
这是一个创建于 2618 天前的主题,其中的信息可能已经有所发展或是发生改变。
精准测试从某个层面来讲,是赋予了测试用例真正的生命力,传统的测试用例仅仅是一些只能够依赖人去理解和分析的文本文件而已,在计算机和算法层面则没有存在意义和价值。下图是精准测试的整体架构图:
大家首先可能会比较好奇,“用例魔方”的概念是怎么来的?测试用例魔方是在精准测试的设计、开发和商业实践中自然产生的功能集合的一个统称。当我们把精准测试的和用例分析相关的功能画成架构图形表示的时候,它自然而然地看起来就像魔方,所谓“魔”则是精准测试核心算法所赋予的超能力。
上图是星云精准测试系统的总体结构图,“测试魔方”即分布在左上角区域。大家知道精准测试的核心技术是测试用例与代码的追溯关系的建立,而在此之上就可以构建测试魔方的核心功能区。如下:
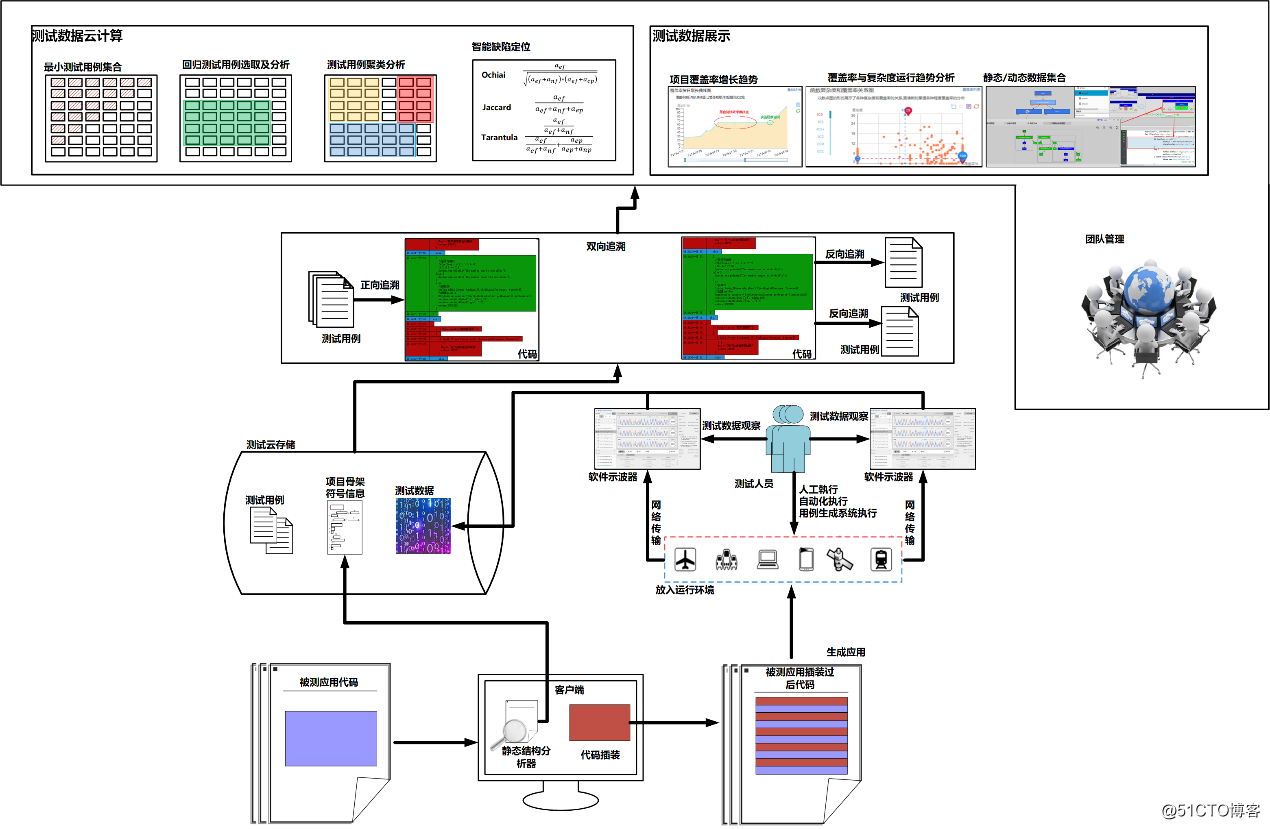
所谓“方”实际上是代表测试用例的集合,每个测试用例用一个小方块标识,所有测试用例的集合用一个大方块。现在来看在精准测试架构下,“用例魔方”所能够提供的功能(对精准测试的底层技术不是很了解的话,可以预先温习下《精准测试框架白皮书》)。精准测试体系中,测试用例对应的代码逻辑都可以实现全自动的追溯和存储,因此测试用例就具备了进行深入分析的基础。在精准测试的用例魔方中,目前存在三个面(随着后续功能的增加,将增加分析的面),即回归测试用例选取、测试用例聚类分析、测试用最小化,同时辅之以智能缺陷定位技术。下面对“用例魔方”做详细的说明,选用的工具为星云精准测试平台 ThreadingTest 产品系列。
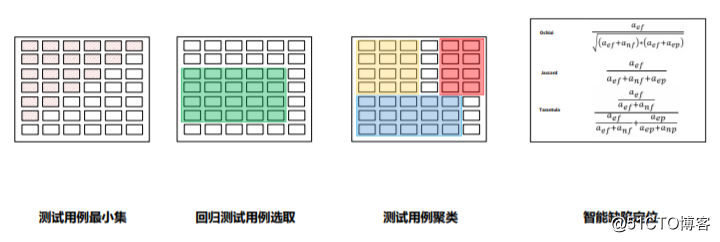
首先介绍回归测试用例选取。从魔方视图中可以看到回归用例选取(主要选取可能影响到的重点用例)。精准测试中所谓的回归测试和自动化回归有很大的差别,我们听的比较多的自动化测试中的回归其实是把自动化用例重新运行的意思,而精准测试中的回归测试是通过内部算法自动选取新版本修改后可能影响到的测试用例。通过回归测试用例选取,解决了新版本上线该对哪些用例进行测试和重点测试的问题,这也是敏捷开发中测试所面临的最大问题。下面是回归测试用例选取的原理图:
原理介绍:
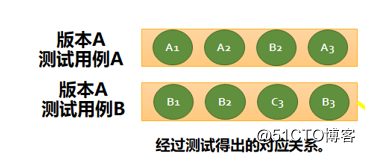
测试用例 A 与测试用例 B 为在版本 A 中进行测试的用例,其绿圈中 A1、A2、A3、B2 …等为其测试用例所对应的运行中采集的函数信息。
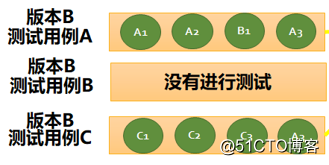
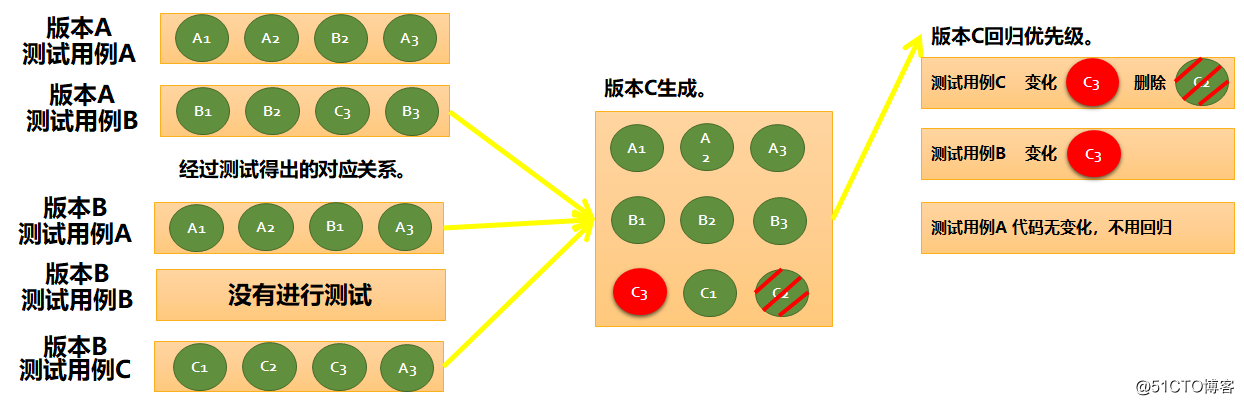
在版本迭代过程中,版本 B 也对其测试用例 A 进行了测试,并添加了测试用例 C,精准测试采集其对应的函数信息。
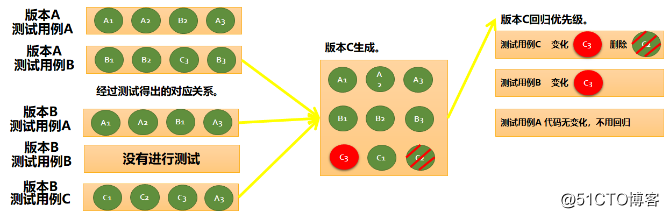
当版本 C 进行迭代发布时,精准测试根据测试用例 A、B、C 最后运行的版本所对应的函数信息与版本 C 的版本函数信息进行比较,根据变化差异进行回归优先级排序。
① 测试用例 A 最后运行在版本 B 中,对应的函数信息为 A1、A2、B1、A3,对比版本 C 中的函数无代码变化,计算回归优先级值为 0。
② 测试用例 B 因为在版本 B 中未运行,最后运行的版本为 A,版本 A 的测试数据 B1、B2、B3、C3 和版本 C 中的函数比对,得出函数 C3 的代码有变化,计算回归优先级值为 1。
③ 测试用例 C 最后运行在 B,对应的函数信息为 C1、C2、C3、A3,和版本 C 中的函数比对,得出函数 C3 的代码有变化,函数 C2 进行了删除,计算回归优先级值为 3。
④ 结果进行回归优先级排序,得出测试用例 C 回归优先级最高优先值为 3>测试用例 B 回归优先值为 1>测试用例 A,回归优先值 0,不需要回归。
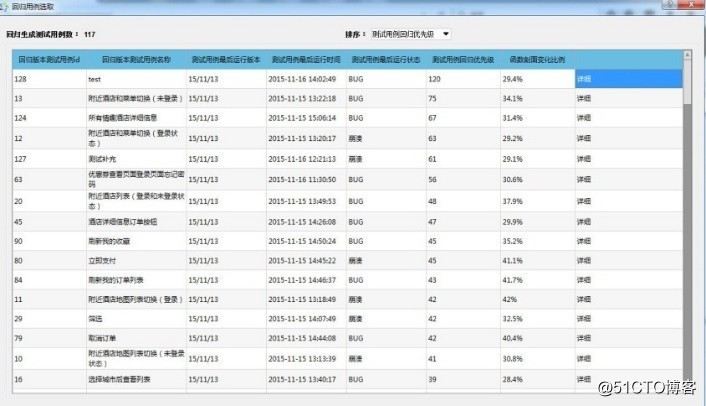
当新版本上线后,精准测试系统会自动给出本次发布波及到的测试用例列表以及收到波及的程度。如下图:
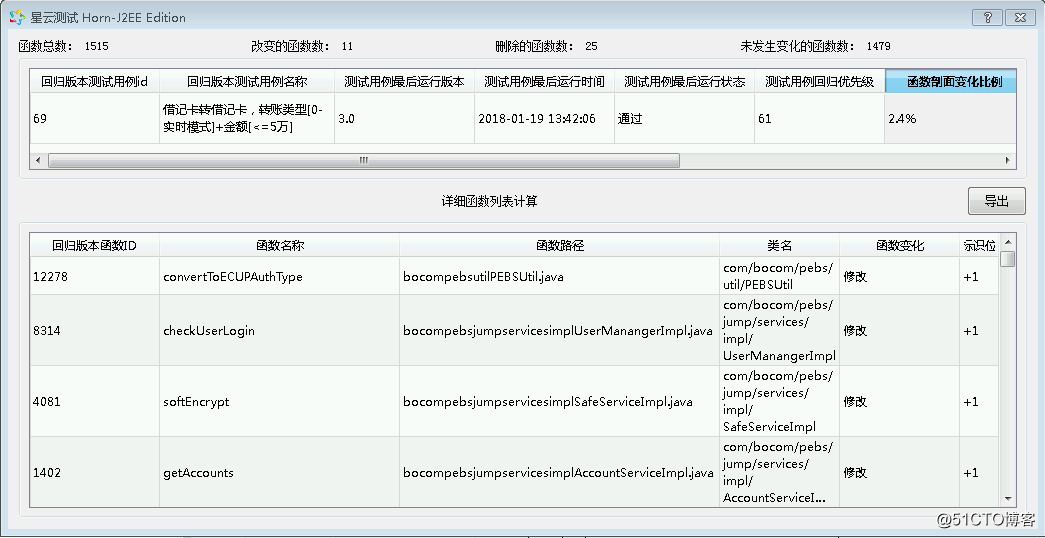
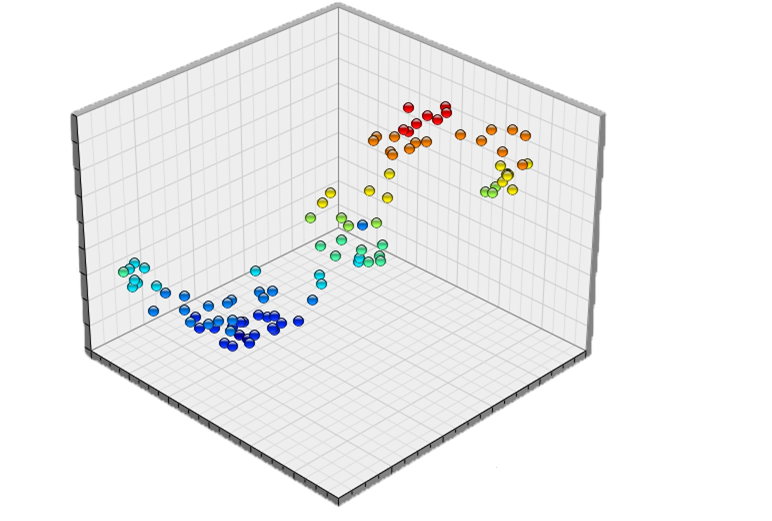
通常测试用例的分类都是人工根据功能组织进行硬性归类的,在精准测试体系中,用例魔方中的测试用例为聚类分析。由于测试用例都包含有对应的内部代码执行逻辑,执行路径直接可以通过代码块或者函数进行举例计算,例如一个程序总共有 10 个函数。
“用例魔方”中的聚类结果具有非常实用的价值,体现在以下几点:
1.通过用例聚类结果,可以从管理端审核测试执行的正确性。传统测试一般由人工执行,因此想确认测试用例是否本身执行有错误,或者是否按照预先设定的要求执行了,是非常困难的,这也是测试管理的成本一直很高的一个重要原因。通过对精准测试“用例魔方”的聚类结果分析,若两个功能迥异、本不应该分到一起的测试用例被分到了一组,那么产品经理或者项目管理者会非常容易识别出这里面存在测试用例的执行错误,并在产品发布的最后一环,及时处理。
2.通过“用例魔方”的测试用例聚类结果这一功能,可以发现缺陷分布的密集区域。因为聚类的依据是用例执行对应的代码路径差异信息,聚类结果充分而真实的体现了用例之间的空间感,结果非常有意义。缺陷的分布一般是有规律的:功能相近的用例如果有出现错误,那么同类型用例出错的概率也更大。所以当时间不充足的情况下,可以依据聚类结果,每个用例聚类簇随机选几个。如果没有 bug,就可以放松对簇内其他用例的考察,如果发现了缺陷,那么其它簇内的用例也需要重点考察。
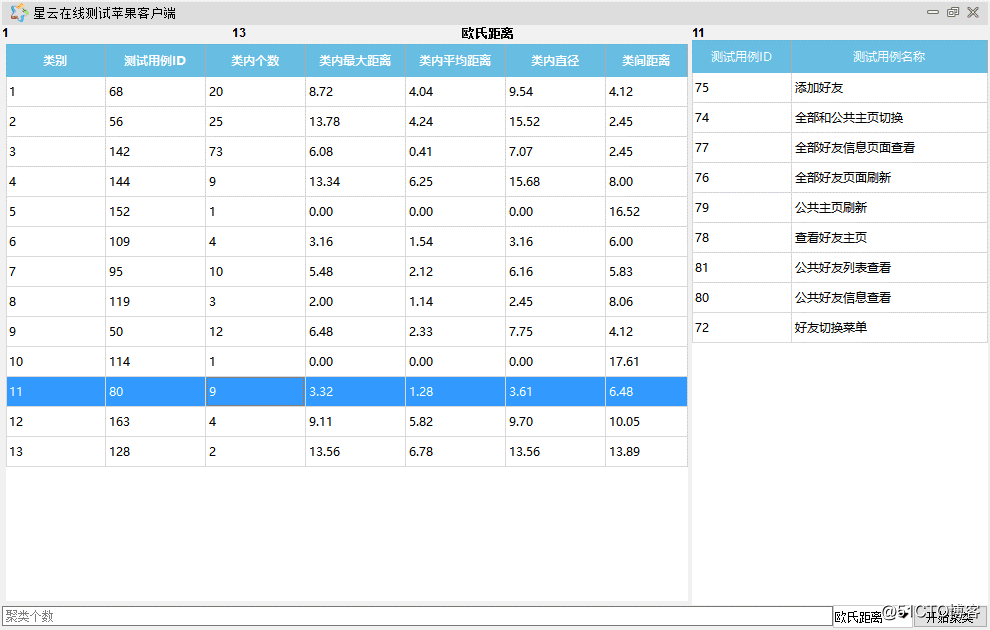
在企业大量应用自动化测试场景下,随着日积月累,产生了大量的、逻辑重复的测试用例。通过“用例魔方”的测试用例集最小化算法,可以把重复或者存在包含关系的用例从用例集中剔除出去。原理非常简单:假设两个用例,在代码覆盖上存在完全包含关系,那么被包含的用例就可以从用例集中剔除。算法所依据的数据依然是测试用例与代码的追溯关系技术数据。
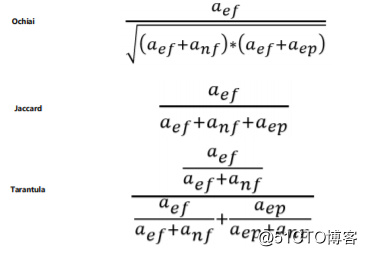
“用例魔方”中另外一个精彩的功能是智能的缺陷定位技术,星云精准测试提供了 3 种计算公式。

通过智能缺陷定位,测试工程师仅需要标记用例从功能角度的执行状态(是否存在缺陷),再结合星云精准测试“用例魔方”自动记录的对应程序执行的代码频谱,就可以对缺陷进行代码级的精准定位。 1.源代码
简单分析第 15 行代码,当第十行 y<z 成立且第十二行 x<y 不成立且第十四行 x<z 成立时即得 y<z 且 x>=y 且 x<z.此时可得 y<=x<z,中间数为 x,所以此处正确语句应为 m=x。

2.创建 7 个测试用例 test1、test2、test3 ………..test7 并进行测试
① test1 输入为 3 3 5 输出为 3,预期输出为 3,符合预期,此用例记为通过
② test2 输入为 1 2 3 输出为 2,预期输出为 2,符合预期,此用例记为通过
③ test3 输入为 3 2 1 输出为 2,预期输出为 2,符合预期,此用例记为通过
④ test4 输入为 5 5 5 输出为 5,预期输出为 5,符合预期,此用例记为通过
⑤ test5 输入为 5 3 4 输出为 4,预期输出为 4,符合预期,此用例记为通过
⑥ test6 输入为 2 1 3 输出为 1,预期输出为 2,不符合预期,此用例记为未通过
⑦ test7 输入为 3 2 4 输出为 2,预期输出为 3,不符合预期,此用例记为未通过
3.针对 test6、test7 提交缺陷,表明 test6 与 test7 输出与预期不符
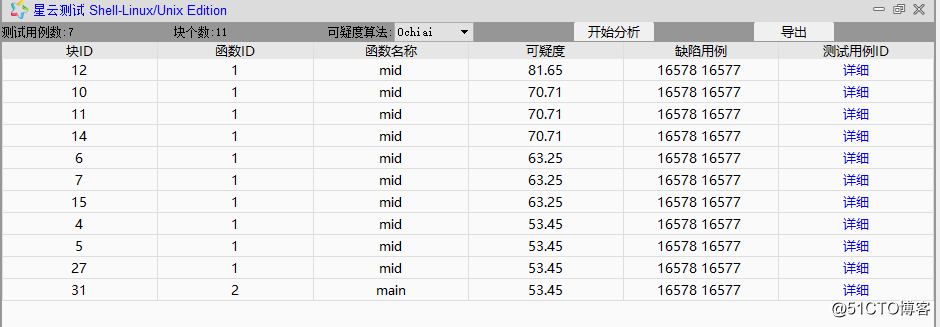
4.打开缺陷分析界面进行分析
5.可疑度算法包括如下三种,可自主选择
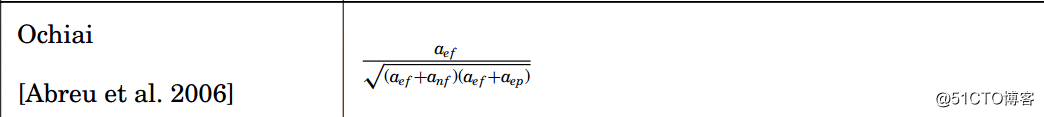
其中 aep 表示通过且覆盖到该块的测试用例的个数、anp 表示通过且未覆盖到该块的测试用例的个数、aef 表示未通过且覆盖到该块的测试用例的个数、anf 表示未通过且覆盖到该块的测试用例的个数。结果表示该块的可疑度。
6.代码可视化查看位置
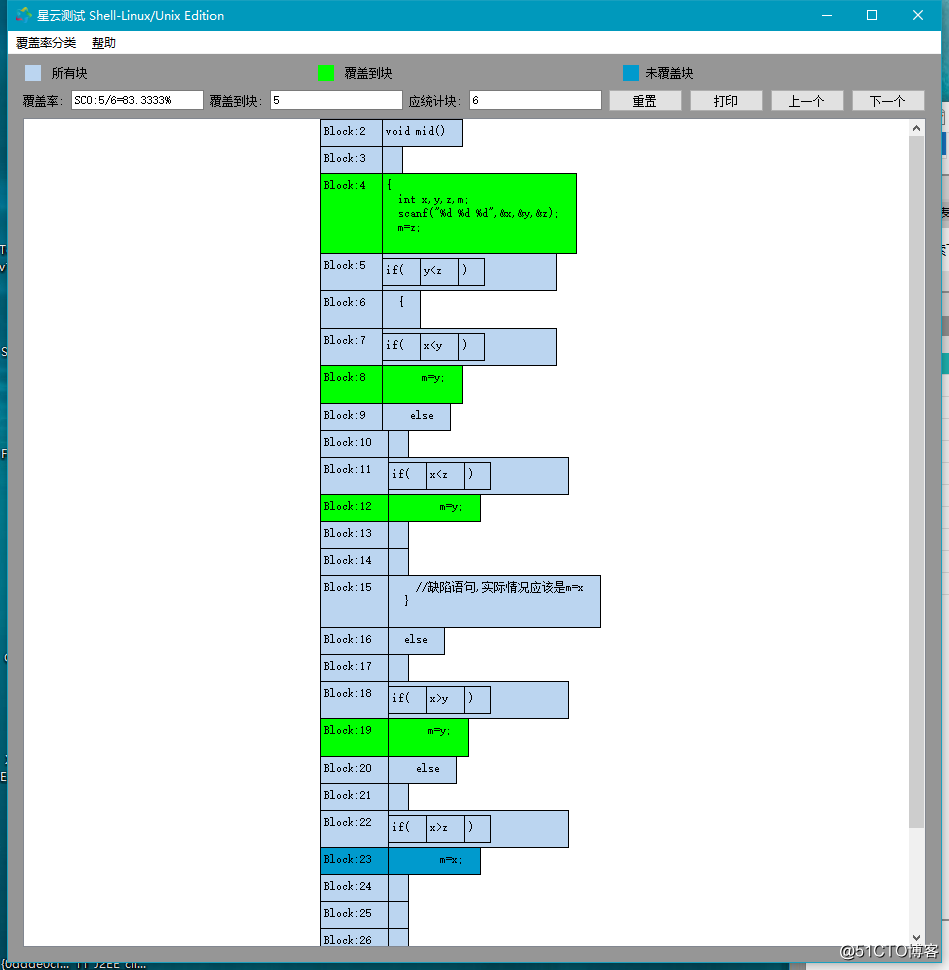
关联源码之后可根据代码可视化定位第十二块位置,根据实际分析可得第十二块确实为缺陷语句,分析过程见第一步。
(大家如果感兴趣可以到星云测试的官网上 www.teststars.cc 试用。)
精准测试的精髓在于通过专用测试软件实现表层功能和底层代码的关联,并且获取成本很低。它在测试用例执行的过程中,通过软件示波器以透明方式自动获取两者的关联关系。通过精准测试系统,使针对用例的深入分析“用例魔方”成为可能。目前精准测试的核心用例分析算法正在持续增强,“用例魔方”的软件研发辅助分析功能,为软件测试的智能化、专业化成长,带来曙光和方向。
 |
1
nanlou 2018 年 12 月 5 日
关注了很久,不知道到底有无实际大型工程的实践或者行业案例可以拿出来说一下
|
 |
2
1953892121 OP 实际案例很多,都是大型的工程,http://www.teststars.cc/case.html,需详细了解可联系我们深入了解!
|