
这是一个创建于 2167 天前的主题,其中的信息可能已经有所发展或是发生改变。
在写爬虫的过程中,我们经常使用 XPath 来从 HTML 中提取数据。例如给出下面这个 HTML:
<html>
<body>
<div class="other">不需要的数据</div>
<div class="one">
不需要的数据
<span>
<div class="1">你好</div>
<div class="2">世界</div>
</span>
</div>
<div class="one">
不需要的数据
<span>
<div class="3">你好</div>
<div class="4">产品经理</div>
</span>
不需要的数据
</div>
</body>
</html>
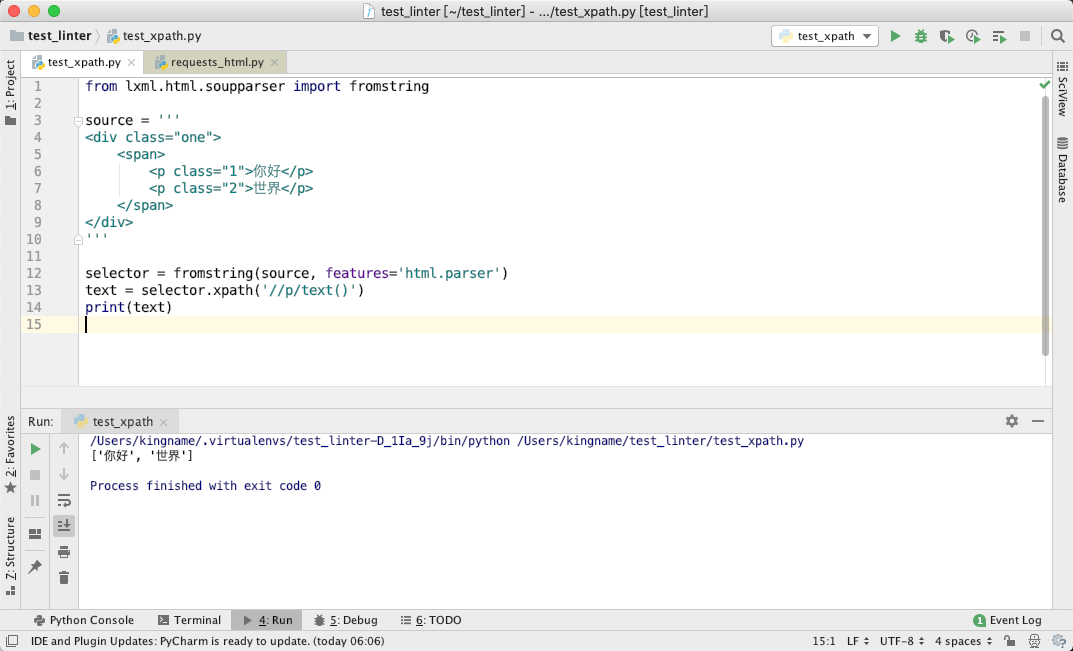
如果我们使用 lxml 来提取里面的你好、世界、你好、产品经理。
于是我们写出下图所示的代码:
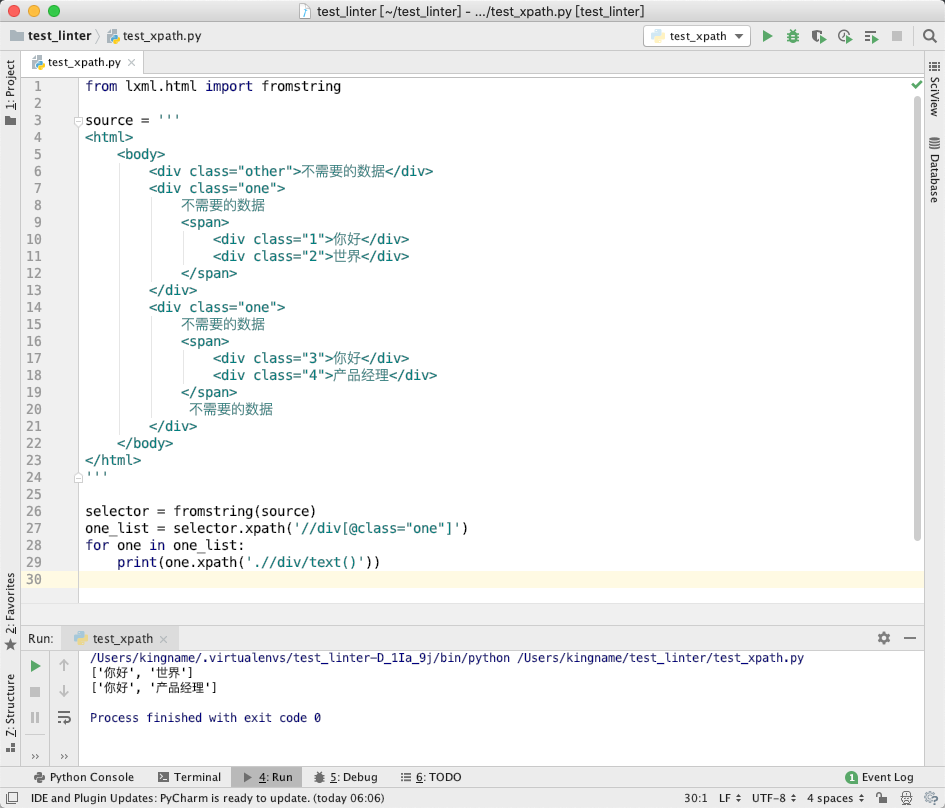
我们也可以使用 Scrapy 的 Selector 执行相同的 XPath,结果是一样的:
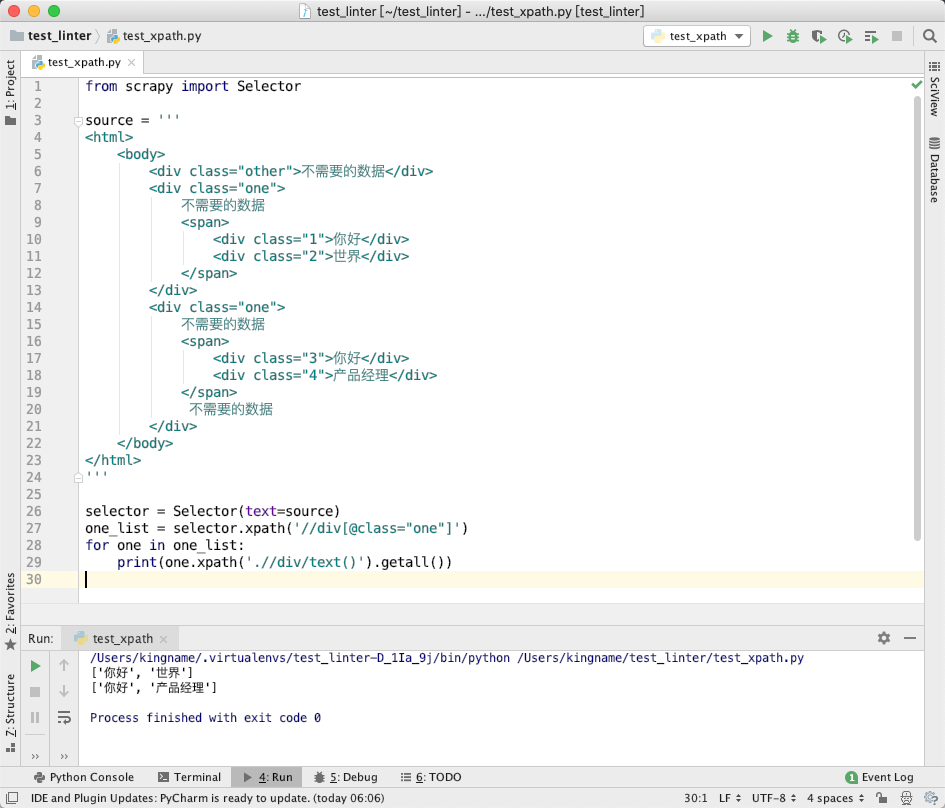
首先使用 XPath 获取class="one"这个 div 标签。由于这里有两个这样的标签,所以第 28 行的 for 循环会执行两次。在循环里面,使用.//获取子孙节点或更深层的div标签的正文。似乎逻辑没有什么问题。
但是,requests的作者开发了另一个库requests_html,它集成了网页获取和数据提取的多个功能,号称Pythonic HTML Parsing for Humans。
但如果你使用这个库的话,你会发现提取的结果与上面的不一致:
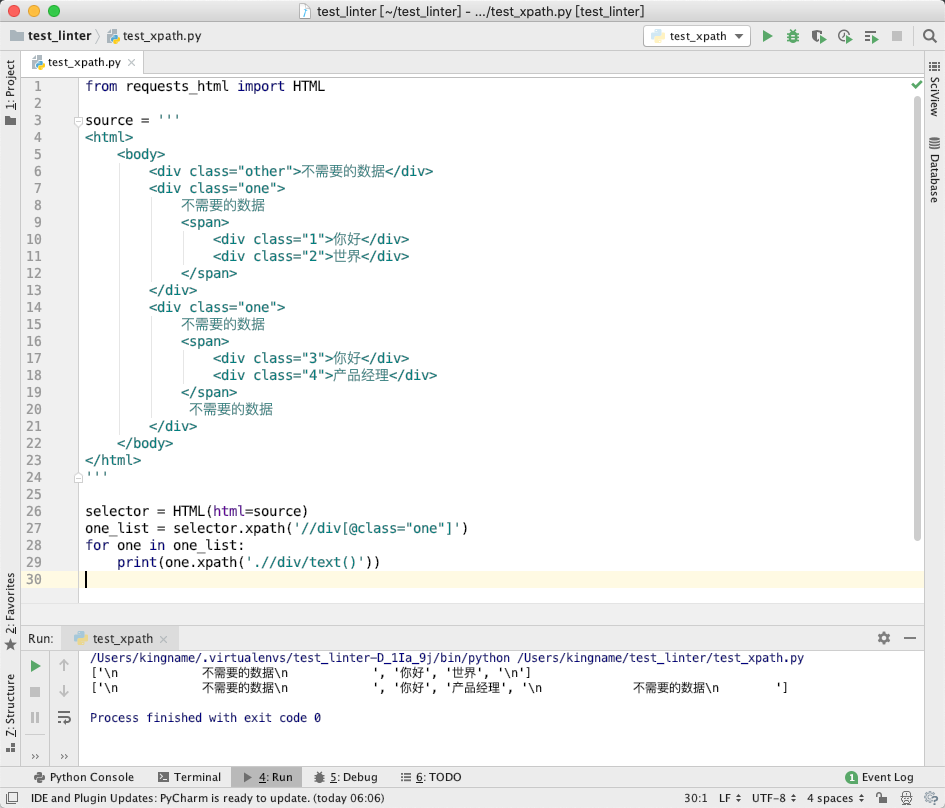
完全一样的 XPath,但是返回的结果里面多出了一些脏数据。
为什么会出现这样的情况呢?我们需要从一个功能说起。
我们修改一下 HTML 代码,移除其中的脏数据,并对一些标签改名:
<html>
<body>
<div class="other">不需要的数据</div>
<div class="one">
<span>
<p class="1">你好</p>
<p class="2">世界</p>
</span>
</div>
<div class="one">
<span>
<p class="3">你好</p>
<p class="4">产品经理</p>
</span
</div>
</body>
</html>
现在,如果我们使用原生的 lxml 来提取数据,我们的代码写为:
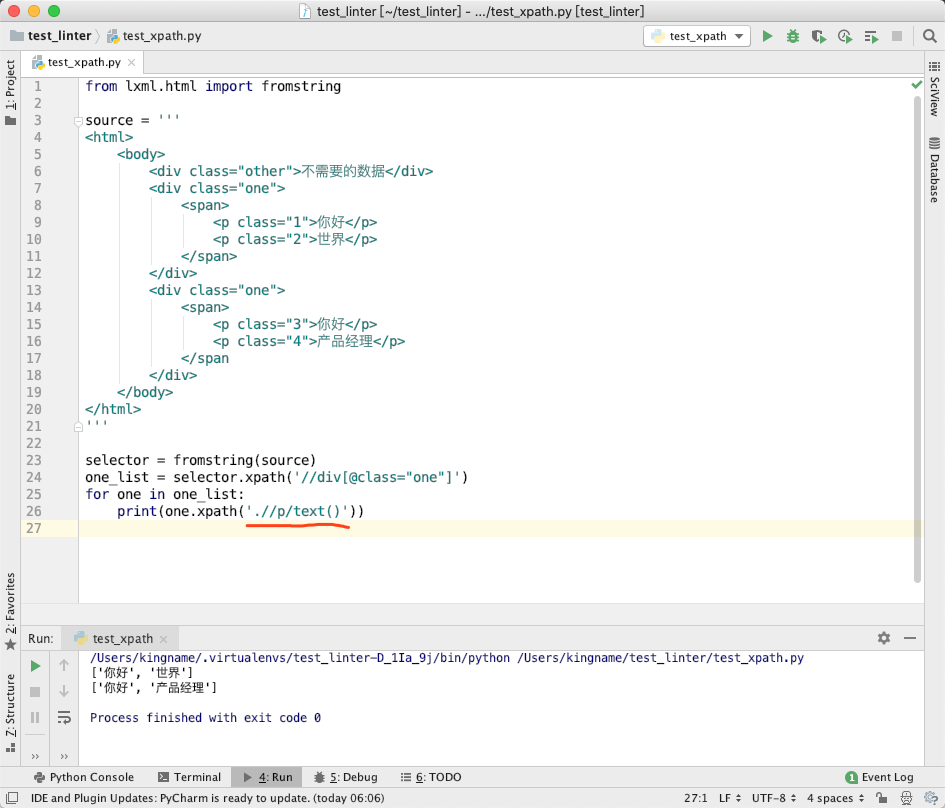
注意画红线的位置,.//p/text()——当你在某个 XPath 返回的 HtmlElement 对象下面继续执行 XPath 时,如果新的 XPath 不是直接子节点的标签开头,而是更深的后代节点的标签开头,就需要使用.//来表示。这里的p标签不是class="one"这个 div 标签的直接子标签,而是孙标签,所以需要使用.//开头。
如果不遵从这个规则,直接写成//,那么运行效果如下图所示:
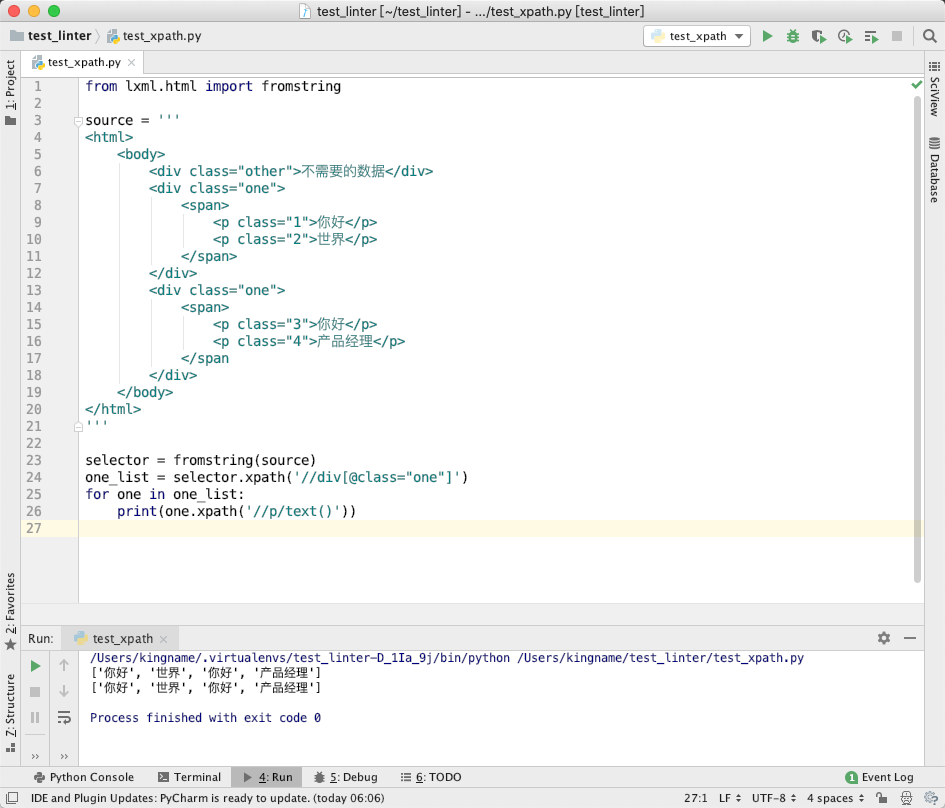
虽然你在class="one"这个 div 标签返回的 HtmlElement 中执行//开头的 XPath,但是新的 XPath 依然会从整个 HTML 中寻找结果。这看起来不符合自觉,但它的逻辑就是这样的。
而如果使用requests_html,就不用遵守这个规则:
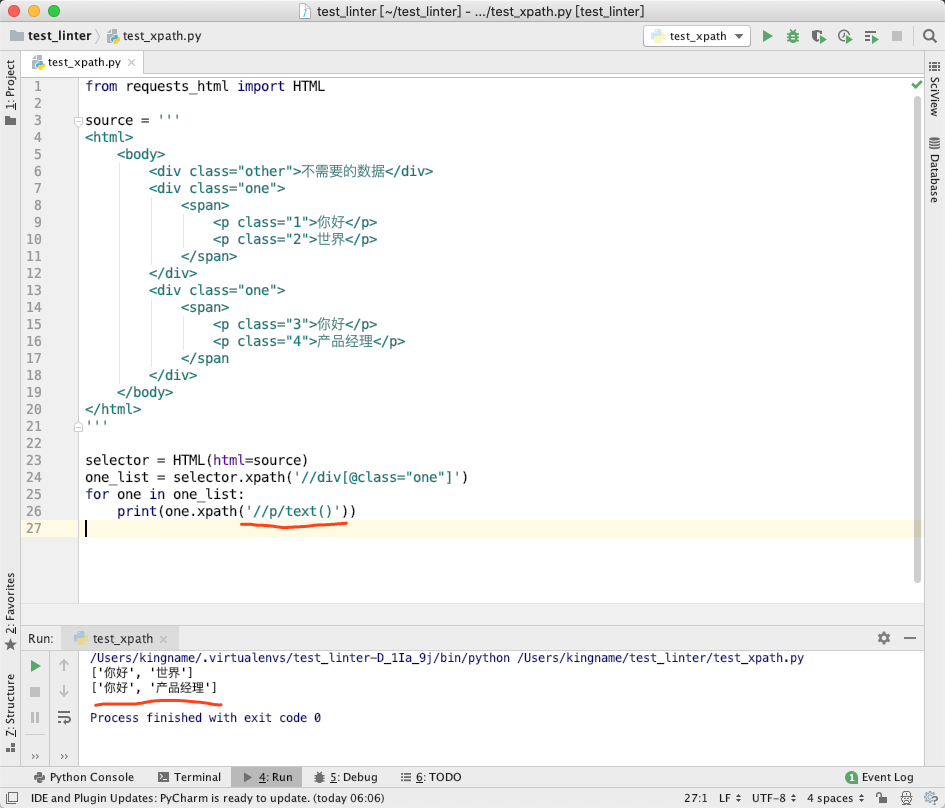
对子 HtmlElement 执行//开头的 XPath,那么它就确实是只在这个 HtmlElement 对应的源代码中寻找数据。看起来更加符合直觉。
这看起来是一个非常人性化的功能。但是,上面我们遇到的那个异常情况,恰恰就是这个人性化的功能带来的怪现象。
为了解释其中的原因,我们来看 requests_html的源代码。本文使用requests_html的 0.10.0 版本。
requests_html的源代码只有一个文件,非常容易阅读。
用 PyCharm 编写上述代码,在 macOS 下,按住键盘Command 并用鼠标左键点击上图代码第 24 行的xpath; Windows 系统按住Ctrl 并用鼠标左键点击 24 行的xpath,跳转到源代码中。没有 PyCharm 的同学可以打开 Github 在线阅读它的源代码但行数可能与本文不一致。
在源代码第 237 行,我们可以看到一个方法叫做xpath,如下图所示:
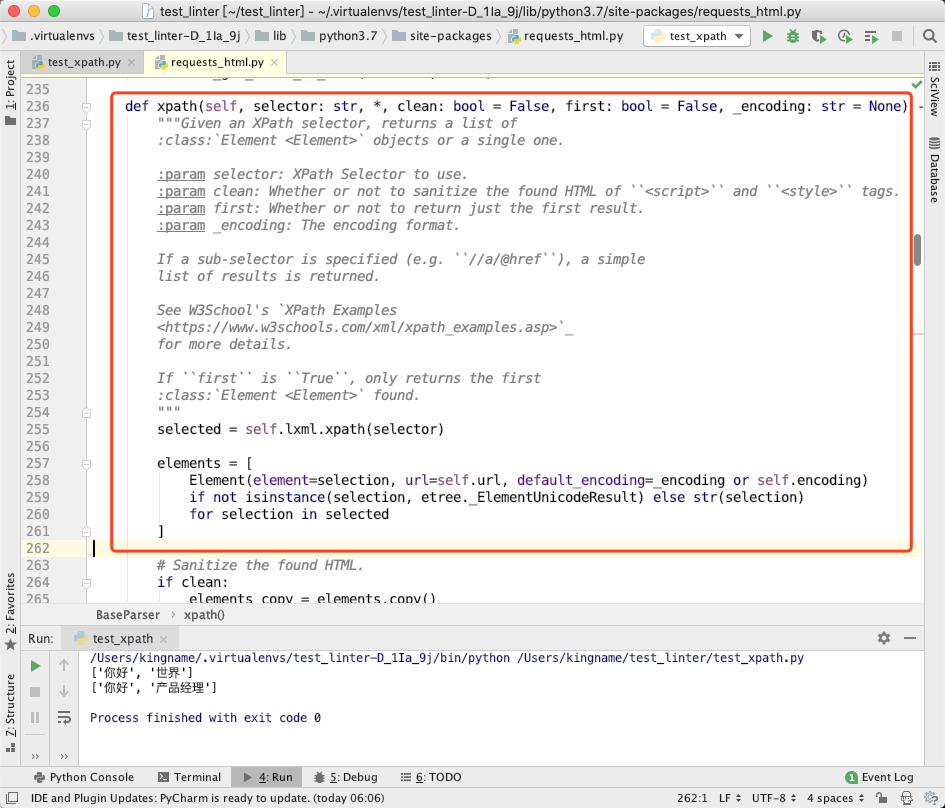
当我们执行selector.xpath的时候,代码就运行到了这里。
代码运行到第 255 行,通过调用self.lxml.xpath真正执行了 XPath 语句。而这里的self.lxml,实际上对应了源代码中的第 154 行的lxml方法:
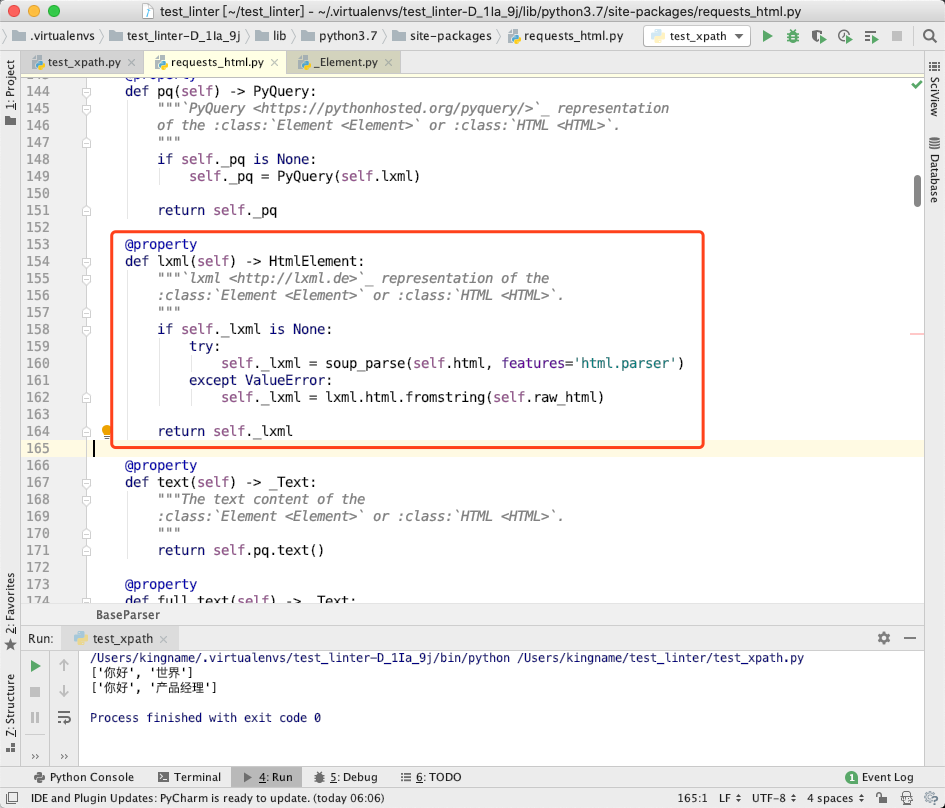
大家在这里是不是看到一个很属性的身影?第 162 行的lxml.html.fromstring。就是标准的 lxml 解析 HTML 的模块。不过它是第 160 行执行失败的时候才会被使用。而第 160 行使用的soup_parse,实际上也是来自于 lxml 库。我们看源代码最上面,第 19 行:
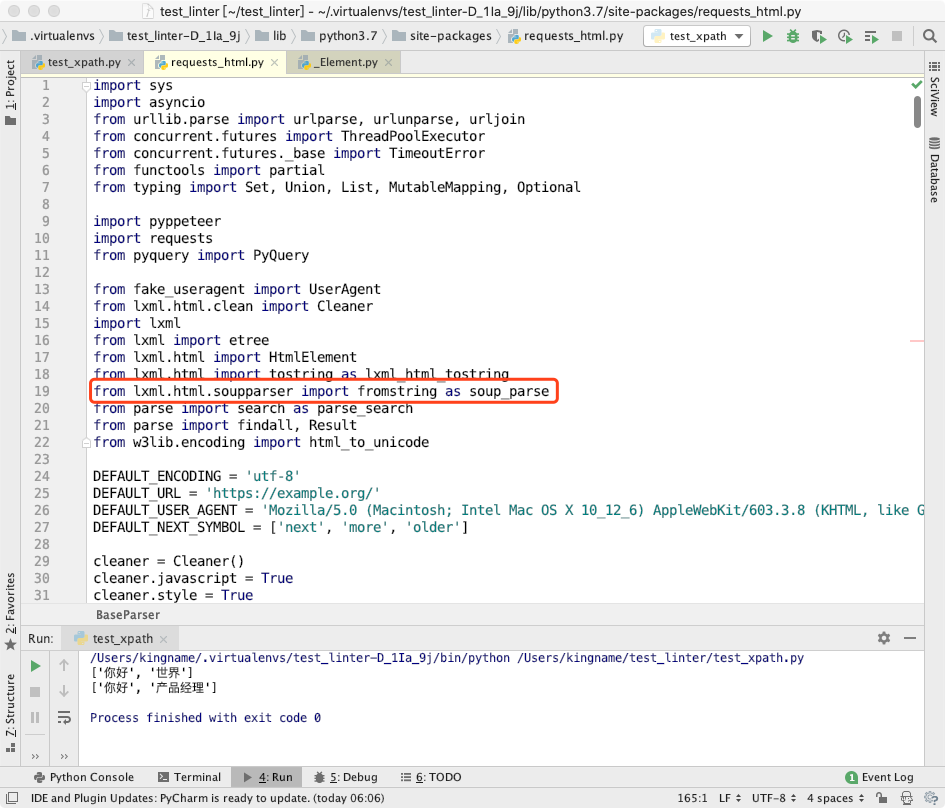
实际上使用的是lxml.html.soupparser.fromstring。
所以,requests_html库本质上还是使用 lxml 来执行 XPath 的!
那么是不是lxml.html.soupparser.fromstring这个模块具有上述的神奇能力呢?实际上不是。我们可以自己写代码来进行验证:
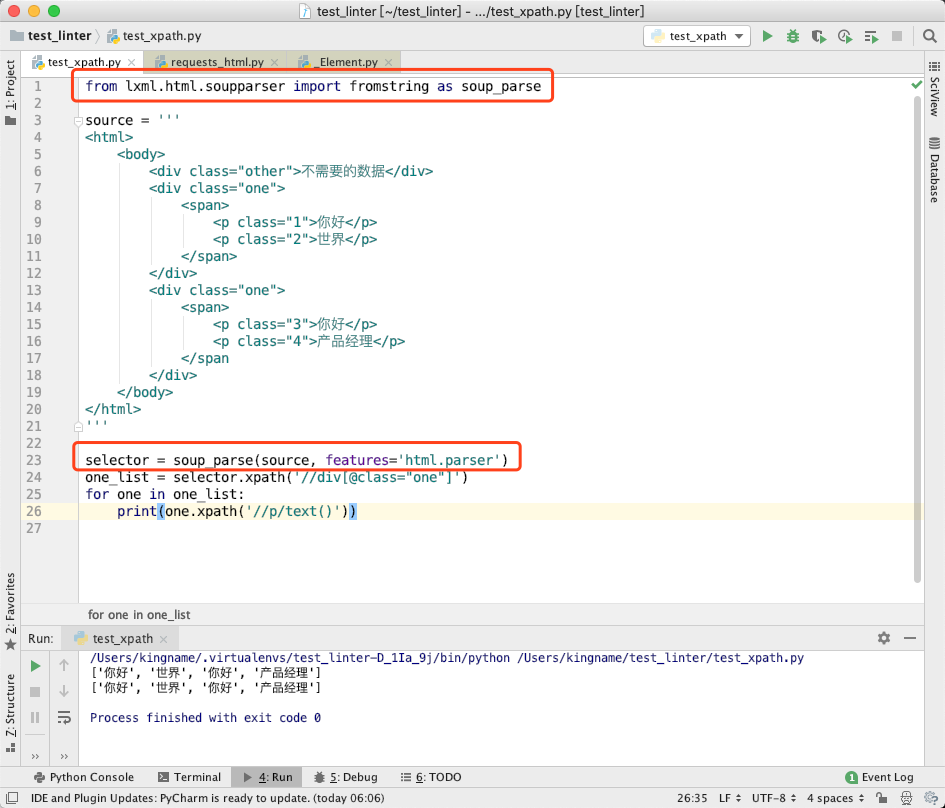
执行结果与我们直接使用lxml.html.fromstring返回的结果完全一致。
为了证明这一点,我们在requests_html的第 257 行下一个断点,让程序停在这里。如下图所示:
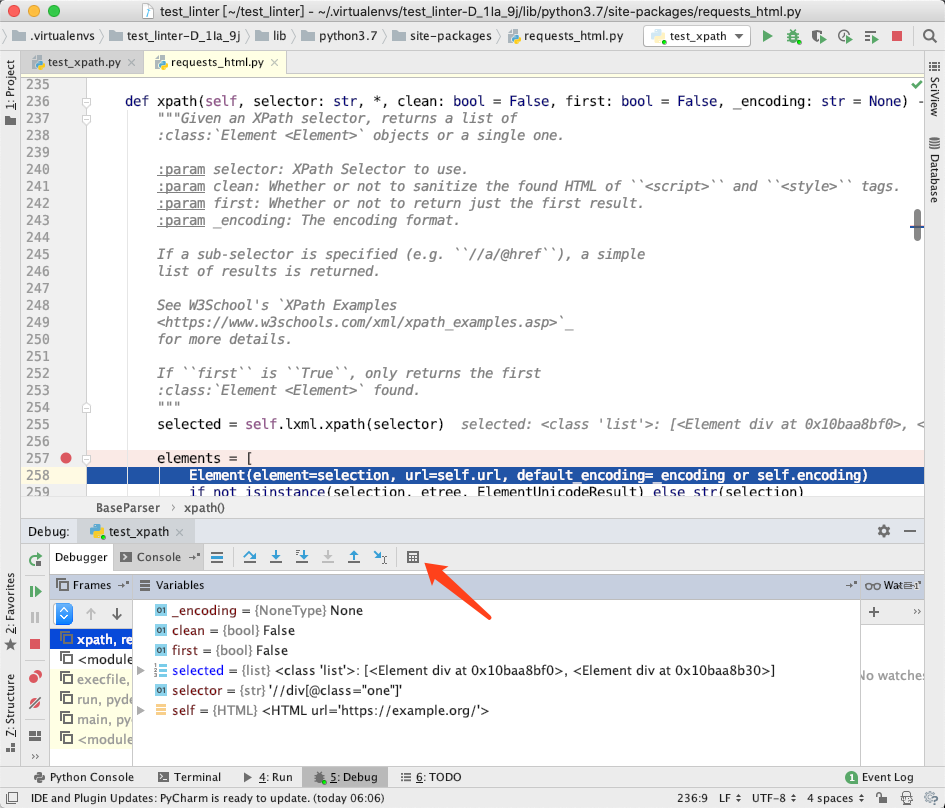
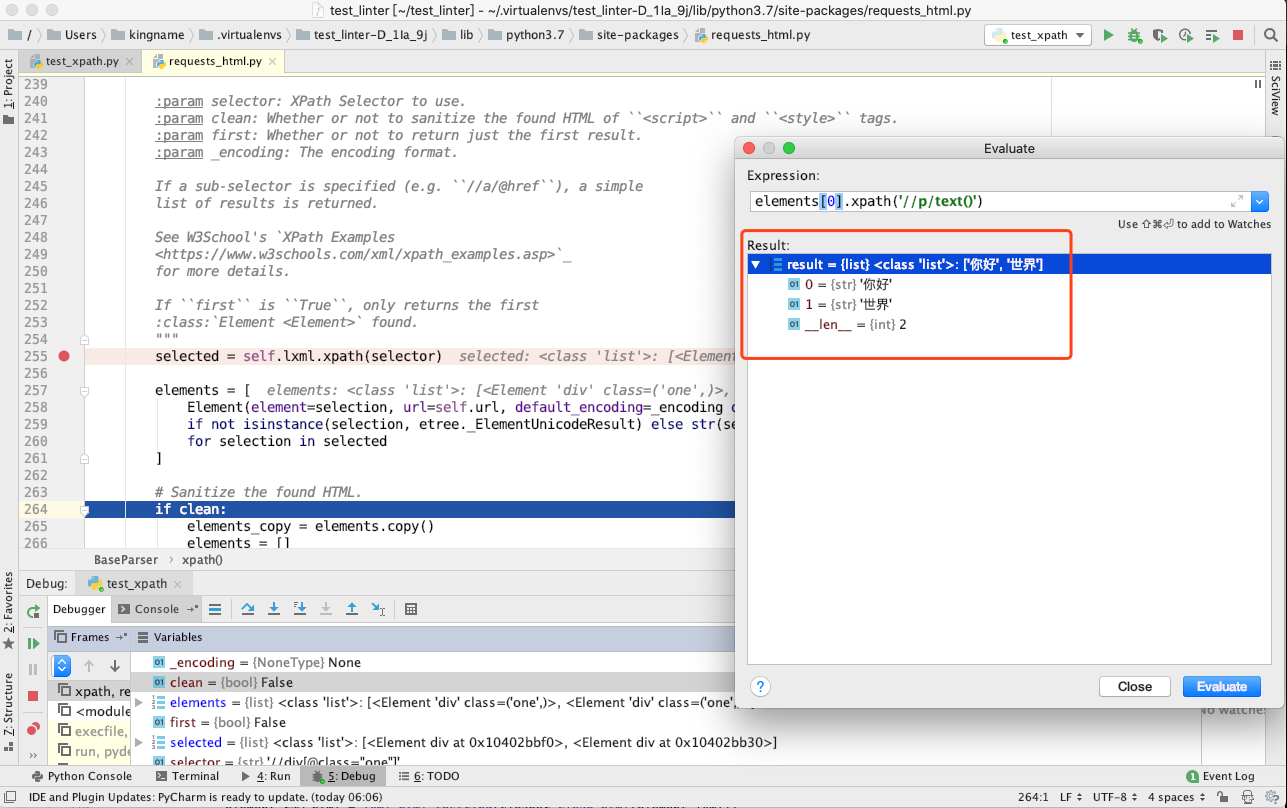
此时,是程序刚刚把class="one"的两个标签通过 XPath 提取出来,生成 HtmlElement 的时候,此时第 255 行的变量selected是一个列表,列表里面有两个 HtmlElement 对象。我们现在如果直接对这两个对象中的一个执行以//开头的 XPath 会怎么样呢?点击红色箭头指向的计算器按钮( Evaluate Expression ),输入代码selected[0].xpath('//p/text()')并点击Evaluate按钮,效果如下图所示:
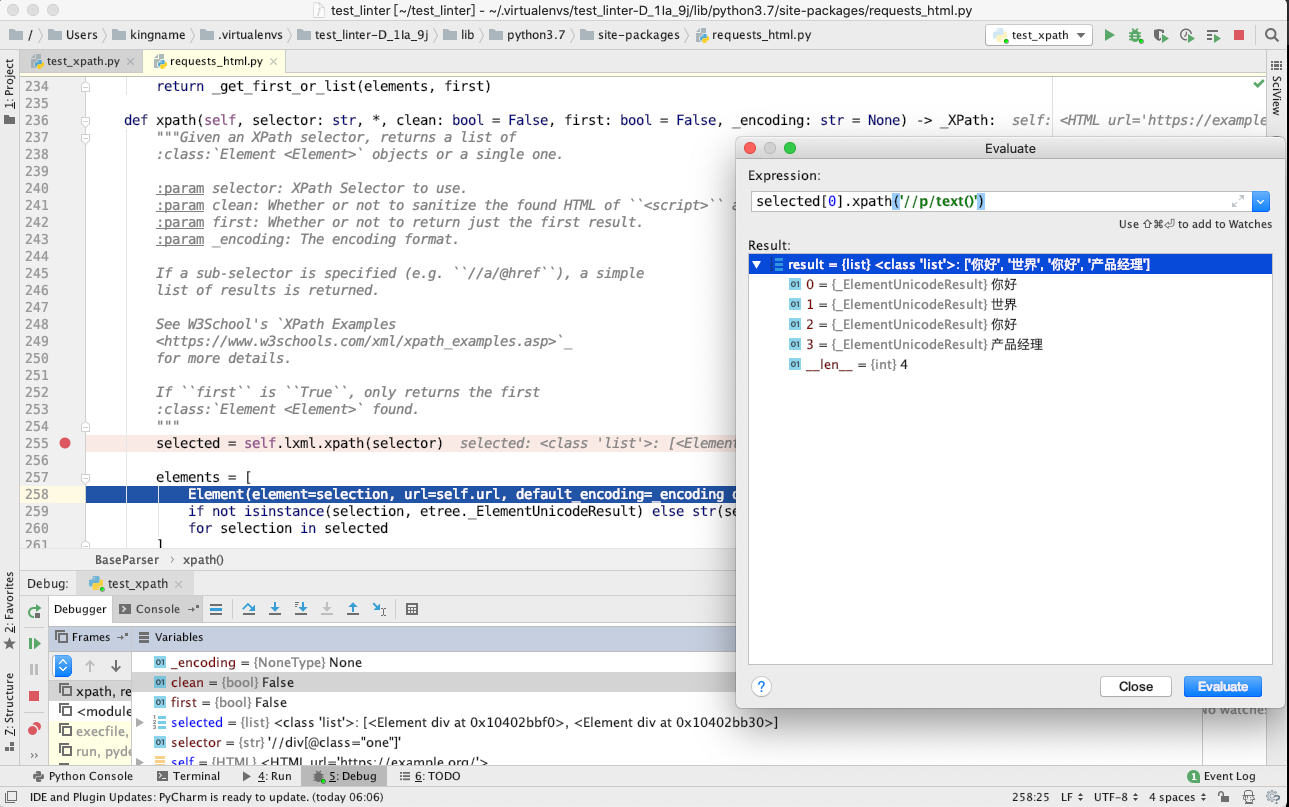
这个返回结果说明,到requests_html源代码的第 255 行运行结束为止,XPath 的运行效果与普通的lxml.html.fromstring保持一致。还不能混用.//和//。
我们再来看源代码的第 257-261 行,这里使用一个列表推导式生成了一个elements列表。这个列表里面是两个 Element 对象。这里的这个Element是requests自定义的。稍后我们再看。
在 PyCharm 的调试模式中,单步执行代码到第 264 行,使得 elements 列表生成完成。然后我们继续在Evaluate Expression窗口中执行 Python 语句:elements[0].xpath('//p/text()'),通过调用 Element 对象的.xpath,我们发现,竟然已经实现了混用.//与//了。如下图所示:
这就说明,requests_html的所谓人性化 XPath 的关键,就藏在Element这个对象中。我们转到代码第 365 行,查看Element类的定义,如下图所示:
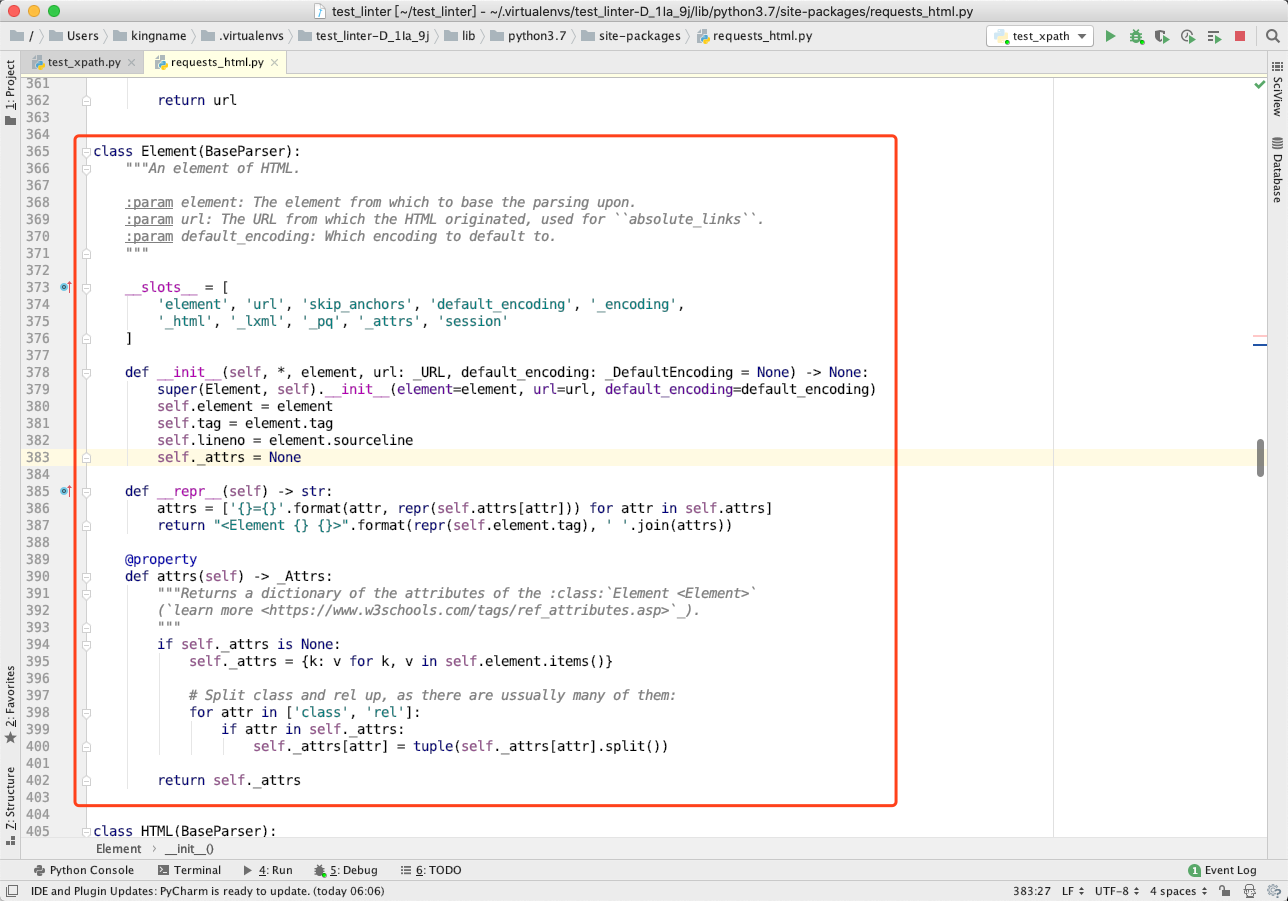
这个类是BaseParser的子类,并且它本身的代码很少。它没有.xpath方法,所以当我们上面调用elements[0].xpath('//p/text()')时,执行的应该是BaseParser中的.xpath方法。
我们来看一BaseParser的.xpath方法,代码在第 236 行:
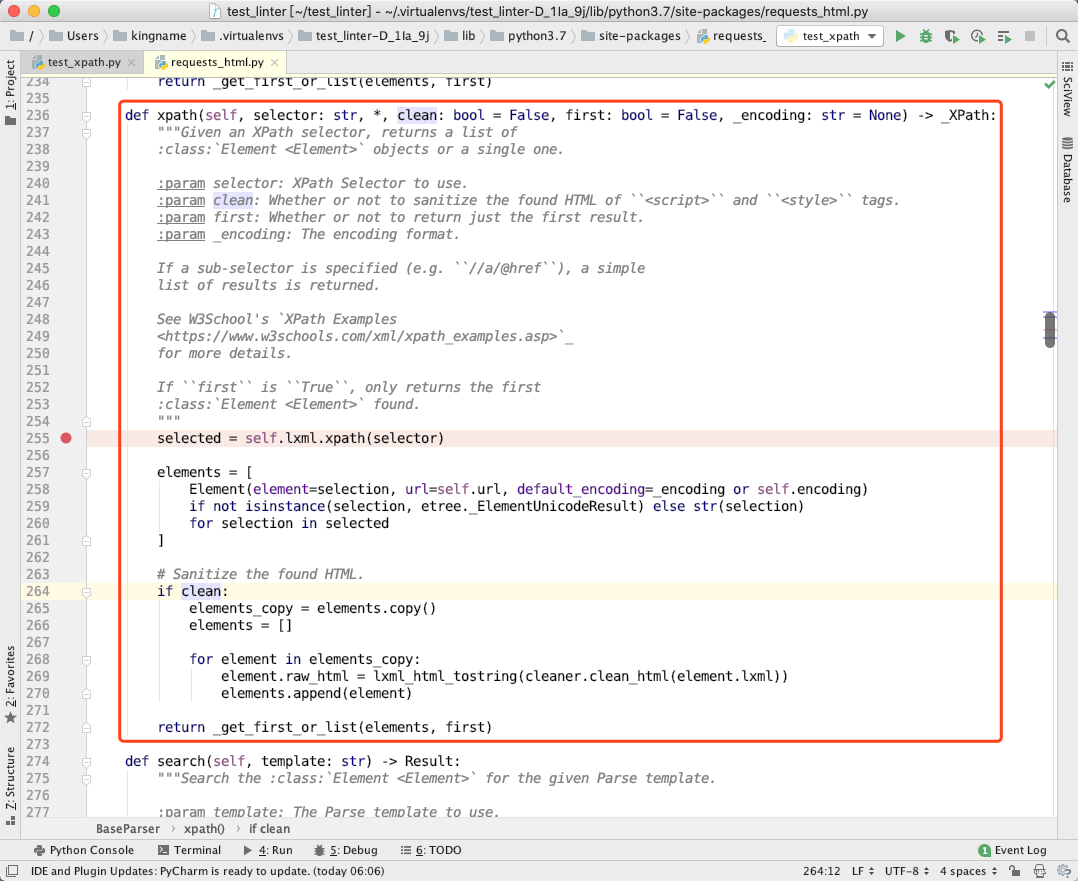
等等,不太对啊。。。


这段代码似曾相识,怎么又转回来了???

先不要惊慌。

我们继续看第 255 行,大家突然意识到一个问题,我们现在是对谁执行的 XPath ?selected = self.lxml.xpath(selector)说明,我们现在是对self.lxml这个对象执行的 XPath。
我们回到第 160 行。
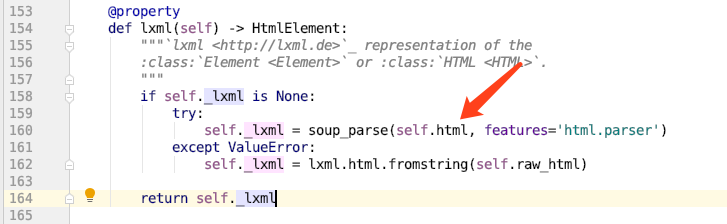
soup_parse的第一个参数self.html是什么?我们转到源代码第 100 行:
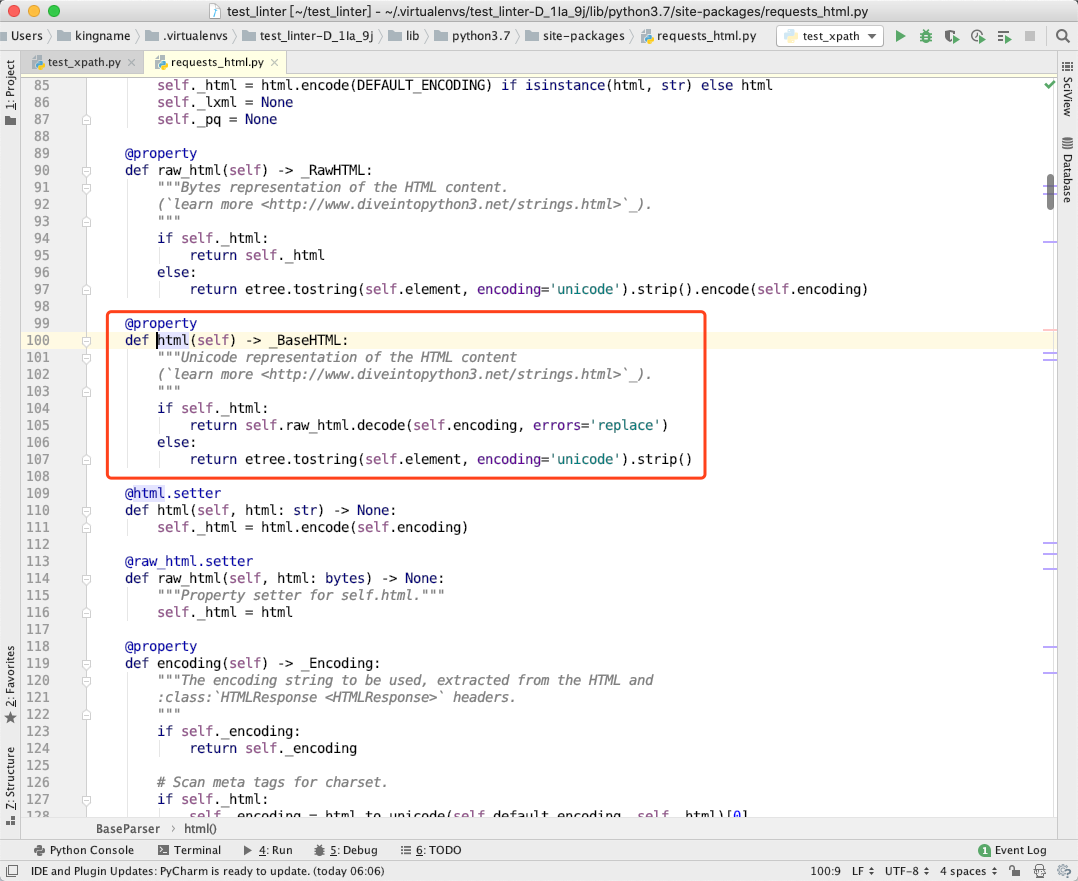
如果self._html不为空,那么返回self.raw_html.decode(self.encoding, errors='replace'),我们目前不知道它是什么,但是肯定是一个字符串。
如果self._html为空,那么执行return etree.tostring(self.element, encoding='unicode').strip()。
我们来看看self._html是什么,来到BaseParser的__init__方法中,源代码第 79 行:
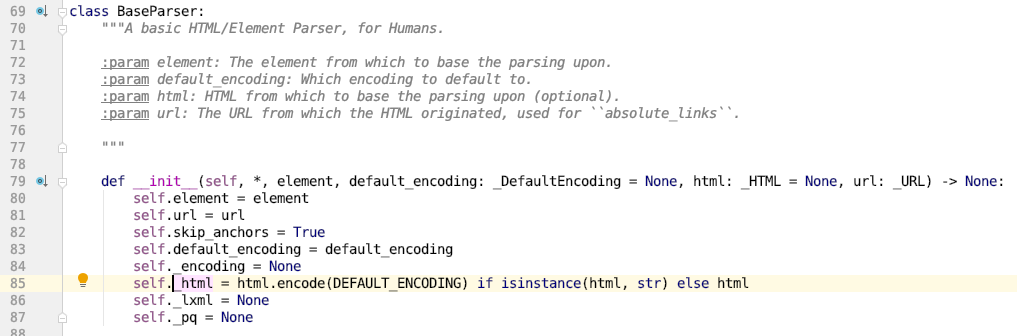
如果在初始化BaseParser时传入了 html 参数并且它是字符串类型,那么self._html就把 html 参数字符串编码为 bytes 型数据。如果它不是字符串,或者没有传入,那么传什么就用什么。
我们现在回到Element类定义的__init__函数中:
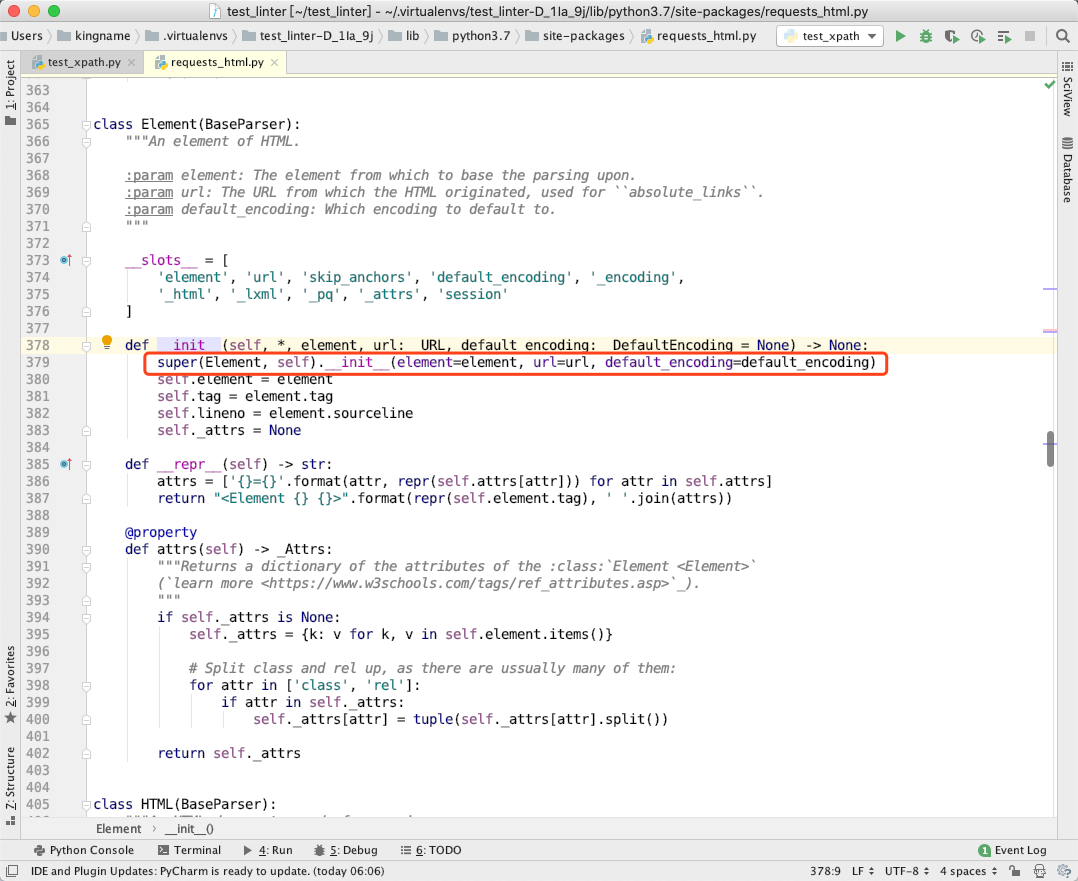
注意第 379 行,Element类初始化地时候,给 BaseParser传入的参数,没有html参数!
所以在BaseParser的__init__方法中,self._html为None!
所以在第 100 行的html属性中,执行的是第 107 行代码!
而第 107 行代码,传给etree.tostring的这个self.element,实际上就是我们第一轮在第 257-261 行传给Element类的参数,也就是使用 lxml 查询//div[@class="one"]时返回的两个 HtmlElement 对象!
那么,把HtmlElement对象传入etree.tostring会产生什么效果呢?我们来做个实验:
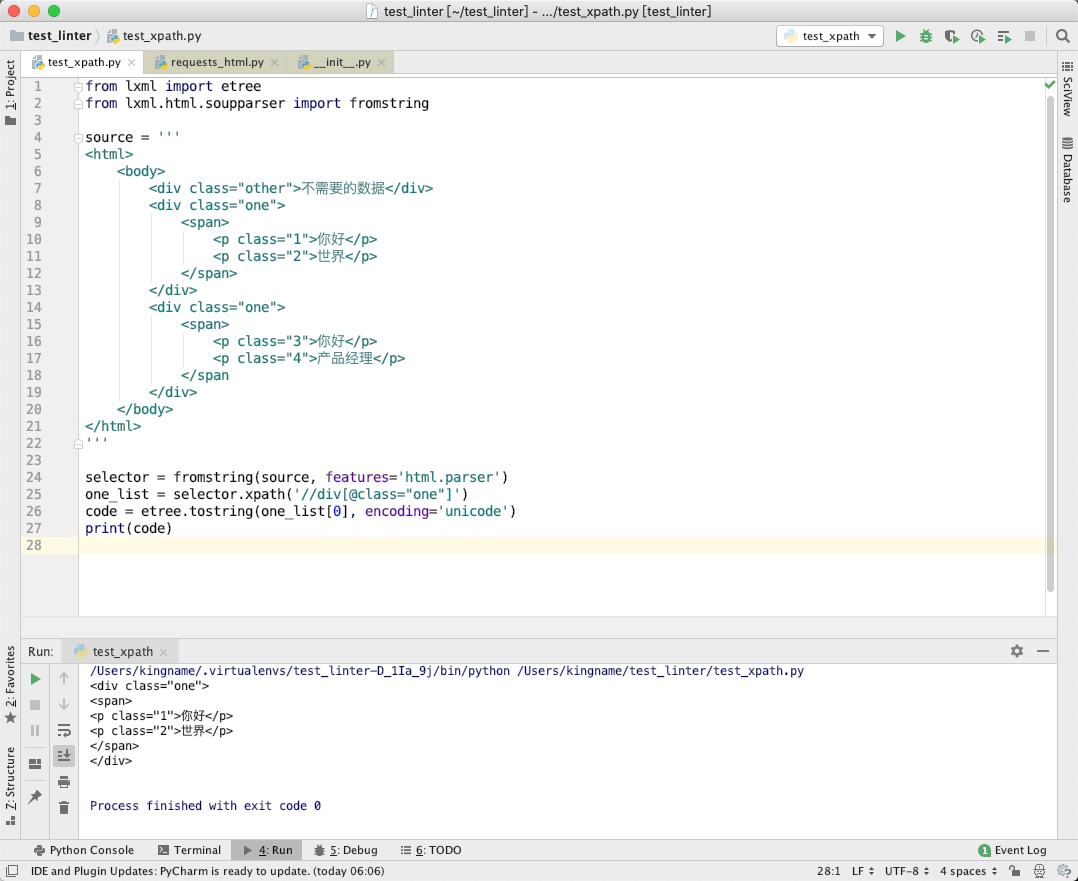
etree.tostring可以把一个HtmlElement对象重新转换为 Html 源代码!

所以在requests_htmls中,它先把我们传给Element的 HtmlElement 对象转成 HtmL 源代码,然后再把源代码使用lxml.html.soupparser.fromstring重新处理一次生成新的 HtmlElement 对象。这样做,就相当于把原始 HTML 中,不相关的内容直接删掉了,只保留当前这个class="one"的 div 标签下面的内容,当然可以直接使用//来查询后代标签了,因为干扰的数据完全没有了!
这就相当于在处理第一层 XPath 返回的 HtmlElement 时,代码变成了:
但是成也萧何,败也萧何。这种处理方式虽然确实有点小聪明,但是如果原始的 HTML 是:
<html>
<body>
<div class="other">不需要的数据</div>
<div class="one">
不需要的数据
<span>
<div class="1">你好</div>
<div class="2">世界</div>
</span>
</div>
<div class="one">
不需要的数据
<span>
<div class="3">你好</div>
<div class="4">产品经理</div>
</span>
不需要的数据
</div>
</body>
</html>
在对//div[@class="one"]返回的 HtmlElement 再次执行 XPath 时,代码等价于对:
<div class="one">
不需要的数据
<span>
<div class="1">你好</div>
<div class="2">世界</div>
</span>
</div>
执行//div/text(),自然就会把不需要的数据也提取下来:
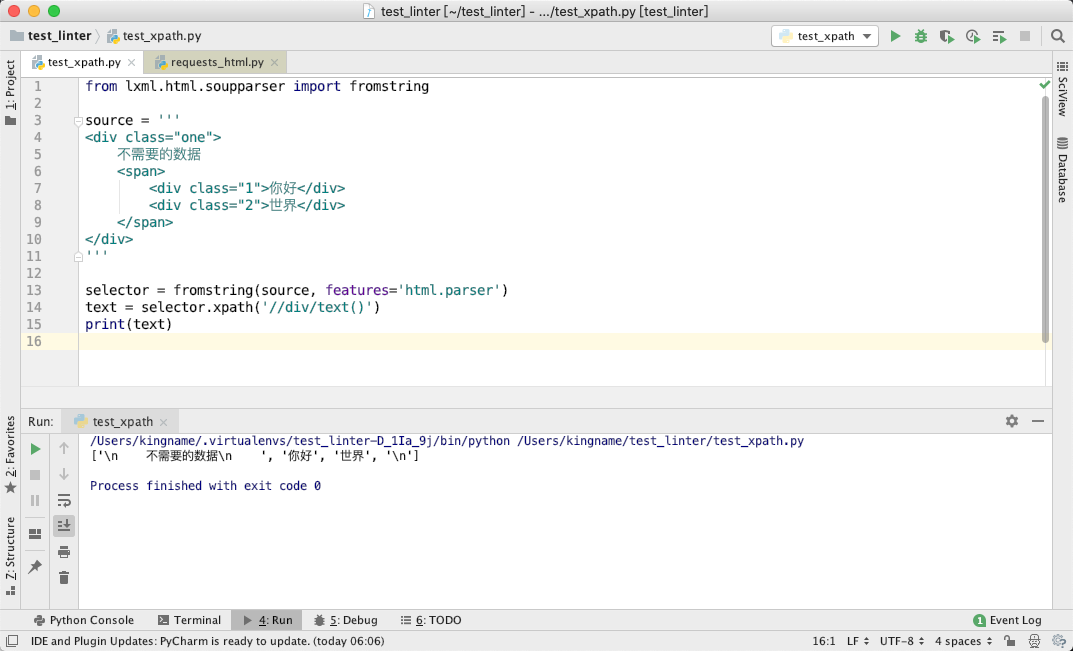
所以,requests_html的这个特性,到底是功能还是 Bug ?我自己平时主要使用 lxml.html.fromstring 或者 Scrapy,所以熟悉了使用.//后,我个人倾向于requests_html这个特性是一个 bug。

 |
1
shaoyijiong 2020 年 2 月 28 日
你是写了一篇博客吗
|
 |
2
Vegetable 2020 年 2 月 28 日
太长了,那么你提的 issue 在哪,我直接去看 issue 更好一点...
|
 |
3
itskingname OP |
|
4
itskingname OP @shaoyijiong 是的。
|