推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

pandas 关于 groupby 的分组保存问题:如何将分组完以后的值按照某个列分别存为新 dataframe?
thinszx · thinszx · 2020-03-18 17:58:10 +08:00 · 6156 次点击这是一个创建于 2123 天前的主题,其中的信息可能已经有所发展或是发生改变。
有一个如下的 DataFrame
| A | B | C | |
|---|---|---|---|
| 0 | a | 1 | c |
| 1 | a | 3 | a |
| 2 | a | 2 | b |
| 3 | c | 3 | a |
| 4 | c | 2 | b |
| 5 | c | 1 | c |
| 6 | b | 2 | b |
| 7 | b | 3 | a |
| 8 | b | 1 | c |
我已经对这个 DataFrame 做了处理,将它按照A列分组以后又在各组内对B列进行了排序,如
df.groupby('A').apply(lambda x: x.sort_values('B')).reset_index(drop = True)
| A | B | C | |
|---|---|---|---|
| 0 | a | 1 | c |
| 1 | a | 2 | b |
| 2 | a | 3 | a |
| 3 | b | 1 | c |
| 4 | b | 2 | b |
| 5 | b | 3 | a |
| 6 | c | 1 | c |
| 7 | c | 2 | b |
| 8 | c | 3 | a |
但我现在想把每个分组按照A列导出,例如导出成这样的(在这里只列了 a 分组,但我也需要 b 和 c 的分组)
| A | B | C | |
|---|---|---|---|
| 0 | a | 1 | c |
| 1 | a | 2 | b |
| 2 | a | 3 | a |
我本来的考虑是写一个 for 循环,在开头记录一个 flag 值,对之后的列进行比较,每次遍历到新的分组就更新 flag,但这样感觉有些复杂了,想问问各位有没有什么好的方法呢?
 |
1
jyyx 2020-03-19 08:46:56 +08:00
list(df.groupby('a')) 是要这个吗?
|
 |
2
MisterLee 2020-03-19 10:42:41 +08:00
df_1 = df.groupby('A').apply(lambda x: x.sort_values('B')).reset_index(drop = True)
for item in df_1['A'].unique(): df_2 = df_1[df_1['A'] == item] df_2.to_xxx #导出 |
 |
3
wittyfans 2020-03-19 12:10:33 +08:00 是这样吗?
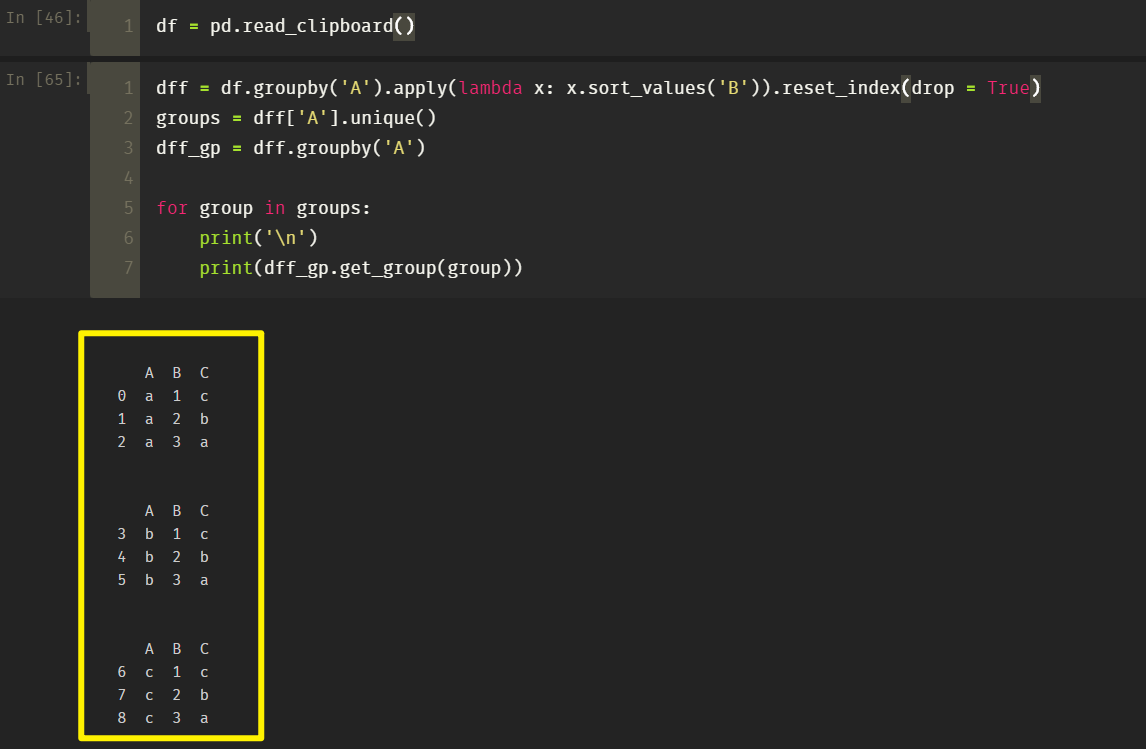 |
 |
4
thinszx OP @jyyx 谢谢你的回答,不过和我想得有一些出入,我想得到的是拆分后的 DataFrame,因为后续对各个分组的操作还要用到 pandas 的一些函数
目前我解决的方法是新开了一个列表,来存储排序后 DataFrame 中各个分组的大小(直接调用了 count()函数),然后用了一个 for 循环每次切片操作,得到小的 DataFrame 大致的做法像这样: itr = 0 # 起始指针 sorted_group_list = [] # 存放每个小分组对象 separate_group_counts = np.array(df['A'].count()).tolist() # 存储了各个分组的大小 for count in separate_group_counts: sorted_group_list.append(df[itr:itr + count].copy()) # 这里的 copy 不要可能会省点内存,不过有点危险 itr += count 楼下那位的做法好像也挺不错的,比我的简洁一点 |
|
6
wittyfans 2020-03-19 12:42:59 +08:00 @thinszx 不客气,我也是在别人那里学到的,再分享你一些我常用的 groupy 的例子:
# 显示所有组,后面是值的 index' df_gp = dff.groupby('name') df_gp.groups # 拿到某个 group 的值 df_gp.get_group('bryan chen') # 根据名字的第一部分来 group dff.groupby(dff.name.str.split(' ').str[0]).size() # 根据名字中是否有 wittyfans 来 group dff.groupby(dff.name.apply(lambda x: 'wittyfans' in x)).size() # 对 groupby 的值,平均分段统计后汇总数量 df_mean.groupby( pd.qcut( x=df_mean['AUSTRALIA - AUSTRALIAN DOLLAR/US$'], q=3,labels=['low','mid','hight'] ) ).size() # 对一列值分组 pd.qcut( x=df_mean['AUSTRALIA - AUSTRALIAN DOLLAR/US$'], q=3,labels=['low','mid','hight'] ) # 按照自定义的值来分组 df_mean.groupby( pd.cut( df_mean['CHINA - YUAN/US$'], [6.0,6.5,7.0,7.5,8.0,8.5] )).size() # 根据指定日期列来 resmaple,再做分组统计 dff.groupby( pd.Grouper( key='start', freq='d' ) ).size() # 根据指定日期列来 resmaple,再 apply 你的函数 df.reset_index().groupby( pd.Grouper( key='Time Serie', freq='5Y' ) )['CHINA - YUAN/US$'].apply(np.mean) # 根据指定日志来 resample,再结合多个聚合函数 df.reset_index().groupby( pd.Grouper( key='Time Serie', freq='5Y' ) ).agg( { 'HONG KONG - HONG KONG DOLLAR/US$':'mean', 'CHINA - YUAN/US$':['median','std','mean'] }) # 偶尔 groupy 重命名很麻烦,可以这样写:(pandas>=2.5) aggregation = { 'china': ('CHINA - YUAN/US$','mean'), 'hk': ('HONG KONG - HONG KONG DOLLAR/US$','mean') } df.groupby('region').agg(**aggregation) # groupby 返回的是 reduce 的数据,如果要根据某个分类分组,然后再计算单个值占该组的占比,可以这样写 df['%'] = df.groupby('location')['name'].transform(lambda x:x/sum(x)) # 使用 filter 配合 groupby 选择数据 df.groupby('location').filter( lambda x: (x['worklog'] * x['ticket_num']).sum() > 20000 ) df.groupby('location').filter( lambda x: (x['worklog'] * x['ticket_num']).mean() > .3 ) 上面提到的一些列名,有的来自 kaggle 上的汇率数据,有的是我自己平时处理的数据,不理解的自己实际操作下就懂了。 |
|
8
jyyx 2020-03-19 14:37:54 +08:00
|