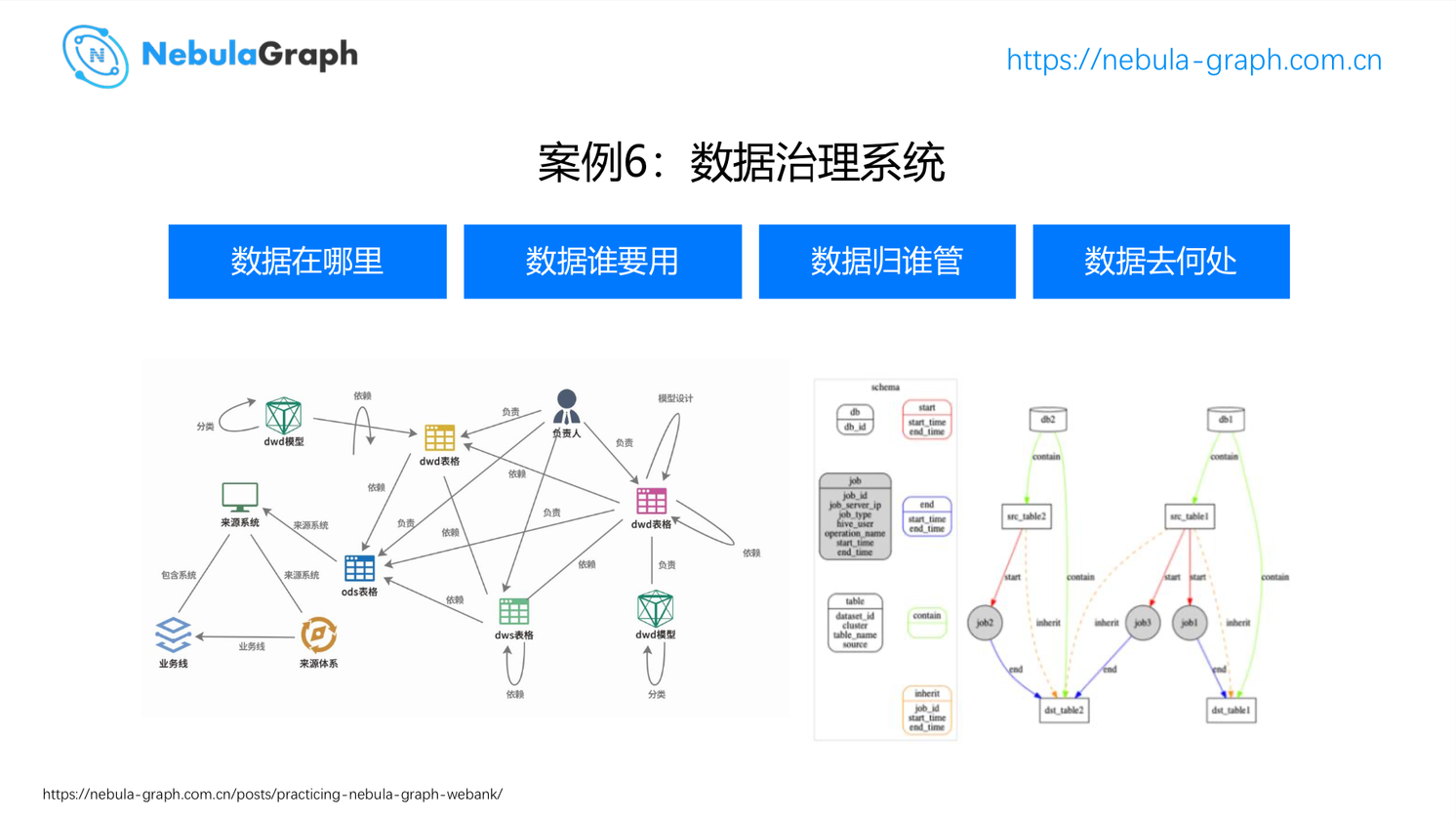
这个例子是关于 IT 系统的。我相信现在大多数的公司都是有一个庞大的数仓,几万张甚至几百万张的表,表与表之间又有比较强的依赖关系。例如:一张表或者某几张表取当中几个字段,通过一个 job 清洗,生成下一张表。某一天 DBA 或者某个业务人员发现有一个数据不太对,想知道哪个环节出错了,一层一层往上查,上百层的依赖,用图的方式关联就可以很快的查到哪个地方更有可能出错。这也是我们和微众银行合作的,他们现在正在使用的东西。
图数据库的案例 7 / 8:服务依赖分析 / 代码依赖分析

左边是和运维相关的,右边是和研发相关的事。因为现在基本都是微服务化了,整个微服务之间的调用关系其实是很庞大的。特别是一个大型集团内的 RPC 调用关系,运维自己都不一定搞得清楚全局是什么依赖情况。
这个是美团的例子,把所有的调用关系写到图谱里,大概是百万级别的调用关系。比如说运维想知道过去 7 天可用率低于 4 个 9 的链路有哪些,可以非常快速地识别出来,深度可以是 10 层也可以 100 层。
右边是一个辅助开发过程的小工具,对研发人员来说挺方便的。对于一个大型的代码仓库,函数之间相互调用。比如说研发今天想改用一个接口,但是我不知道有多少人在调用这个接口,是怎么调用的。对于测试来说,也不知道要测试哪些边界场景。那可以把这些关系都放到图谱里面去,这样大约是一个千万级别的调用关系,把整个调用关系全抽出来之后,那研发说我想看一眼这个接口被多少人调用了,调用方是怎么使用的; QA 要做测试的时候,可能有哪些边界场景受到影响也可以很快地知道。
为什么使用图数据库

刚才说的其实就是一些图的应用,当然其实这些应用不用图这种数据结构来处理,也是可以的。比如在数仓用 Spark 或者写 SQL 来做也可以。但是为什么更推荐用图数据库呢?有以下几个原因。
一图胜千言

一个是图的表达能力更强。左边是用表的结构方式来处理人物关系和社区关系。右边当中人的是比较重要的节点,他在左边的表中对应的某一行,右边是用图的方式来看。通过不同的着色可以很容易地看出来不同的社区,然后不同的社区之间通过某些特殊的节点来关联。这样远比用表的方式直观得多,特别是在右边图里面查找中心节点比起在左边的表中查找属性值大小要方便的多。
繁琐 vs 简洁

第二个是对于图的遍历这种操作来说——相当于表操作中 join 。如果用 SQL 来写,大约是左边这么长,也不是算非常复杂;但是用图的查询语言(右侧)来写的话,其实例子核心就是一句话,沿着一个点开始沿着这样一个路径取 Person 数据。所以对于图遍历操作,图专用的查询语言要更简洁。
更快!
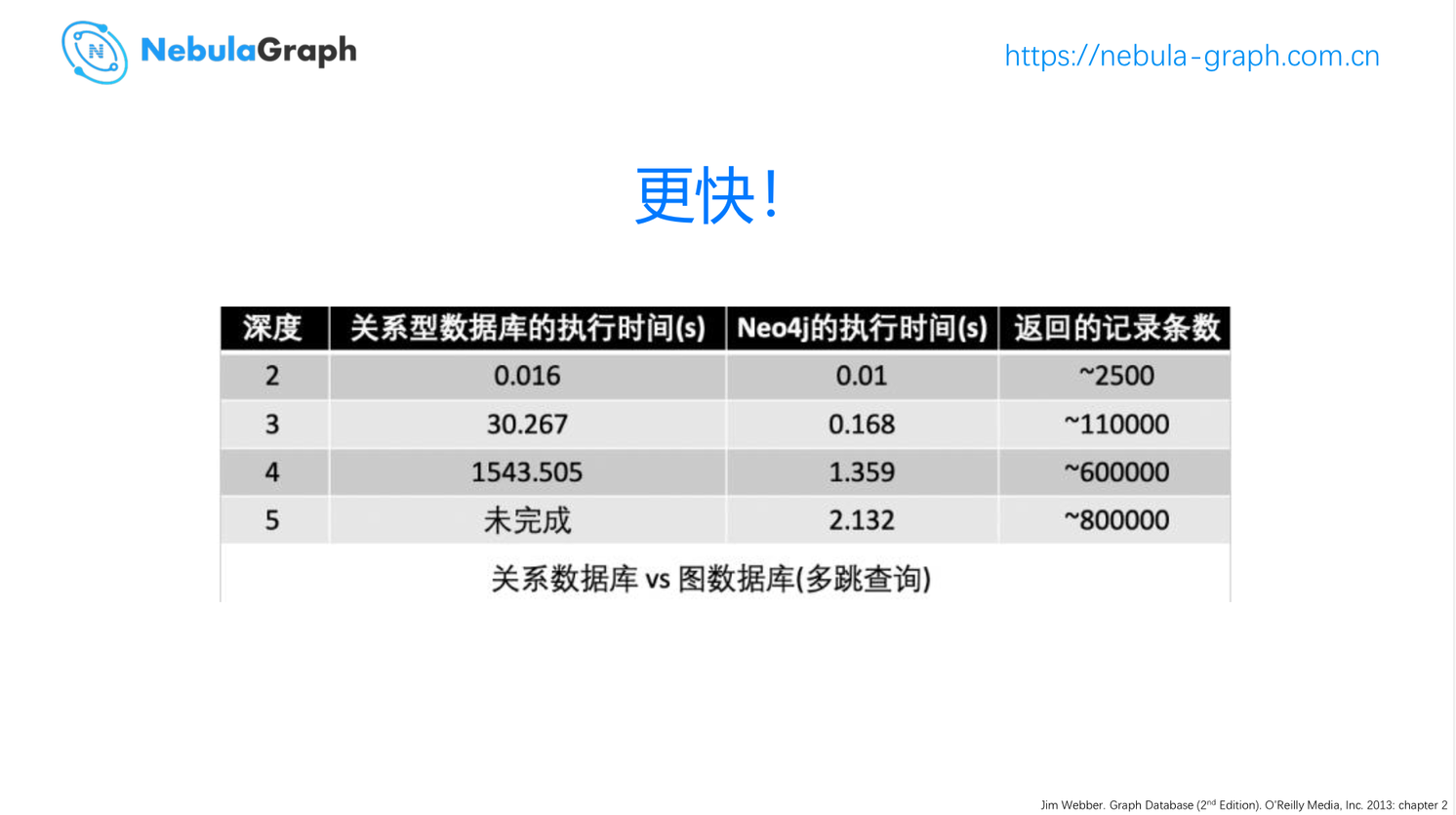
使用图还有一个优势是更快,行业内的经典例子就是查询的数据深度越多的时候,图数据库的优势越加明显。对于 4 、5 层深度的查询,小时级别的时延和秒级别的时延,是两种不同的业务形态。
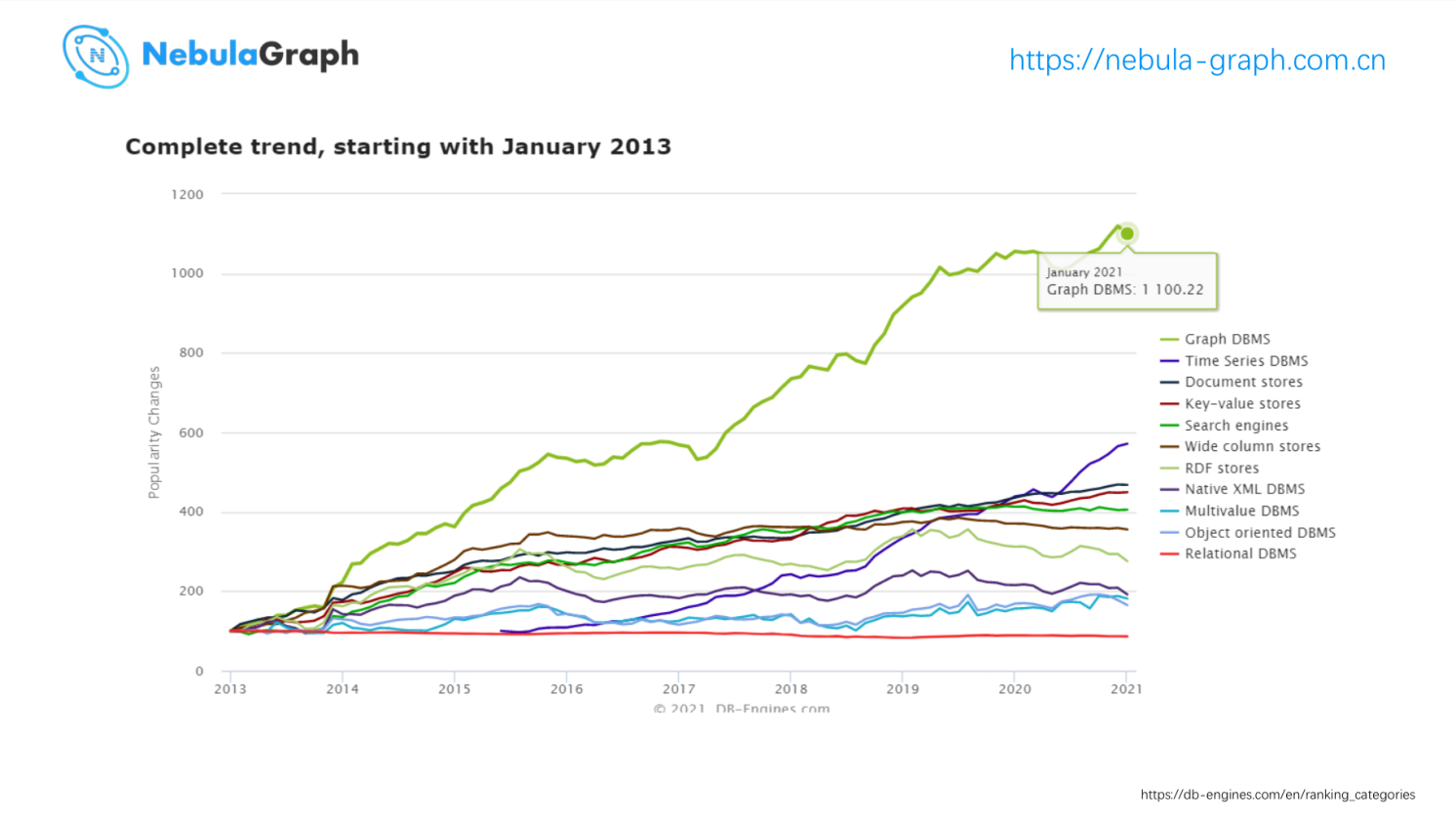
最后一个原因是关于流行趋势。在国际上,用于统计各种数据库类型流行情况的 DB-Engines 上,可以看到图数据库的趋势。上图这是这个月最新的数据,绿色是图这种数据库类型流行的趋势,最下面红色的线是关系型数据库的流行趋势。可以看到,图数据库在过去 8 年内保持了比较好的增速,增长了 11 倍。
为什么选择 Nebula Graph

当然,在整个图数据库领域,产品并不是只有 Nebula Graph 一个,也有很多的其他公司。今天早上也有其他同行在会场上,我想解释一下为什么会推荐 Nebula Graph 。

一般大家选型基于不同的需求看的重点不一样,我想可能会对可靠性、成本性能、功能各个方面进行权衡。
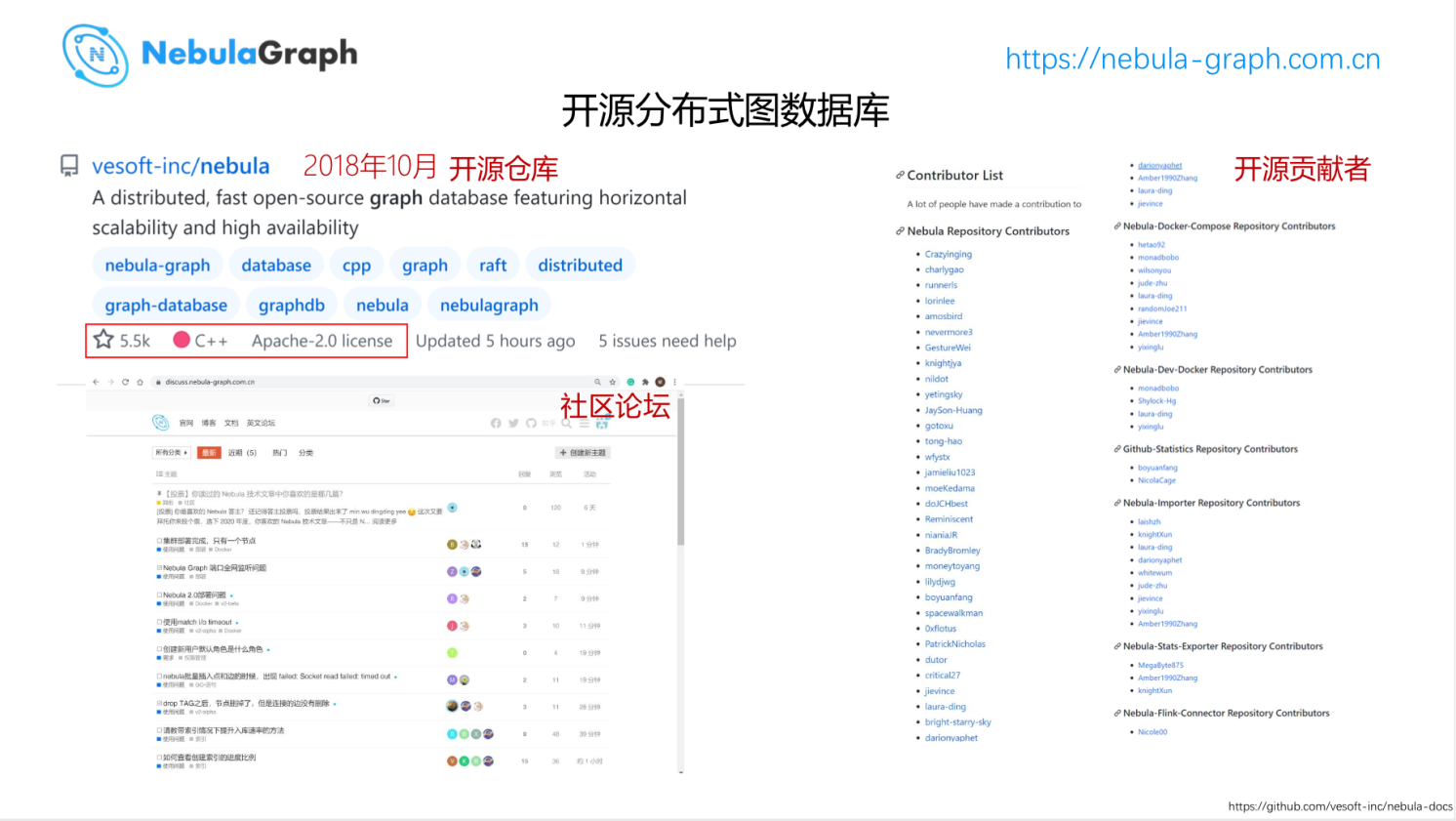
Nebula Graph 是一个开源的产品,源代码是开放在 GitHub 上的。虽然产品的研发时间不长,从 2018 年 10 月开始第一行代码,但是整个项目很活跃。
上图左下角是 Nebula Graph 中文论坛的情况,在国内有大量的使用者。而 Nebula Graph 本身是开源的项目,整个项目除了我们公司人员之外也有很多国内外贡献者,很多人在使用 Nebula 之后会发现一些 bug 这样就会 file 个 issue,也有不少人会自己动手 fix 和贡献 feature,这样提升了整个研发迭代速度。
右边是所有 Nebula 的 GitHub 贡献者列表,这些是公开情况,你可以在 GitHub 上面看到。总的来说,贡献者来源很多,并不是背后只有一家公司在研发。

上图是在生产环境使用 Nebula Graph 的公司。
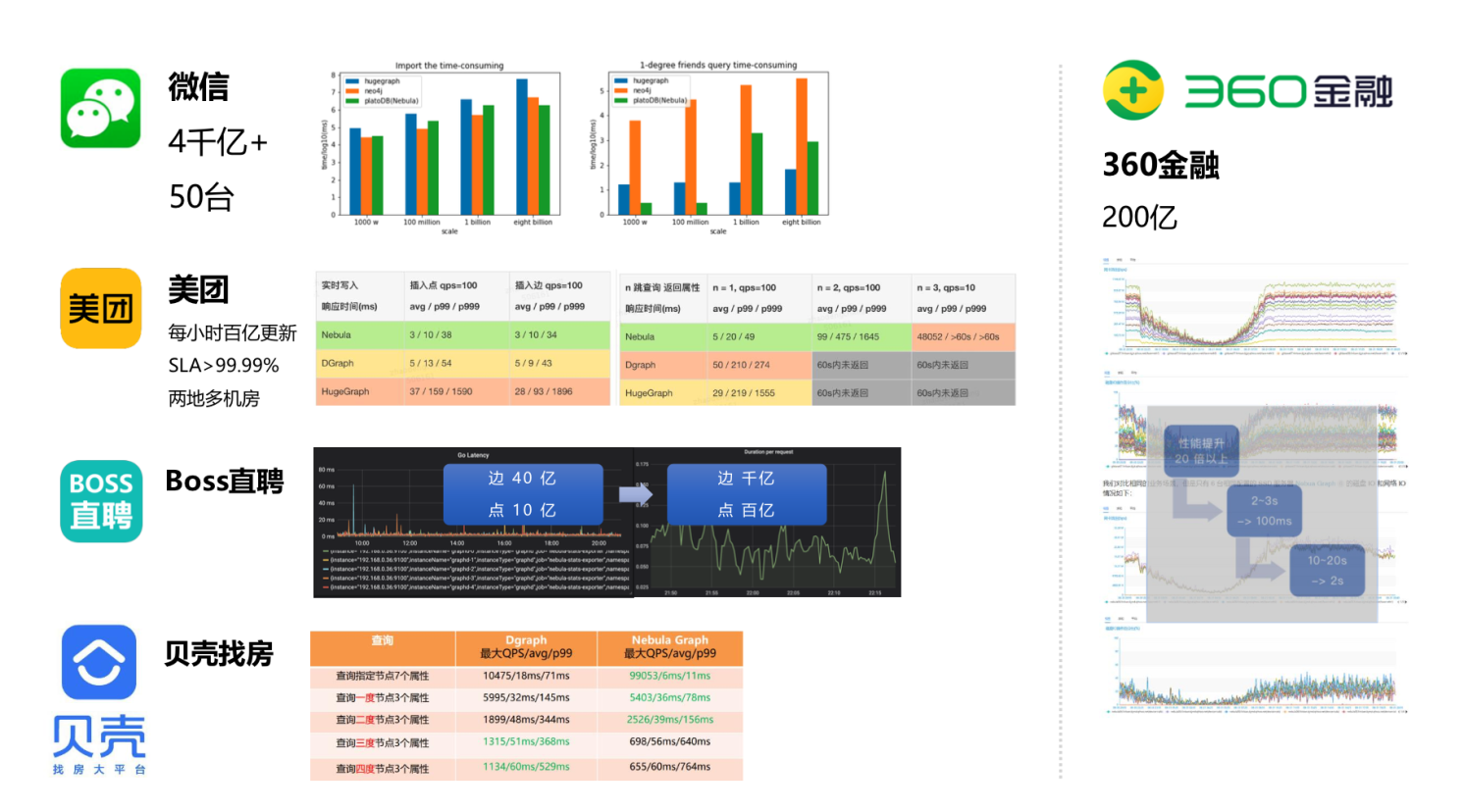
既然是 Nebula Graph 是开源代码的,那么所有人可以下载和评测。所有的用户都可以根据自己的业务场景做的评测,会更贴近自己的实际场景。而不像某些供应商自己提供的评测,用户难验证这样的评测里面隐藏了多少坑。
这张图第一个例子是去年和微信合作的项目,他们现在的生产环境单个集群是 50 台机器的规模,它的更新数据量大概是 4,000 亿这样的级别。第二个是美团的例子,美团所做的 Nebula 和其它竞争对手产品的评测。因为美团也是有一个非常高的可用需求,基本上都是要两地多机房。第三个是 BOSS 直聘的评测,从友商产品迁移到 Nebula 之后,从最初只能做 50 亿量级的边的产品,提升到做千亿点边的项目。下面这是贝壳做的评测,公开在今年的 DTCC,也是和友商产品的的对比。右边是 360 金融做的评测,生产环境服务器数量减少到原先集群的 1/3,性能是原来的 20 倍以上。
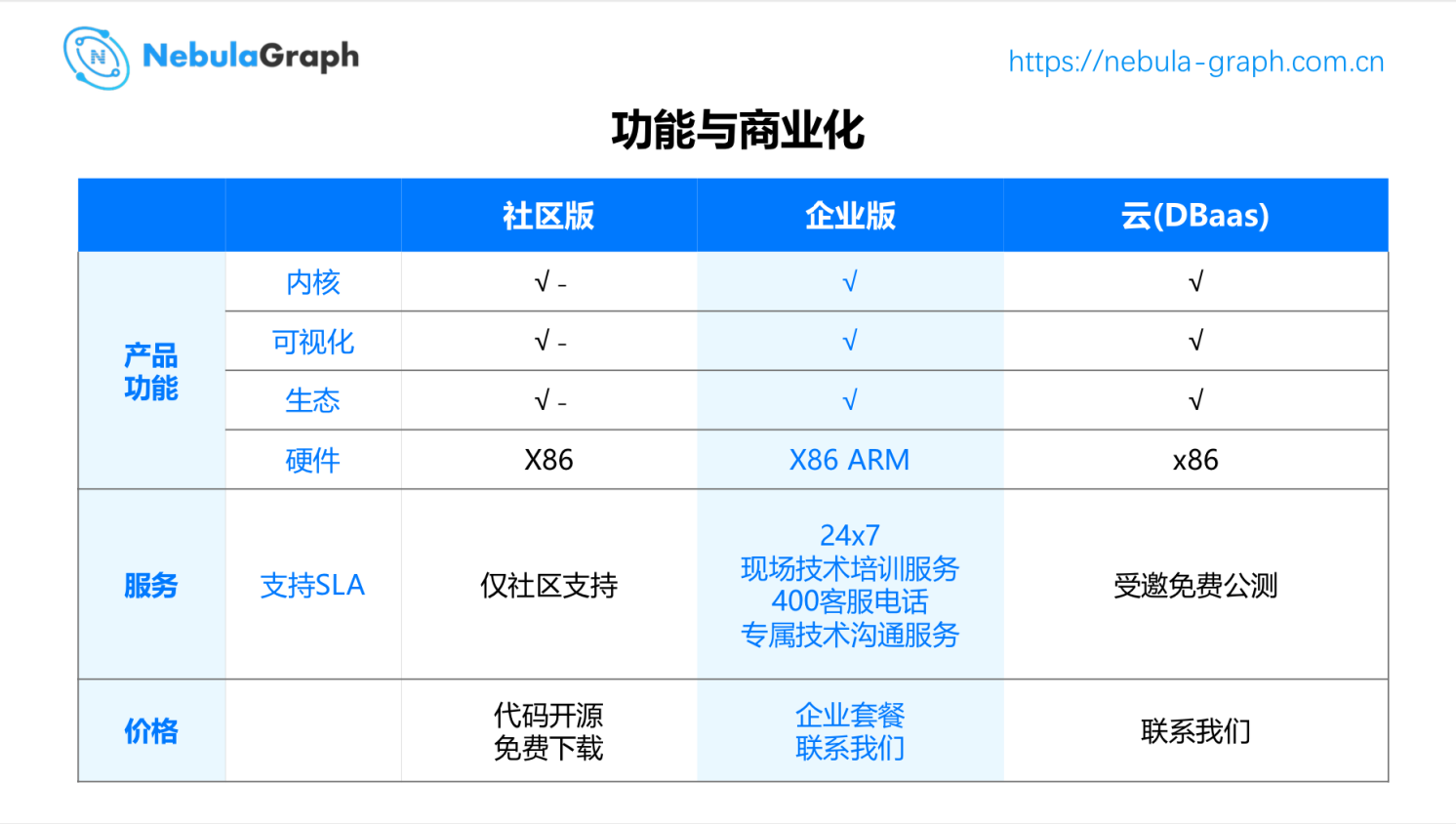
虽然软件本身是开源的,但是开源软件是可以商业化的。这个在国内外也是一个比较普遍的事情。Nebula 的源代码是开放的,所以不管是社区版也好,企业版也好,在产品功能内核、可视化、生态方面基本上没有太大的差别。主要的差别是在服务上,社区版如果有问题可以通过开源社区的方式来解决,按照开源协议( Apache 2.0 )的约定。而如果是企业版的话,那会提供企业版的严格的 SLA 。另外,云这几年流行和增速也非常的快,云目前是在受邀公测的阶段。大家有什么兴趣可以联系我们。
谢谢大家!
目前尚无回复