
关于 PHP 的 iconv 和 mb_convert_encoding 函数都无法正确转换的求助
lanwairen123 · 2020-04-07 23:21:47 +08:00 · 1763 次点击这是一个创建于 2092 天前的主题,其中的信息可能已经有所发展或是发生改变。
任务:使用各种办法把下面的乱码正确转换为中文。
最近在看 DICOM 医学图像处理方面的内容,在一个 DICOM 文件中提取到一个编码后的字符串,是病人的姓名,显示为乱码,把这个乱码贴到 encodedecode http://string-functions.com/encodedecode.aspx 这里,Encode with 选择 iso-8859-1,Decode with 选择 GB18030,可以正确还原出病人姓名,但是我用 php 的 iconv 和 mb_convert_encoding 函数,填入相同的编码,却无法准确还原,仍然显示为乱码,网上找了各种资料,实在找不到原因,发在这里求助下大家吧。
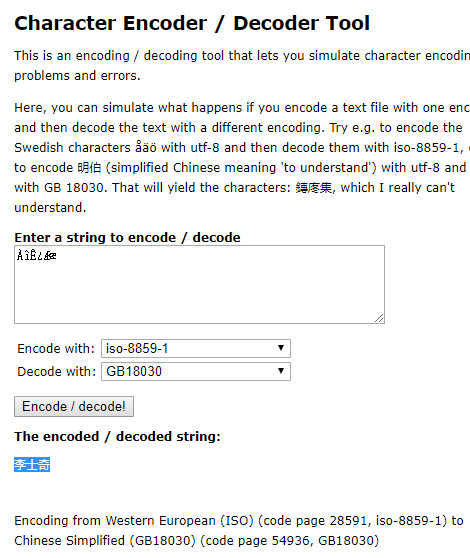
病人姓名的乱码是: ÀîÊ¿Ææ
json 自动编码的 unicode 为: \u00c0\u00ee\u00ca\u00bf\u00c6\u00e6
病人姓名和通过上面网址转换的姓名为:李士奇
想达到的目的是通过各种转换把乱码的姓名还原成中文的姓名。
DICOM 文件的 SpecificCharacterSet 标签值是 ISO_IR 100
很多国产的医学设备产生的带有中文信息的 DICOM 图像都存在这种问题,使用 DICOM 浏览器载入这些中文信息显示的都为乱码。处理这些问题头都大了。
这里有个链接可以参考下,不过他用的是 JAVA 实现的,我不会用 java,项目是基于 php 和 JavaScript 的
第 1 条附言 · 2020-04-08 07:47:06 +08:00
 |
1
msg7086 2020-04-08 06:01:17 +08:00 via Android
你的代码呢?
|
 |
2
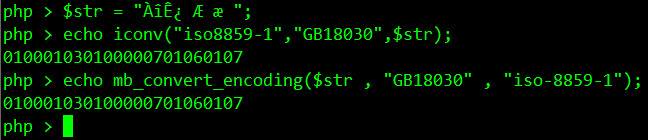
lanwairen123 OP @msg7086 不好意思,代码附上了
|
|
3
msg7086 2020-04-08 08:13:22 +08:00 $str = '\u00c0\u00ee\u00ca\u00bf\u00c6\u00e6';
$str = json_decode("\"$str\""); $str = iconv('utf-8', 'iso8859-1', $str); 到这里 str 就是 GBK 了。 要在 UTF-8 的终端里显示,可以再用 echo iconv('gbk', 'utf-8', $str); json_decode 默认出的是 UTF-8,所以要做一次 UTF-8 转回假 ISO8859-1 的操作,就能得到 GBK 了。 |
|
4
lanwairen123 OP @msg7086 it works !非常感谢您解决了我这几天的困扰!
|