
这是一个创建于 2018 天前的主题,其中的信息可能已经有所发展或是发生改变。
如题,目前手里有 1000 个条目,每个条目代表一个用户,有 20 个特征向量表示该用户行为。
我可以使用皮尔逊系数计算每两两用户间的相关系数,则该矩阵大小为 1000*1000
之后如何进行聚类呢?聚类算法有很多,哪种在当前这种条件下取得的效果比较好呢?
(为了使分类准确表达用户群体,假定预计分为 5 类,同一用户可以在多个不同类中)
 |
1
VelvetExodus 2020 年 7 月 25 日 via Android
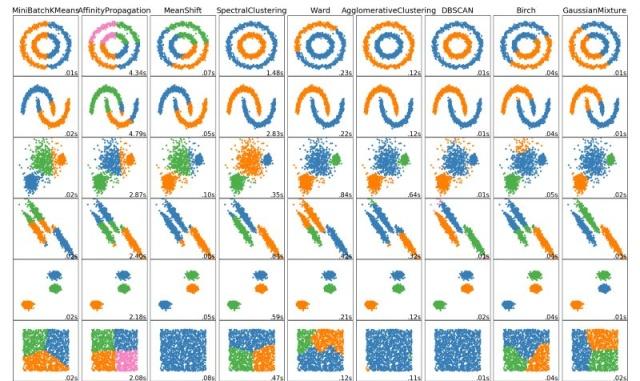
有试过特征降维吗?可以先降纬聚类看着直观些。dbscan 试试
|
 |
2
leimao 2020 年 7 月 25 日 via iPhone
你这个相关系数个人感觉没必要计算,直接用 clustering 算法就行了。是想你要是有一万个用户,你电脑就爆了。
|
 |
3
black11black OP @leimao
具体用那种算法呢,如果不算相关系数的话维度太高了,效果能好吗,我没什么经验 |
|
4
leimao 2020 年 7 月 27 日
@black11black 做好 feature engineering,然后准备好 validation dataset,然后每个 clustering 都试一下,看看哪个最好。KNN 比较常用。你之前做 1000 x 1000 correlation 的思路是做 recommendation 的思路。所以你得先搞清楚你是要干嘛。
|