› MySQL 5.5 Community Server
› MySQL 5.6 Community Server
› Percona Configuration Wizard
› XtraBackup 搭建主从复制
Great Sites on MySQL
› Percona
› MySQL Performance Blog
› Severalnines
推荐管理工具
› Sequel Pro
› phpMyAdmin
推荐书目
› MySQL Cookbook MySQL 相关项目
› MariaDB
› Drizzle
参考文档
› http://mysql-python.sourceforge.net/MySQLdb.html
MySQL 相关项目
› MariaDB
› Drizzle
参考文档
› http://mysql-python.sourceforge.net/MySQLdb.html

这是一个创建于 1971 天前的主题,其中的信息可能已经有所发展或是发生改变。
背景
之前一直以为 MySQL 的多表关联查询语句是首先对 FROM 语句的前两张表执行笛卡尔积,产生一张虚拟表,然后使用 ON 过滤和 OUTER JOIN 添加外部行,再使用过滤后的虚拟表跟第三张表进行笛卡尔乘积,重复执行上述步骤。下面是从网上搜到一些比较热门的 SQL 执行顺序的文章,大家应该很熟悉吧,尤其是下面那张鱼骨图。
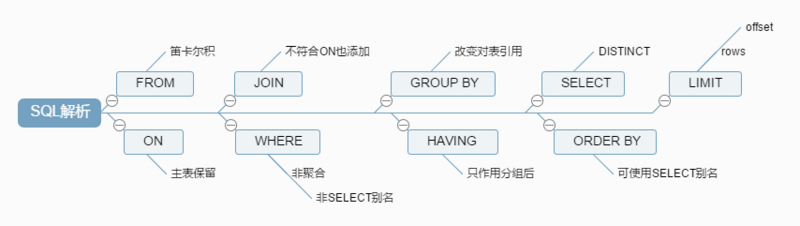 摘自:步步深入:MySQL 架构总览->查询执行流程->SQL 解析顺序
摘自:步步深入:MySQL 架构总览->查询执行流程->SQL 解析顺序
 摘自:
摘自:问题描述
最近由于工作需要,对 SQL 查询性能要求比较高,阅读了《高性能 MySQL (第 3 版)》查询优化的相关章节,在“6.4.3 查询优化处理”章节有这样一句话:
MySQL 对任何关联都执行嵌套循环关联操作,即 MySQL 先在一个表中循环读取单条数据,然后再嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。MySQL 会尝试在最后一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行以后,MySQL 返回到上一层次关联表,看是否能够找到更多的匹配记录,依次类推迭代执行。
于是对之前的认识产生怀疑,如果所有关联都是嵌套循环关联查询的话,只有当没有任何过滤条件时两张表才会产生笛卡尔乘积,而且这个笛卡尔乘积是一个结果,并不是关联查询的步骤,而且如果两张几十万、上百万的表进行笛卡尔乘积,这数据量有点巨大了。。。在 MySQL 的官方手册 中也印证了嵌套循环操作: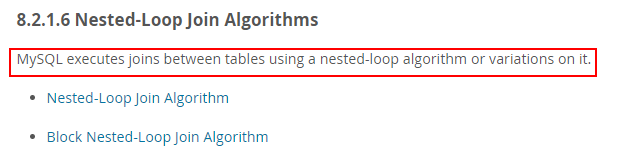
在博客园找到 神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(一) 这篇博客对上述笛卡尔乘积也有同样的疑问,而且给出了实际的案例分析,个人比较认同该博主的观点。里面有这样一个案例:
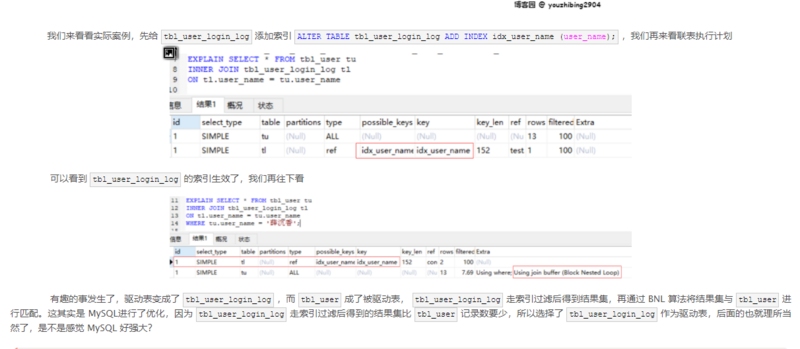
从这个案例可以看出当查询优化器使用 Index Nested-Loop 即索引嵌套循环,WHERE 条件首先通过索引过滤驱动表的数据然后再关联被驱动表,更加印证了 WHERE 不是在两表生成笛卡尔乘积后才进行过滤的。如果从“嵌套循环关联”的角度看,之前的关联表先生成笛卡尔乘积再进行过滤的理论是站不住脚的。
那么问题就是这种“笛卡尔乘积过滤”的理论有什么历史原因吗,为什么网上的文章大部分都是这种,还是我对“嵌套循环查询”有误解? 我相信有不少小伙伴跟我一样的疑惑吧,还望 V 站大佬给指点迷津。
 |
1
fuyufjh 2020 年 8 月 25 日 1. 你图裂了
2. “笛卡尔积再过滤”是帮助你理解 Join 语义的,实际上基本不会这么执行(除非 Join 不包含等值条件) 3. 对于有索引的情况,nested-loop (嵌套循环)是很高效的做法,每次循环实际上是对内表的一次 index lookup |
2
F281M6Dh8DXpD1g2 2020 年 8 月 25 日 via iPhone
自己写两个 sql 看看执行计划不就完了
|
 |
3
rainbirda OP @fuyufjh 嗯,之前也有这样想过。但是使用“笛卡尔积再过滤”就无法很好的解释 EXPLIAIN 里的内容。在 EXPLAIN 里可以清楚的看到查询计划每个表使用什么索引、表扫描的顺序、预估的行数等,如果使用“嵌套循环关联”的思想,可以很好的理解 EXPLAIN 了,而之前“笛卡尔乘积”这种会让人陷入误区,我之前也是百思不得其解。我感觉这种语义可能会把事情太简单化,其实对实际的查询优化没有帮助,而且会误导。
|
 |
4
dingyaguang117 2020 年 8 月 26 日
笛卡尔积 肯定是不可能这么实现的。内存能接受得了吗
|
|
5
rainbirda OP @dingyaguang117 是的 所以不知道网上那些文章是不是有什么统一的出处,或者是历史原因?我看这些都没有用笛卡尔乘积解释 EXPLAIN 的查询计划是怎么运行的,而且面试时也经常会被问到这种问题,答案跟这些文章也是一样的
|
 |
6
daozhihun 2020 年 8 月 26 日
个人认为网上说的“笛卡尔积过滤”只是数学上的等价,方便你理解,实际上引擎会根据各种情况找优化。就比如不同的算法去算正弦值,可能从理解的角度差不多,但实际上还是有很大区别的。
而且引擎有时候也不是很智能,某些情况还是要自己优化。之前我们就遇到过类似情况,先过滤掉大范围不匹配的,剩下的再去 join 效果会很好(当然看情况) |
|
7
dingyaguang117 2020 年 8 月 26 日
@rainbirda 另外我还对 in 查询的 运行流程比较感兴趣,LZ 了解吗
|
|
8
rainbirda OP @dingyaguang117 引用《高性能 MySQL (第 3 版)》 6.4.3 查询优化处理章节的列表 “IN()的比较”
> 在很多数据库系统中,IN()完全等同于多个 0R 条件的子句,因为这两者是完全等价的。在 MySQL 中这点是不成立的, MySQL 将 IN()列表中的数据先进行排序 ,然后通过二分查找的方式来确定列表中的值是否满足条件,这是一个 O(logn)复杂 度的操作,等价地转换成 OR 查询的复杂度为 O(n),对于 IN()列表中有大量取值的时候, MySQL 的处理速度将会更快。 但是这个二分查找是怎么加快处理速度的,还理解不了,也没找到相关资料,你看看这个能理解不 |
|
9
rainbirda OP @daozhihun 嗯 我明白你的意思,不过应该是在没有连接条件的情况下在语义上是与笛卡尔乘积是等价的吧,其他的情况下查询优化器实际运行的情况会很复杂,没有完全按照某种固定的顺序执行
|
|
10
daozhihun 2020 年 8 月 26 日
@rainbirda 是的,就好比《编译原理》这本书讲了一些设计和原理上的东西,但是实际上一个编译器是非常巨大的工程,一本书是不可能覆盖全的。想要了解具体每一个细节是怎么做的,估计只有去分析源码了,网上的都是一些经验性、比较笼统的东西,优化器真正执行的时候远比这个复杂
|
|
11
rainbirda OP @daozhihun 嗯,深感认同,确实只有分析源码才能真正明白背后的原理。每个人精力也是比较有限,大部分时候只能管中窥豹,有可能窥的还不一定是豹。。。
|
 |
12
zhangysh1995 2020 年 8 月 28 日 @rainbirda 对于关系代数里面的 formal 定义,笛卡尔积和 JOIN 是不一样的。
假设有两张表 R1, R2, 分别行表示为 t1, t2, 那么: * 笛卡尔积的结果是取所有的 t1, t2, 返回 (t1,t2) 拼接的结果; * JOIN 是根据给定的谓词 predicate,判断 t1, t2 是否满足,满足的话返回拼接结果。 概念上,JOIN 的操作确实可以理解为先笛卡尔积再过滤,但是实际不会这么操作,因为性能原因。对于 JOIN 的优化首先是 逻辑计划,比如 MySQL `straight_join` 就是一个人工强制的逻辑方案。 另外 Nested-Loop Join 算法是所称的 物理计划,理解为在存的数据集上如何进行存取。 |