
这是一个创建于 2083 天前的主题,其中的信息可能已经有所发展或是发生改变。
文末有惊喜
Git 的原理是怎么样呢?
Git is a distributed version-control system for tracking changes in source code during software development.
各位读者就算不了解 git 的原理,想必也会用三把斧git add; git commit; git push,下面就简单说一下 git 是怎么做的版本管理的:跟踪文件的变化,使用 commit 作为标记,与远程服务器同步。
跟踪文件变化
假如你来开发 git 这个工具,在初始化一个文件夹( repository )后,为了记录之后可能的修改,你需要记录当前所有需要跟踪的文件内容,最简单的就是全部复制一份好了。
文件是否变化了?比较一下文件哈希好了。
Commit 作标记
顾言思义,就是将当前的repository状态存储起来,作为 commit 。你可以通过commit恢复到任意状态,git tag本质也只是给这个commit一个tag(别名),git branch 也是一样。
恢复到某一个commit,就是将它所代表的repository状态恢复起来,就是将文件全部内容以及当前 commit 恢复到那个状态。
与远程服务器同步
git 说自己是分布式的版本管理系统,是因为假如 A 、B 、C 三个人一起合作,理论上每个人都有一份 server 的版本,而且可以独立开发,解决冲突。
Git 具体是怎么做的呢?
原理说完了,但 commit 的管理是要用东西来存储读取管理的,Git 没有用数据库,直接将其内容放到.git文件夹里。
里面有什么内容呢?
.
|-- HEAD //指向 branch 、tag (ref: refs/heads/devbranch)
|-- index
|-- objects
| |-- 05
| | `-- 76fac355dd17e39fd2671b010e36299f713b4d
| |-- 0c
| | `-- 819c497e4eca8e08422e61adec781cc91d125d
| |-- fe
| | `-- 897108953cc224f417551031beacc396b11fb0
| |-- fe
| | `-- 897108953cc224f417551031beacc396b11fb0
| |-- info
|
`-- refs
|-- heads //各个 branch 的 heads
| `-- master //此分支最新的 commit id
| `-- devBranch // checkout -b branch 就会生成的 branch
`-- tags
`-- v0.1
各位再结合
下面我展开讲讲:
HEAD: 指向 branch 或者 tag,标记当前是在哪个分支或者 tag 上;index:TODOobjects:记录文件的内容,每个文件夹名称是该 object 的 sha1 值的前两位,文件夹下的文件名称是 sha1 值的后 18 位;(tips:sha1 算法,是一种加密算法,会计算当前内容的哈希值,作为 object 的文件名,得到的哈希值是一个用十六进制数字组成的字符串(长度为 40 ))refsheads:heads里的就是各个分支的HEAD分别指向哪个commit id;简单说,就是 各个 branch 分别最新的 commit 是什么,这样子git checkout branch就可以切换到对的地方tags: 同理,这个文件夹里存的都是各个 tag
那么,新建一个 branch 的时候,只要在refs/heads文件夹里新建 branch 名字的文件,并将当前 commit id 存进去即可;
新建一个 commit 时,只要根据HEAD文件,找到当前的branch 或者 tag 是什么,修改里面的内容即可。
有点不好懂?咱给出一个 git 的实例,默认在一个文件夹执行git init后,添加一个文件并commit的信息, commit id 为017aa3d7851e8bbff78a697566b5f827b183483c:
$ cat .git/HEAD
ref: refs/heads/master
$ cat .git/refs/heads/master
017aa3d7851e8bbff78a697566b5f827b183483c
如上,HEAD指向了 master,而master的 commit id 正是刚刚 commit 的 id 。
存储读取解决了,那么 commit 怎么组织呢?
将当前的
repository状态存储起来,作为 commit 。你可以通过commit恢复到任意状态,git tag本质也只是给这个commit一个tag(别名),git branch也是一样。恢复到某一个
commit,就是将它所代表的repository状态恢复起来,就是将文件全部内容以及当前 commit 恢复到那个状态。
上面说了,管理文件夹( repository )状态,但是文件夹是可以嵌套的,与文件不一样,需要有这层级关系,同时也要存文件内容,怎么做来区分呢?
我们可以引入以下概念:
-
Tree:代表文件夹,因为
git init时,就是把当前文件夹./作为项目来管理,那么接下来所有要追踪的项目无非就是./里的文件或者文件夹而已; -
Blob:文件,Tree 里可以包含它;
关系如下图:
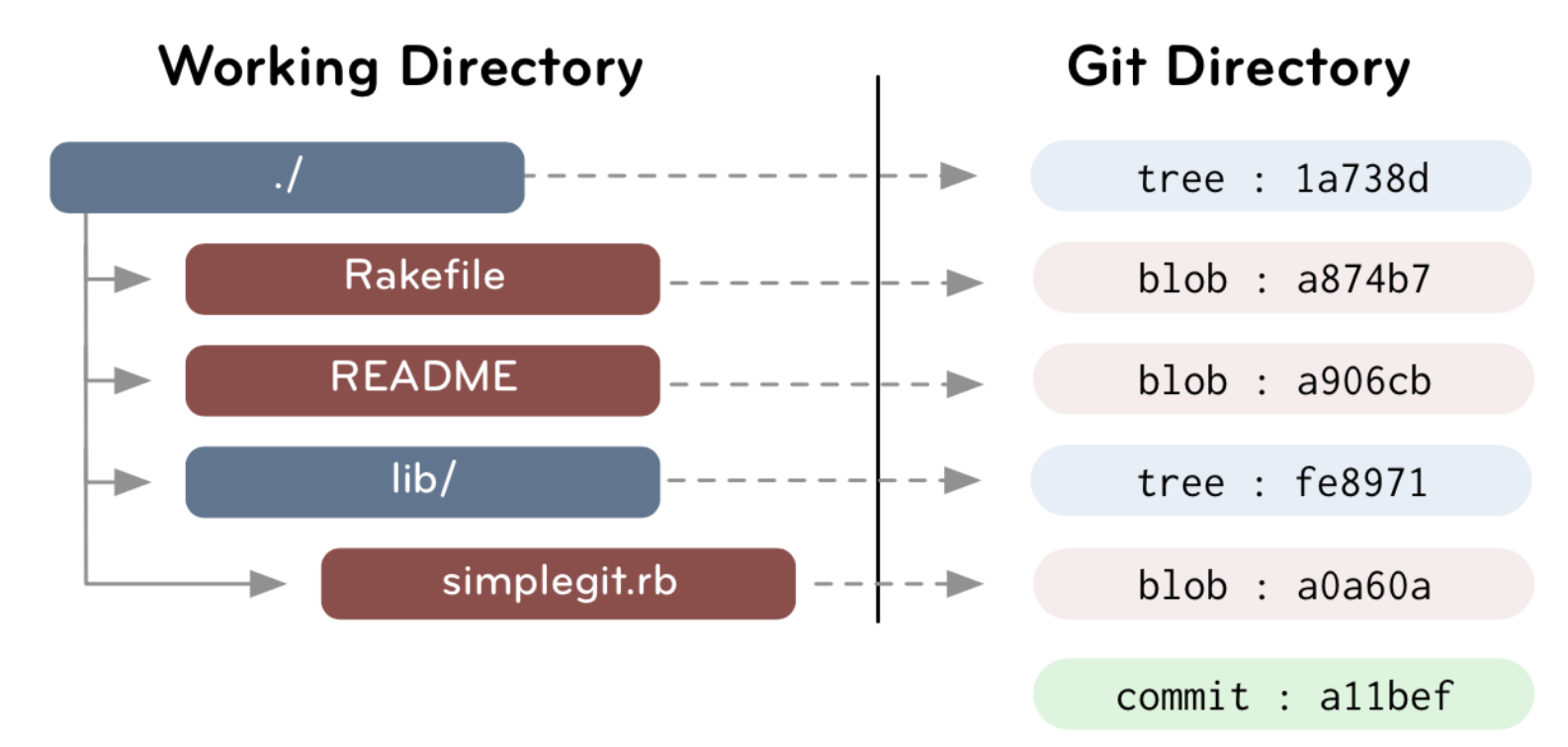
给点我们写的数据结构代码你看看,要注意的是,tree可以拥有blob或者tree,所以用了union;parent与next作为链表使用,作为文件夹目录管理;
struct tree_entry_list {
struct tree_entry_list *next;
union {
struct tree *tree;
struct blob *blob;
} item;
struct tree_entry_list *parent;
};
struct tree {
struct tree_entry_list *entries;
};
而commit跟树一样,也是有层级的单链表,不过只有
struct commit {
struct commit *parents;
struct tree *tree;
char *commit_id[10];
char *author;
char *committer;
char *changelog;
};
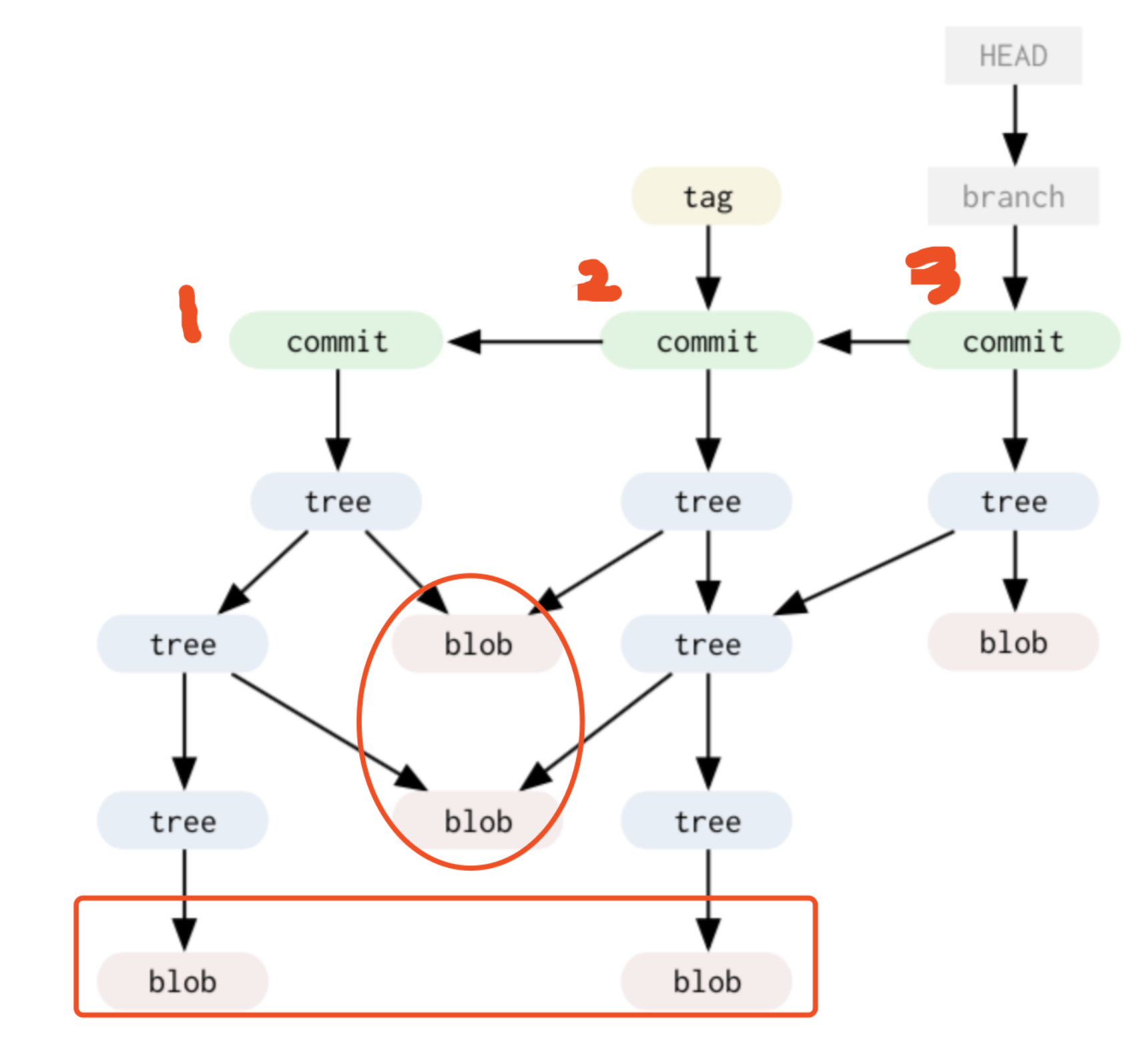
一图胜千言,看图吧:
云风的游戏资源仓库及升级发布
云风参考过 git 的原理做过一个游戏资源仓库管理,我下面讲一下它跟 git 的区别,他的文章我觉得比较绕,没有背景知识的人很难看明白。
背景
我们的引擎的一个重要特性就是,在 PC 上开发,在移动设备上运行调试。我们需要频繁的将资源同步到设备上
程序以 c/s 结构运行时,在移动设备上先建立一个空的镜像仓库,同步 PC 端的资源仓库。运行流程是这样的:
首先在客户端启动的时候,向服务器索取一个根索引的 hash,在本地镜像上设定根。
客户端请求一个文件路径时,从根开始寻找对应的目录索引文件,逐级查找。如果本地有所需的 hash 对象,就直接使用;否则向服务器请求,直到最后获得目标文件。api 的设计上,open 一个资源路径,要么返回最终的文件,要么返回一个 hash,表示当前还缺少这个 hash 对象;这样,可以通过网络模块请求这个对象;获得该对象后,无须理会这个对象是什么,简单写入镜像仓库,然后重新前面的过程,再次请求未完成的路径,最终就能打开所需的资源文件。
场景是:Client <- 他的游戏服务器 ,单向同步;
他是这样子做的,客户端的仓库是key-value的文件数据库,key 是文件的 hash,value 就是文件内容;
同步时,会从根到具体 hash 全量同步文件下载到数据库;
假如客户端使用资源时,发现缺乏这个文件,就用 hash 去服务器拉下来。
换言之,因为不需要管理本地版本,并且同步到上游,所以无需在本地记录全量的版本状态
跟 Git 的区别:
场景是:Client <-> gitHub,双向同步;
git 需要本地组织 commit,切换本地有但服务器没有的版本(就是离线操作) ,同时还需要将变更同步到上游。
最后的建议
如果看完该文,让你跃跃欲试的话,请不要用 C 写,请不要用 C 写,请不要用 C 写。
从零开始写过几个大一点项目,每次都觉得用 C 写项目太难受了,这次我写git commit时,发现要读写文件,解析内容,我发出了内心的感叹:
太难了,不是写这个难,是 C 太难用了。。
想到我要遍历这些文件,根据目录得到 tree 的 hash,然后还要 update 这棵树,把 tree 跟 commit 还要 blob 反序列存到文件里,还要读出来,之后还要组织链表操作,用 C 写就觉得百般阻挠。。。
看到最后的你
本文只是抛砖引玉; P
在下在 Shopee 工作,觉得水深火热不喜欢加班的同学可以考虑一下
拒绝 996,那就来 shopee,待遇 work life balance 两不: https://www.v2ex.com/t/672561#reply1
 |
1
ChristopherWu OP - = -,回复呢
|
 |
2
mlxy123123 2020 年 5 月 23 日
希望做软广的都对标楼主这个帖子
|
|
3
ChristopherWu OP @mlxy123123 哈哈哈哈,谢谢。有兴趣可以考虑找我,哈哈
|