
这是一个创建于 2590 天前的主题,其中的信息可能已经有所发展或是发生改变。
假如有过服务器宕机的恐惧的话,肯定很喜欢这个工具。
每当服务异常的时候,我们第一件事就是查找哪个服务挂了,如果你只有一个服务器,也许也还好,不过只有一个服务器的话估计宕机了也不会有什么恐惧感(这个时候用户量一般还不算大)
可是如果你有很多个服务器,N 多服务,要查清哪个服务出问题了,也不是那么简单。除非你的运维系统已经做的很完备,可是尽管这样,在产品飞速迭代的过程中,每周有新的服务更新上来很正常,这个时候要保证监控到位也是一种挑战。
我刚发现这个国外开发者做的 app:Net Status。
这个 app 可以让你一键 check 所有服务的运行状态,一瞬间你就知道哪个服务出问题了:
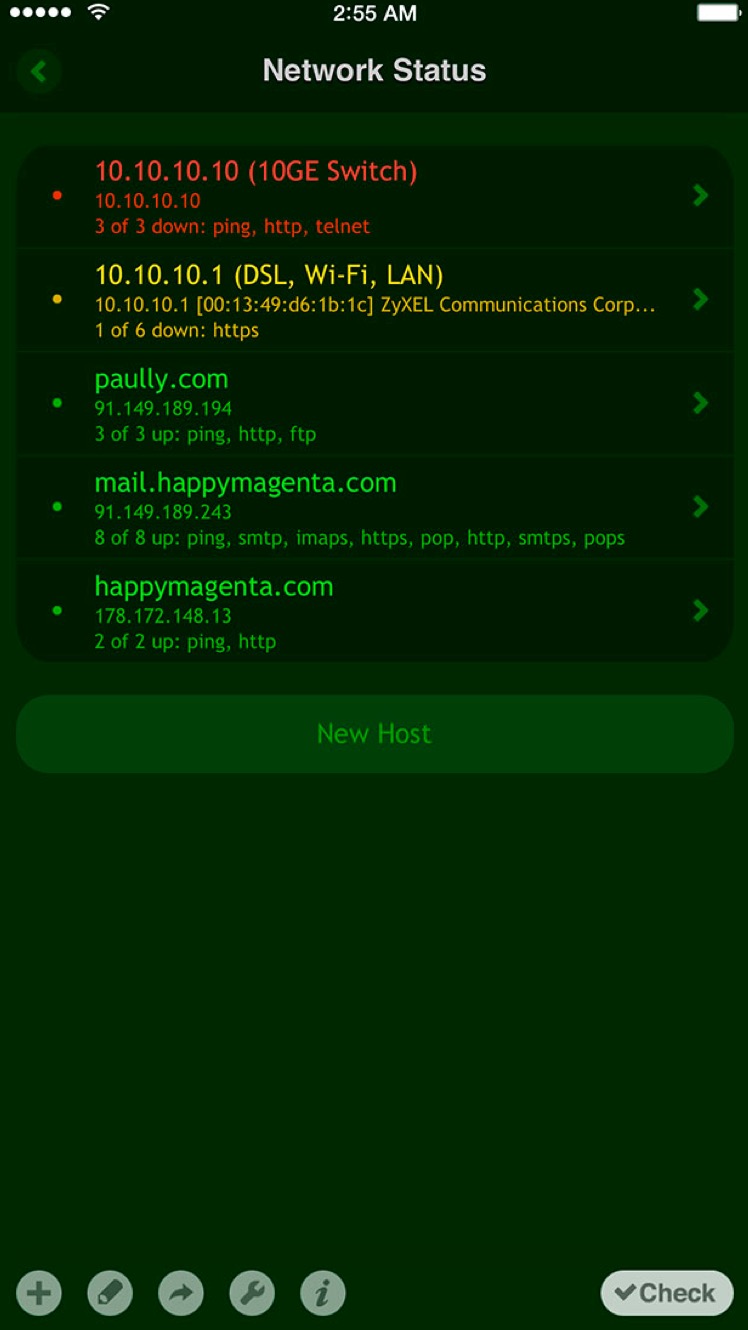
你也可以单独查看每个服务各个端口的运行状态:
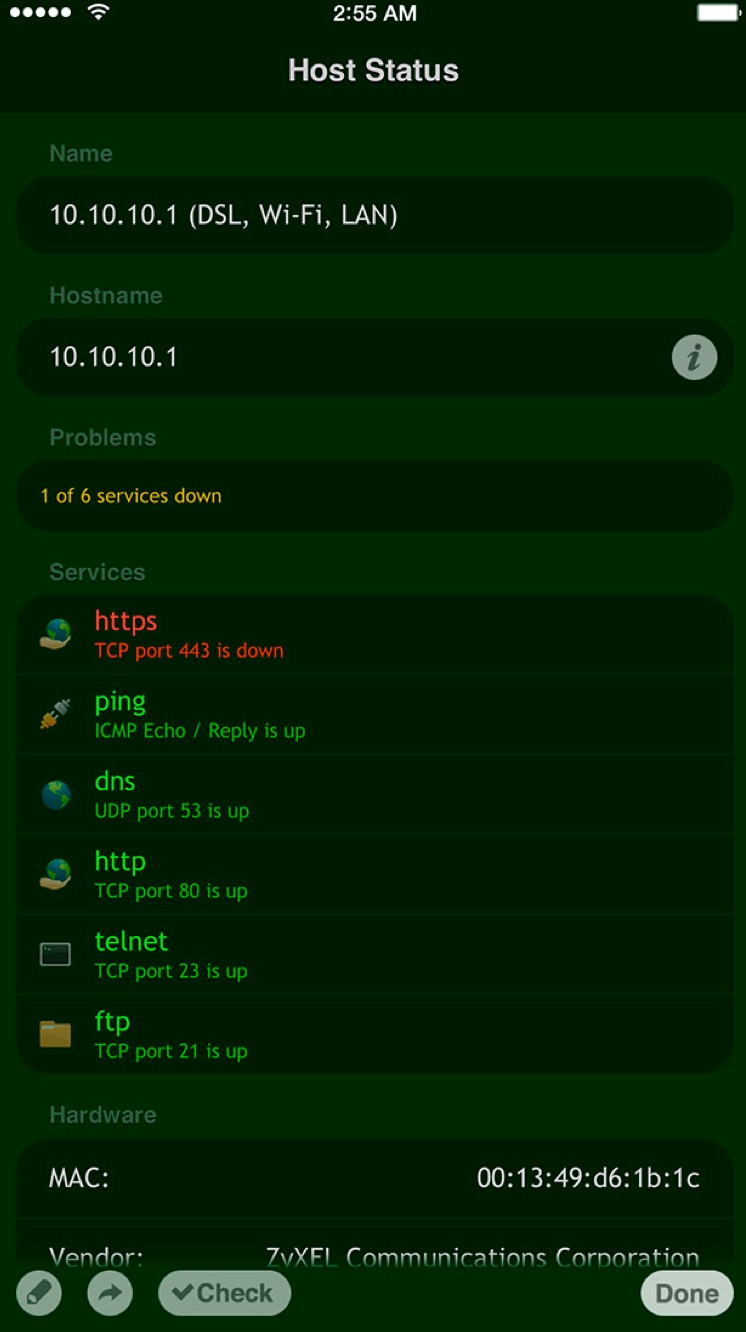
如果对这些功能不感冒的话,至少,你可以用这个 app 装逼:当跟朋友在餐厅吃饭时,朋友抱怨这个 WIFI 好像有点问题的时候,你拿出手机,ping 一下 baidu,然后很淡定的说,“是的,上不了网”
如果对这个 app 好奇,这里有更详细的介绍(有一个视频):Net Status - Server Monitor
最后,心动的话赶紧去下,现在限免中,原价 28 !
 |
1
Cooky 2018 年 12 月 20 日 via Android zabbix,简单有效
|
 |
2
CivAx 2018 年 12 月 20 日 ……事实上是,当服务器出问题时,在运维反应过来之前,产品 /运营 /开发已经开始叫了
(甚至比 App 灵敏) |
 |
4
TangCuYu2333 2018 年 12 月 20 日 via Android
请问 Android 上有没有类似的 app🤔🤔
|
 |
5
raynor2011 2018 年 12 月 20 日
现在云主机都有监控的吧
|
 |
6
tomczhen 2018 年 12 月 20 日 via Android
@TangCuYu2333
Android 上有 ping tools pro,或者用 automate。 |
 |
7
Kilen OP @raynor2011 有的,不过在紧急的情况很不方便,比如阿里云的监控,一次只能看一台服务器的运行状态,如果你有很多台服务器,得疯狂地点~ 一般都得自己用第三方工具做一个所有服务的总览,可是如果服务太多,一页有时候也看不完...
|

 |
9
Raymon111111 2018 年 12 月 20 日
这个一般有监控的, 定时 ping
|
 |
10
xpresslink 2018 年 12 月 20 日
@Kilen 阿里云的控制系统非常方便。估计你不太会用。可以自己定义监控项和告警策略。ECS 出现问题直接通过钉钉 /短信 /手机语音发送警告了,自己去盯着?不存在的。
而且可以自己定义监控大盘,把所有 ECS 基本状态放一个图表里。 |
|
11
raynor2011 2018 年 12 月 20 日
@Kilen 这种现在基本都会弄成报警短信,报警微信之类的,出问题直接通知,比自己人肉监控方便
|
|
12
Kilen OP @xpresslink @raynor2011 我也许说的不是很清楚,这个东西不是为了用来监控服务器,而是一个当服务器出现问题的时候的一个调试工具,可以让你最快速的知道哪个服务出问题了,而不用一个个报警去看(或者如果报警没覆盖全,一个个服务器去看)
|
 |
13
Admstor 2018 年 12 月 20 日
Net Status is a very simple and very fast network and port checking, testing and monitoring app for iPhone, iPad and iOS.
好吧,楼主应该不是运维... 这个工具对运维来说没啥用,就是个批量端口检测,类似的工具太多了 都出故障了我还需要这端口检测干啥...直接就知道哪个服务器挂了...为啥还会说不知道还要查询哪个挂... zibbx 之类可以自动添加新加服务,基本上都是半自动处理 早在服务器挂之前就应该有 overload 警告才对 |
|
14
xpresslink 2018 年 12 月 20 日
@Kilen 我觉得你的语言逻辑出现了问题,你说的场景不存在的。
实在看不懂你这句: 这个东西不是为了用来监控服务器,而是一个当服务器出现问题的时候的一个调试工具,可以让你最快速的知道哪个服务出问题了 也可能我没有把阿里云监控功能说清楚,监控系统会直接发短信告诉你是哪台服务器出了什么问题了,无需自己定位服务器。 |
|
15
xpresslink 2018 年 12 月 20 日
@Admstor 我估计也是这样的,这个小东西在我们专业做运维的眼里连个小玩具都算不上。
|
 |
16
jingniao 2018 年 12 月 20 日 via Android
上架服务器,虚拟机之类的,按照功能命名主机名,然后 zabbix 栽过去也差不多了
|
 |
17
superlks 2018 年 12 月 20 日 via iPhone
5 分钟不上报进程状况,就是一堆电话,邮件,短信,微信告警
|
|
18
Kilen OP @xpresslink
抱歉,那句话确实说的有问题,我想说的是,当网站出问题的时候,通过这个小工具,可以快速定位到哪个进程出问题。 对,确实是,通过监控服务器的 cpu,内存等状态可以覆盖很多问题,而阿里云的报警主要是当这些指标超过阈值才会报警。可是也会有一些情况是尽管服务不正常了,可是却没有引起内存或者 cpu 超过报警的阈值。 比方说,我以为把内存设成超过 80% 报警就很稳妥,可是服务实际上是在 75% 的时候就已经停止服务了怎么办?或者我把内存,cpu 的警报都调优的很好,可是后来用户群炸了,服务不正常了,最后发现漏了监控服务器内网进出带宽? 服务端有趣的点是,每一种语言,每一种架构都有着不同的优劣,当接触到新的技术(比如上了一个 go 服务),会需要继续学习。所以监控的指标也应该是不断迭代的,然后会让自己的监控更准确,甚至预支问题的发生,在用户群炸起来前,已经接到警报,把问题解决。 我确实不是运维,所以也许对于资深运维来说我上面提到的问题不是问题?也许有一套标准化的解决方案?如果是的,很希望看到这个帖子的运维朋友可以给我分享一下。 因为我不是运维,一般来说我不太负责监控,而是当出现网站问题的时候能够快速解决。而我的解决方案很简单,就是遍历每一个服务进程,看看是不是返回一个正常值,或者返回一个正常值的延迟是多少。理论上只要能覆盖每一个服务进程,这个方法就可以 100% 检查出网站哪里出问题了。 而今天看到这个 app,我觉得就是一个更轻量的解决方案了,至少不需要 coding,当然也没有 coding 这么灵活,但也许也是一个很好的小工具了。 |
|
19
TangCuYu2333 2018 年 12 月 21 日 via Android
@tomczhen 谢谢
|
 |
20
4linuxfun 2018 年 12 月 21 日
zabbix 用用就差不多了。。。。
|
 |
21
richzhu 2018 年 12 月 21 日 via iPhone
有 K8S,需要更详细的监控,直接 Prometheus + Grafana 一把梭
|
 |
22
cominghome 2018 年 12 月 21 日
@Kilen
大部分情况下,不光监控服务器,还会监控服务端口,这个是最基本的。进阶一点的,还会做一些接口用专门的数据包来监控服务运行状态。 所以上面几个老哥说的是正确的,这玩意真的连玩具都算不上,如果等到用户投诉才用这个工具去查早 TM 被开除了。 大部分公司面临的监控难不在于单个服务,而在整个业务层,举个例子淘宝下单接口慢,但是没有任何故障上报,甚至机器负载都不高,你怎么定位? |
 |
23
8355 2018 年 12 月 21 日
难道不做监控和邮件报警....
|
|
24
xpresslink 2018 年 12 月 21 日
@Kilen #18
你之所以有这种感觉是因为你没有运维经验,估计你的 LINUX 之类也玩得不够 6,不然你也不能见到这么个小玩意就激动成这样。 实际上现在互联网服务运维已经有了比较完善的成熟方案,比如 k8s 之类,一些大厂用了自己开发的解决方案。 简单地说,现在基本上都是容器化部署了,一个应用至少都会两个以上的实例,负载重的可能会有几十上百个相同实例运行,其中一个完全挂掉了也没有什么影响。而且最重要的是容器如果挂掉了,监控中心就会立刻自动置换一个新容器把应用实例拉起来了,根本不需要运维人员插手。另外监控设施是非常完善的,监控插件直接包括在 docker 基础镜像中了,不存在漏掉监控这个场景,要监控哪些项目也是由集群中的专门配置中心推送的随意定制。CPU/内存 /IO/进程 /端口之类这些都叫基础监控是很小儿科的。实际上比较重要的是业务监控,比如从用户点提交到返回结果全业务链时延都是有监控的。 总之吧,眼界限制了你的想象力。 |
 |
25
boxvivi007 2018 年 12 月 21 日
底层由监控触发故障自动恢复,抓取关键异常数值,前端大屏展示,显示关键全网设备关键信息和业务逻辑关系,楼主的软件说实话不太实用了
|
|
26
Kilen OP @cominghome 用这个的目的不是为了监控,而是为了调试... 是当发现网站不正常的时候,而从监控里又没有发现这么有价值信息的时候,可以用这个来调试。
@xpresslink 我想说的是一个 devops 过程,而不是结果。如果是一个很稳定的网站,比如网站很久才会有比较大的变动,你的监控肯定可以做的很完备。可是如果我的网站一直是用 C 的,突然上来一个 Nodejs 服务,而且还每天都会有新的业务逻辑更新,那么要保证监控跟的上是一个挑战吧。 嗯,k8s 确实很好用,其实上了 k8s,说明这个团队的运维工作也已经俨然有序了,可是一切都会有一个过程,而在运维后台完备之前,需要有个迭代的过程。 我经历过一个高速发展的公司,从每天蹦过渡到非常稳定,而这个工具,对于当时的我,很有用。每个工具都有使用场景吧。 @xpresslink 谢谢分享 |
|
27
Kilen OP 有些朋友提到这个 app 就是一个玩具,对,咸鱼白菜各有所爱,也许这个工具对自己日常工作没帮助。
可是我想说,这个 “玩具” 是某一个开发者,在自己日常工作中遇到的问题,并且给这个世界提供的一个解决方案,也许这个 “玩具” 凝结了这个开发者很多心力。 吐槽两句没什么问题,可是我希望大家内心深处对每一个提供解决方案的开发者保持着尊敬。这也是当我看到一个很有趣的 app 时,为啥会这么兴奋的原因。 |
|
28
cominghome 2018 年 12 月 21 日
@Kilen
---------- 用这个的目的不是为了监控,而是为了调试... 是当发现网站不正常的时候,而从监控里又没有发现这么有价值信息的时候,可以用这个来调试。 一个批量 telnet 工具能调试啥。 ---------- 如果我的网站一直是用 C 的,突然上来一个 Nodejs 服务,而且还每天都会有新的业务逻辑更新,那么要保证监控跟的上是一个挑战吧 太简单了。大部分监控工具并不挑语言。 ---------- 吐槽两句没什么问题,可是我希望大家内心深处对每一个提供解决方案的开发者保持着尊敬。这也是当我看到一个很有趣的 app 时,为啥会这么兴奋的原因。 没有不尊敬开发者。怎么和你形容呢,话说难听点,站在我的角度看这个帖子,就是一个人突然发现把南瓜滚起来这样搬运轻松点,兴奋地广而告之,可是转头一看邻居都已经都农业机械化了所以对这么个主意并不感冒,为了不丢面子仍然坚持使用滚南瓜这样的方式运输自己家的南瓜。 ---------- 最后,我尊重开源,尊重每一个开发者,这个工具可能确实符合某些场景的使用需求,但是过时了就是过时了,自己眼界低就是眼界低,认错要诚恳挨打要站稳。也不是大家一味地批评你,你这个标题,我还真以为你找到个东西比 zabbix 简便好用比普罗米修斯靠谱,结果... |