
这是一个创建于 2622 天前的主题,其中的信息可能已经有所发展或是发生改变。
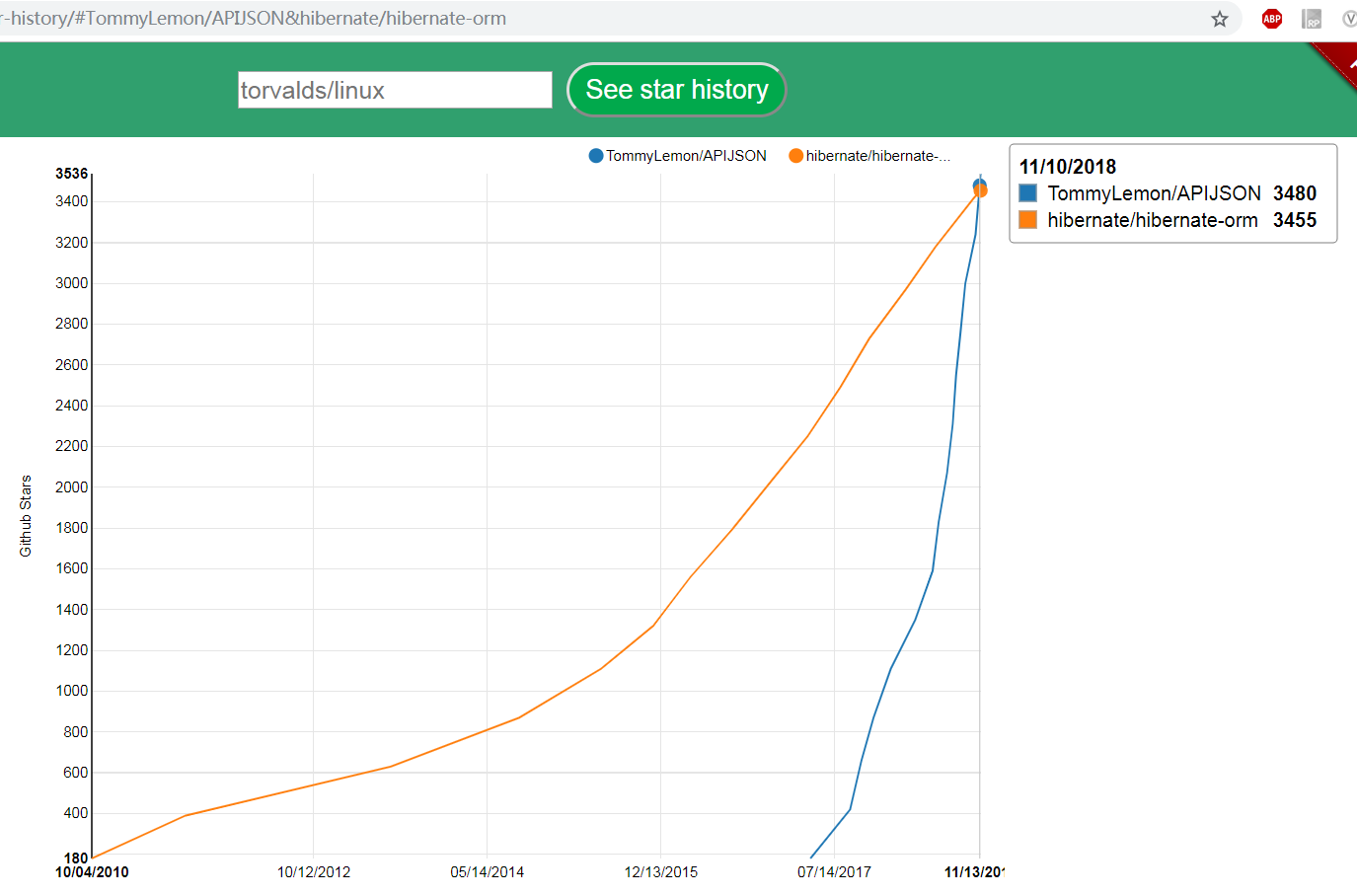 https://www.timqian.com/star-history/#TommyLemon/APIJSON&hibernate/hibernate-orm
https://www.timqian.com/star-history/#TommyLemon/APIJSON&hibernate/hibernate-orm
众所周知,Hibernate 是 Java 的第 2 大开源 ORM 库,从 2007 年开源到现在已经有近 12 年的历史。
廉颇老矣,尚能饭否? 长江后浪推前浪,一代新库换旧库。
为什么 APIJSON 从 2016 年 11 月开源后短短 2 年就超过它了呢?
因为 APIJSON 是自动化的,后端不用写代码,就能自动解析前端传的 JSON 参数,
自动转为 SQL 语句并连接数据库执行,然后返回对应的 JSON 结果,
期间自动校验权限、数据、结构,自动防 SQL 注入。
对于前端
- 不用再向后端催接口、求文档
- 数据和结构完全定制,要啥有啥
- 看请求知结果,所求即所得
- 可一次获取任何数据、任何结构
- 能去除重复数据,节省流量提高速度
对于后端
- 提供通用接口,大部分 API 不用再写
- 自动生成文档,不用再编写和维护
- 自动校验权限、自动管理版本、自动防 SQL 注入
- 开放 API 无需划分版本,始终保持兼容
- 支持增删改查、模糊搜索、正则匹配、远程函数等
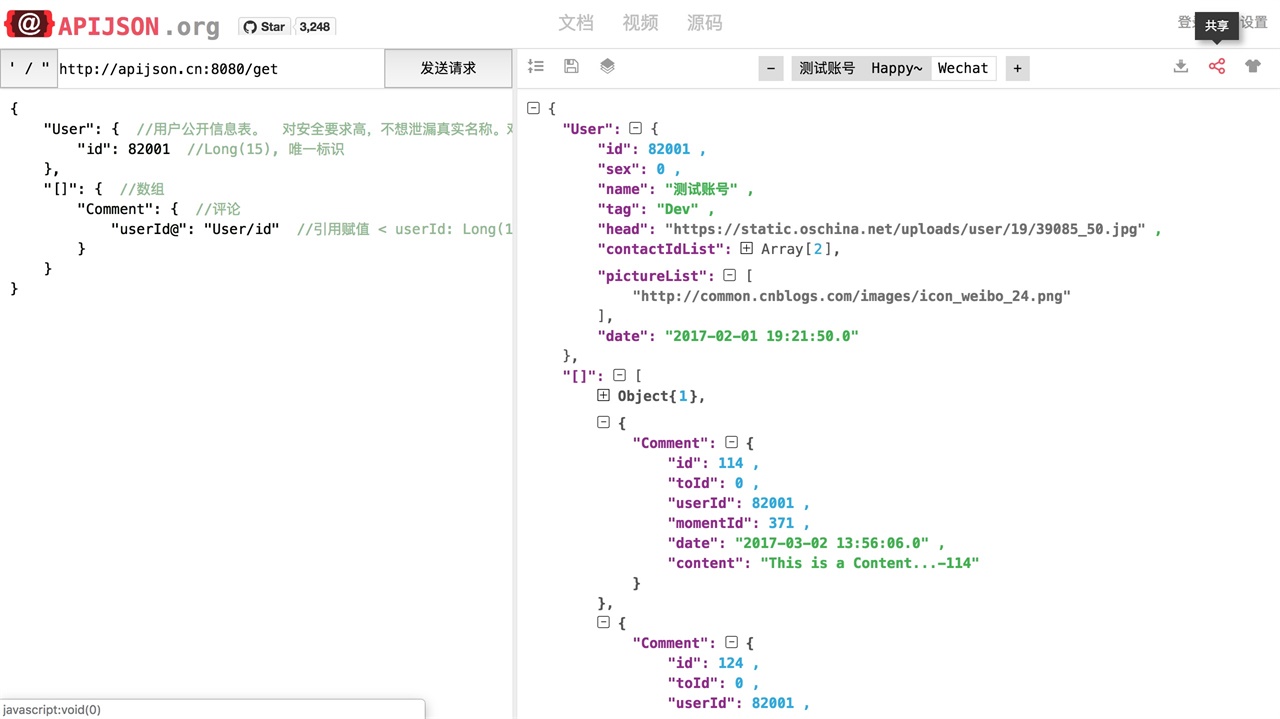
多表关联查询、结构自由组合、多个测试账号、一键共享测试用例

自动生成封装请求 JSON 的 Android 与 iOS 代码、一键下载自动生成的 JavaBean
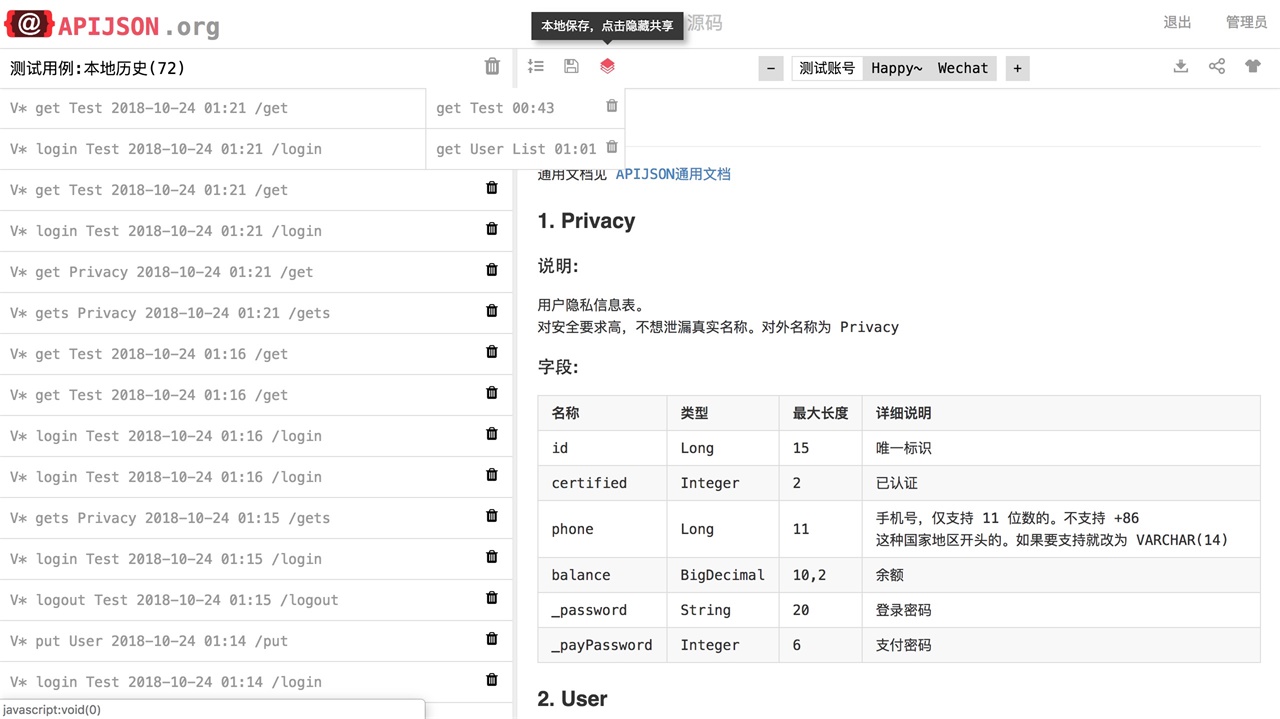
自动保存请求记录、自动生成接口文档
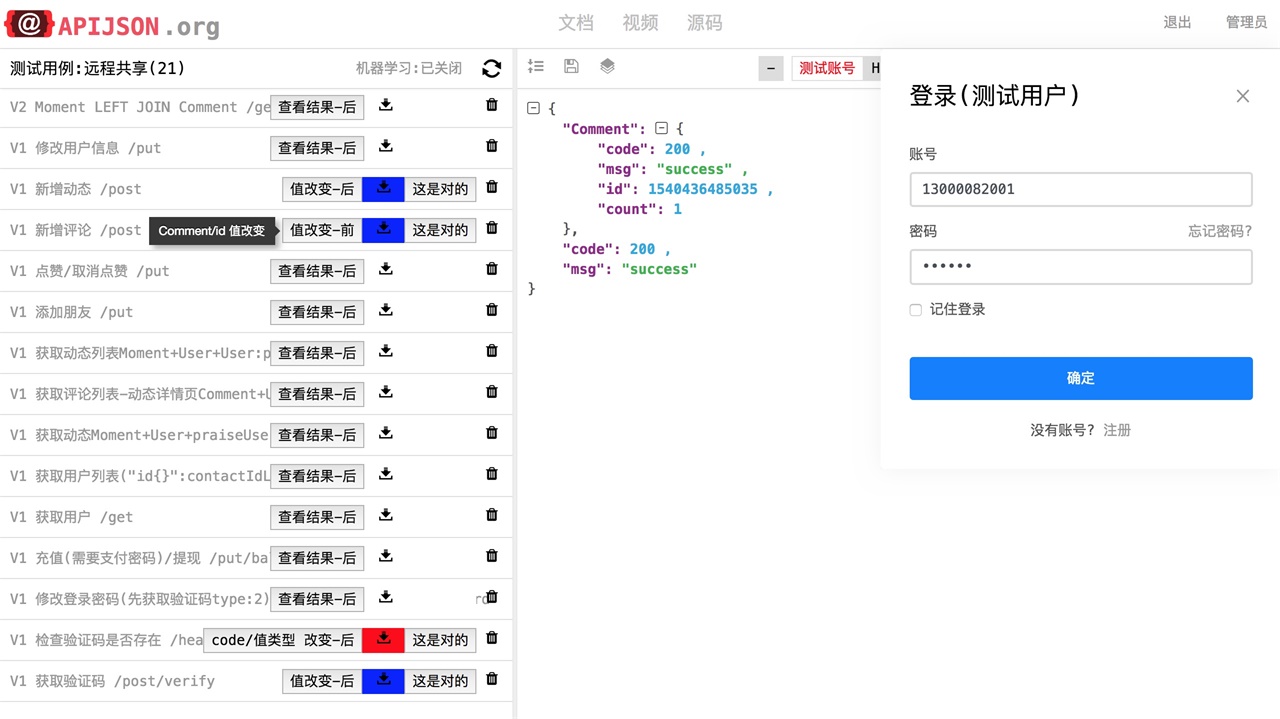
一键自动接口回归测试,不需要写任何代码(注解、注释等全都不要)
目前 APIJSON 的生态已初具雏形:
* APIJSON 接口工具: https://github.com/TommyLemon/APIJSONAuto
* APIJSON -Java 版: https://github.com/TommyLemon/APIJSON
* APIJSON - C# 版: https://github.com/liaozb/APIJSON.NET
* APIJSON - PHP 版: https://github.com/orchie/apijson
* APIJSON -Node 版: https://github.com/TEsTsLA/apijson
创作不易,GitHub 右上角点 ⭐Star 支持下吧,谢谢 ^_^
 |
1
wzw 2018 年 11 月 14 日 via iPhone
没有 python 没有 go
|
 |
2
TommyLemon OP @wzw Python 版有开发者声称:
"回说的 python 初步完成了 zeromake/restful_model 刚刚把单元测试写好。 json 的表现层完全自定义,都是为了对应 sql。" 有段时间没更新了,不清楚进度怎样。 希望也有热心的开发者实现 APIJSON 的 Go 语言版本哈。 如何实现其它语言的 APIJSON ? https://github.com/TommyLemon/APIJSON/issues/38 |
 |
3
richangfan 2018 年 11 月 14 日
后端要完
|
|
4
TommyLemon OP @richangfan
不会的,非常复杂的查询( 1 屏以上 SQL )不建议使用 APIJSON 的自动化 API,手写更容易实现以及性能调优。 还有后端也不只是 CRUD 啊,服务监控、微服务、数据分析、个性化推荐 ... |
 |
5
ooonme 2018 年 11 月 14 日 这么多 star,可想而知国内互联网小作坊的项目是有多垃圾
|
|
6
TommyLemon OP @ooonme Talk is cheap, show me your code.
|
|
7
TommyLemon OP @ooonme 这么贬低别人,得先有公开的拿得出手的成就才行
|
 |
8
biantaoGG 2018 年 11 月 14 日
看到 java 直接运行 jar 包就可以了 我好方.......我是个安卓开发...当年用 spring 写后端的时候还要打成 war 跑在 tomcat 上...现在已经变得那么简单了么...
|
 |
9
zpf124 2018 年 11 月 14 日
|

 |
10
sagaxu 2018 年 11 月 14 日 via Android
构造查询参数的过程,跟写代码没什么不同,还增加了学习成本。如果业务简单到可以直接丢给前端用,倒是解放了后端,把部分业务代码转移到前端去了。
|
|
11
TommyLemon OP @biantaoGG
因为 SpringBoot 让 Java 开发变得很简单,APIJSON Demo 基于 SpringBoot 提供了自动化 API, 又极大地简化了大部分 CRUD 接口的开发,其实是这部分 API 压根就不用后端开发了哈哈。 |
|
12
TommyLemon OP @zpf124
Star 在比较大的程度上反映 Repo 在开源社区的受欢迎程度,在同种类库(例如 ORM )间对比很有意义。 Mybatis 目前应该是 Java ORM 库中 Star 最高的, 然而你敢说 Mybatis(2010 年开源) 使用率一定比 Hibernate(2007 年开源) 高? 但 Star 反映的是 Mybatis 在开源社区的确更受欢迎。 至于 Facebook 出的 GraphQL,你拿出来对比只能说明你没有对 它 和 APIJSON 有足够的了解。 从 Star 数量来看,比 APIJSON 多,确实也在开源社区更受欢迎,在 CRUD 上 APIJSON 完爆 GraphQL: 完爆 Facebook/GraphQL,APIJSON 全方位对比解析(一)-基础功能 juejin.im/post/5ae80edd51882567277433cf 完爆 Facebook/GraphQL,APIJSON 全方位对比解析(二)-权限控制 juejin.im/post/5b13cda1f265da6e4a6bcfee 完爆 Facebook/GraphQL,APIJSON 全方位对比解析(三)-表关联查询 juejin.im/entry/5b4ff88f6fb9a04f914a8df5 目前我已知的所有 ORM 开源库,只有 APIJSON 能做到 关系型数据库 自动化 CRUD, 如果有别的,欢迎告诉我,我会认真了解和对比下。 以下项目主页包括 源码、部署与协议文档、视频教程、接口工具等。 创作不易,GitHub 右上角点 ⭐Star 支持下吧,谢谢 ^_^ github。com/TommyLemon/APIJSON |
|
13
TommyLemon OP @sagaxu
不写代码居然和写代码没什么不同,我也是服。 你写了代码,需求变更,是不是得改接口或新增接口? 用 APIJSON 就不需要后端改接口,前端改下 JSON 参数, 就会重新自动生成新的 SQL 语句,满足新的需求。 |
|
14
sagaxu 2018 年 11 月 14 日 via Android
@TommyLemon 举个例子,需求从根据身高筛选,改为根据体重筛选,是不是有个地方要把身高改成体重?如果连表的条件改了,能不用改代码吗?
再举个例子,业务状态有变更时发个短信通知,好像还是得写代码。 真正用在 db 层面的 crud 上的开发时间比例很低,大部分还是在处理业务逻辑,而不是简单的数据存取。 我把手上项目挨个遍历了一下,发现没有一个能因此减少工作量,才得到区别不大的结论。 |
|
15
TommyLemon OP @sagaxu 至于学习成本,哪个库没有学习成本?
只要 带来的好处 明显超过 带来的坏处 + 学习成本 就值得尝试。 为什么要用 APIJSON ?前后端 10 大痛点解析 github。com/TommyLemon/APIJSON/wiki |
|
16
TommyLemon OP @sagaxu
能啊,这就是 APIJSON 相对以前做法的很大优势。 搜索 name 中包含字母 a { "User": { "name~": "a" } } 变为 搜索 sex 为 1 { "User": { "sex": 1 } } 以上都是单个对象,可以套一个 []:{} 变成列表 { "[]": { "User": { "sex": 1 } } } 发短信通知不属于 CRUD 了,超过了 APIJSON 的应用范围。 但你也可以写一个远程函数,用于发送短信, 然后不需要的就不调用,需要的就调用, 后面如果有需求 从不发 到变为 发送 就不需要后端写代码了。 最后这个也只是你个人的经验,也许是 ERP 项目,也许是金融项目,也许是其它大项目, 但大部分互联网中小型项目还真没有多少复杂的业务逻辑,APIJSON 的自动化 API 就很适用, 而且也能通过远程函数来扩展业务逻辑的实现。 既然你手上的项目是这样,那就不用呗。 不过从第一点来看,你对 APIJSON 没有足够的了解,或许可以再看看。 在线测试 apijson。org |
 |
17
AllOfMe 2018 年 11 月 14 日 via Android
@ooonme 我倒觉得楼主的这个项目花了不少心思,说小作坊有点过了吧。你是没见过搭建几个 webpack 配置的脚手架就言必称架构的项目了
|
|
18
AllOfMe 2018 年 11 月 14 日 via Android
楼主原本是后端出身吗?
|
|
19
AllOfMe 2018 年 11 月 14 日 via Android
我觉得楼主可以更进一步,基于 APIJSON 搭建一个 Crud 构建系统,类似于飞冰那样,可以让你的项目被更多人吸引
|
|
20
TommyLemon OP @AllOfMe
感谢。我是 Android 开发出身转 Java 后端开发,最早开源的项目是 Android 快速开发框架 ZBLibrary https://github.com/TommyLemon/Android-ZBLibrary 这个建议非常好,目前 APIJSON 的自动化权限控制需要静态编码(最少 3 行代码配置每种角色对一张表的 CRUD 权限), 等把这个做成动态获取的(例如存数据库,项目启动时加载并缓存,然后改了配置后可以调接口刷新缓存), 权限也就能动态配置,新增表后也不用写代码再重启服务了,就能实现几乎完全可以在线配置的 SaaS 后端。 |
|
21
ooonme 2018 年 11 月 15 日 @AllOfMe @TommyLemon 这种东西在稍微正式一点的项目中没有任何用处,另外我说的是大部分互联网小作坊项目,没有说 apijson,然后不要跟 hibernate 比较,代码质量比你高出不知多少,hibernate 只是一个库。一般情况下,另外就抽象能力来说,业务开发 < 框架开发 < 库开发。而一个好的库想要满足大部分场景就要知道什么功能该丢掉,你这个 apijson 只是一堆胶水代码而已,用 @AllOfMe 的说法就是一个脚手架,跟 hibernate 这种级别的项目比还差太远
|
 |
22
sunzhenyucn 2018 年 11 月 15 日
@ooonme
Star 真的在目前的 Github 的上代表不了什么,Hibernate 近 1w 多的 commits,Github 上 343 位 contributors,建议 owner 想营销自己的 project 还是换一个噱头吧(这样的标题真的容易被喷 另外 APIJSON 这个项目英文版文档里参杂着中文是什么鬼? |
|
23
sunzhenyucn 2018 年 11 月 15 日
@ooonme emmm... 貌似回复错人了 建议层主别介意
|
 |
24
nyaapass 2018 年 11 月 15 日 via iPhone 一直好奇 lz 是不是写了个爬虫,各大网站里只要一出现“接口、API、GraphQL、前后端撕逼”之类的帖子就会被召唤出来
|
|
25
TommyLemon OP @ooonme
请问你说的 稍微正式一点的项目 能不能具体描述下它的规模(项目类型、表数量、记录数、开发人员配置等)? 同样是 Java 的 ORM 库为啥不能比? Hibernate 代码质量比 APIJSON 高,这点我是承认的,但 APIJSON 的代码质量我自认为也是超过平均水平的, 不服的话,用阿里的 P3C 规范对比下? github。com/alibaba/p3c “一个好的库想要满足大部分场景就要知道什么功能该丢掉” 我也认同, 所以 APIJSONLibrary 是围绕 ORM 这个核心做的,加了一个必要的自动化权限控制(对于 APIJSON 这种), 其它说的功能要么是 Demo 提供的,要么是生态内的其它开源库或工具提供的(自动生成文档与代码、自动回归测试等), 并不是贪大求全、无所不包。 “你这个 apijson 只是一堆胶水代码而已”,真不知道你是对 APIJSON 偏见有多大,才草率得出这种结论, APIJSONLibrary 和 Hibernate 一样都是把 对象 转为 SQL 的 ORM 库, APIJSONLibrary 对象是用 JSON,Hibernate 对象是用自定义的 POJO, 本质都是一样的,只不过 JSON 可以从前端动态传过来,POJO 只能后端提前写死, 居然就被你说成了“胶水代码”,这么说 Hibernate 不也是“胶水代码”? “跟 hibernate 这种级别的项目比还差太远” 得具体看哪些方面吧, 从代码量上来看: APIJSONLibrary 只有 49 个 java 文件 hibernate-core 有 3343 个 java 文件 确实“差太远”,但这不正是 APIJSON 的巨大优势? 代码越少 bug 越少。更何况支持的数据库功能也没有大的差距。 从使用上来讲: 用 APIJSON 可以通过自动化 API,不用后端写代码; 用 Hibernate 得每个接口都要 封装 POJO,及调用它的方法或写注解 等一大堆代码。 APIJSON 支自动化持关联查询(参数里加一个引用赋值键值对)和自动化 JOIN(参数里加一个 join 键值对),后端自动化解析不用写代码; Hibernate 得写注解来实现关联,或分次调用代码,写一堆代码,不直观也不好开发和维护。 所以这方面反而是 Hibernate 比 APIJSON “差太远”。 APIJSONAuto,自动化接口管理平台,自动生成文档与注释、自动生成代码、自动化回归测试(机器学习)、自动静态检查等。 http://apijson。org |
|
26
TommyLemon OP @sunzhenyucn
再次强调,Star 在比较大的程度上反映 Repo 在开源社区的受欢迎程度,在同种类库(例如 ORM )间对比很有意义。 “ Hibernate 近 1w 多的 commits,Github 上 343 位 contributors ”, 然而更受欢迎的 Mybatis 只有 2252 个 commits,112 个 contributors,你又怎么看? github。com/mybatis/mybatis-3 APIJSON 也有 1307 个 commits,6 个 contributors。 github。com/TommyLemon/APIJSON 那部分是来不及翻译的,APIJSON 的绝大部分用户都是中国人,英文文档没有太过投入精力去维护, 还有你能看懂中文文档干嘛非要盯着这个小问题找茬? 当然毕竟也是问题,后续抽时间解决吧。 |
|
27
TommyLemon OP @nyaapass 不会写,暂时也没兴趣去爬数据
|
 |
28
aheadlead 2018 年 11 月 15 日
楼主的东西好坏不知道,不是相关开发者。
倒是楼主的宣传方式要改进。 现在我在各帖子里看到“创作不易”这四个字就感觉烦人。 |
|
29
TommyLemon OP @aheadlead 这句话是反复修改过 10 次以上的,多次实践证明效果很好,当然我也会不断思考和改进,如果你有更好的建议欢迎提出,谢谢
|
 |
30
kran 2018 年 11 月 15 日 via iPhone
了解了您的作品和 gql 后,想知道为什么不基于 SQL 解析器做些事情?
|
31
6IbA2bj5ip3tK49j 2018 年 11 月 15 日
@aheadlead
LZ 几十页回复,基本都是这一套话术。 都开始用『。』来代替『.』了,以躲避 v 站的反 spam 策略。 @nyaapass 但是我们可以很轻易地 follow LZ https://www.google.com.hk/search?q=Github+Star+%22%E5%88%9B%E4%BD%9C%E4%B8%8D%E6%98%93%22 |
 |
32
vinsa 2018 年 11 月 15 日 via iPhone
虽然看起来很不错,但把 Hibernate 拉进来强行比 star,会丢分。不一个维度的东西。
|
 |
33
chinvo 2018 年 11 月 15 日 via iPhone
和 parse 的思路好像差不多
|
|
34
TommyLemon OP @xgfan 链接主要是用来说明自己的论点,我又不像某些网友随口说出没有依据的话。
能直接点最好,不能的话,改下格式,起码大家还能复制粘贴到浏览器上打开。 话说作为一个开源项目的作者,希望别人 Star 自己的 Repo 有什么奇怪的吗? 至于用什么文字,不同的人有自己的风格也很正常啊。 你搜下 Github Star "支持一下" 照样一大堆结果 https://www.google.com.hk/search?q=Github+Star+%E6%94%AF%E6%8C%81%E4%B8%80%E4%B8%8B |
|
35
TommyLemon OP |
|
36
TommyLemon OP @kran
你说的是前端传 SQL ? 解析 SQL 语法,再校验权限、结构、内容,最后再转回 SQL, 不说性能问题,真要这么好搞业内也应该有不错的开源方案了。 而且 SQL 不能直观地反映返回 JSON 的数据结构, APIJSON 就能做到看请求知结果,所求即所得。 APIJSON 的 提取字段、远程函数 功能也不是 SQL 方案能方便地实现的。 还有 自动加注释、自动生成封装请求 JSON 的代码,用 SQL 方案实现也很困难,甚至根本不可能准确地实现。 |
|
37
TommyLemon OP @vinsa
不知道你的维度指的是什么。APIJSON 和 Hibernate 都是 Java 的 ORM 库,拿来对比有什么奇怪的? 而且我发布 APIJSON 后,也有很多网友拿来和其它开源库( Hiberate,GraphQL, JPA 等)对比。 |
|
38
TommyLemon OP @TommyLemon 甚至有些和 APIJSON 根本就不是同类的项目,例如 Swagger。
|
|
39
TommyLemon OP @TommyLemon
这里只是一个地方,还有我发的一些博客下,我在 Gitee 开源的项目下,都有很多提到 Swagger 的。 github。com/TommyLemon/APIJSON/issues/27 |
 |
40
chocotan 2018 年 11 月 15 日
hibernate 实现了 jpa 规范,楼主你强行跟 hibernate 比会丢分+1
看了楼主的回复里一直在强调各方面都比 hibernate 牛逼 |
|
41
TommyLemon OP @chinvo
很不一样,Parse 是 SaaS 服务,类似的有 Firebase 以及国内的 LeanCloud 等, 它们主要是把业务放到了前端,后端只手写或者自动生成一些细粒度的 RESTful 接口, 很多需求往往要前端调用多个接口再自己组装并处理数据, 有的还提供自己的类似 SQL 的查询语言,例如 LeanCloud 提供的 CQL,功能限制大,官方文档说了: 与 SQL 的主要差异 不支持在 select 中使用 as 关键字为列增加别名。 update 和 delete 不提供批量更新和删除,只能根据 objectId ( where objectId=xxx )和其他条件来更新或者删除某个文档。 不支持 join,关联查询提供 include、relatedTo 等语法来替代(关系查询)。 仅支持部分 SQL 函数(内置函数)。 不支持 group by、having、max、min、sum、distinct 等分组聚合查询语法。 以上都是 CQL 不支持的,但 APIJSON 全都支持。 另外 SaaS 应用场景基本只适合创业项目, 提供的功能都是受限于 SaaS 服务商( Parse 开源了,定制性要好一些), 有了一定规模就非常有必要把后端推到重来了。 而且又因为绑定了服务商的服务,迁移困难。 APIJSON 完全开放源码,容易定制,还能很好地控制权限。 APIJSON 则是 JSON 转 SQL 的协议,基于 JSON 扩展而来, 开源项目中提供了 Java 的 ORM 实现, 还有其它作者提供了 Node.js, C#, PHP 的实现。 APIJSON 为 简单的增删改查、复杂的查询、简单的事务操作 提供了完全自动化的 API。 能大幅降低开发和沟通成本,简化开发流程,缩短开发周期。 适合中小型前后端分离的项目,尤其是互联网创业项目和企业自用项目。 通过自动化 API,前端可以定制任何数据、任何结构! 大部分 HTTP 请求后端再也不用写接口了,更不用写文档了! 前端再也不用和后端沟通接口或文档问题了!再也不会被文档各种错误坑了! 后端再也不用为了兼容旧接口写新版接口和文档了!再也不会被前端随时随地没完没了地烦了! |
|
42
TommyLemon OP @chocotan 你确定是各方面?再仔细看看 25 楼我的回复,我都说了
"Hibernate 代码质量比 APIJSON 高,这点我是承认的,但 APIJSON 的代码质量我自认为也是超过平均水平的, 不服的话,用阿里的 P3C 规范对比下?" 我在另一个社区还提到 "Hibernate 使用率是远高于 APIJSON 的,毕竟从 07 年开源到现在都快 12 年了,APIJSON 才 2 年多一点。" oschina。net/news/101787/apijson-3-1-0-released#comments 有句话说得很对,"人们总是只看到他们想看到的东西" |
|
43
sagaxu 2018 年 11 月 15 日 @TommyLemon 搜索 name 中包含字母 a
{ "User": { "name~": "a" } } 变为 搜索 sex 为 1 { "User": { "sex": 1 } } ============================================== 难道这里改的不是代码? 10 大痛点我看了,感觉也没那么痛。 1. 带宽,内部系统或者管理后台大多数不需要考虑带宽。需要省带宽时,后端也可以只返回部分字段,甚至换二进制协议。 2. 命名混乱,不同部门或者第三方 API 的命名风格,编码规范解决不了,lint 也解决不了,APIJSON 也解决不了。 3. 数据类型,那是动态类型语言才有的问题,Java 或者 Go 定义好类型,还能变来变去?{}变[]是 php 独有的。 4. 混乱的状态码,跟第 2 点一样,只有很小的项目,不跟别人对接,只用 APIJSON 返回数据才能解决,但是可能吗? 5. 文档跟代码不同步,的确,这个问题比较普遍,也有很多根据代码生成文档的工具,但是往往只能做到字段说明或者参数说明这种程度,不能描述业务逻辑,也没有流程图或者 UML 图。 6. 应用界面和接口强耦合,只要数据依赖不变,UI 随便怎么改都不用后端一起改。接口定义是前后端一起商议的,后端一言堂的情况很多吗?强迫前端用 APIJSON 这种风格的 API 不算拍脑袋? 后面就不多说了,我个人感觉都不是痛点。 如果这 10 大痛点成立,现在应该很多公司在用了,还会写到招聘广告里。 =============================================== 请原谅我的抬杠,毕竟你的标题立的太高了 1. 不用写代码 2. 超 Hibernate 假如有 30%符合事实,恐怕早就铺天盖地的用起来了,根本用不着亲自宣传。 |
|
44
TommyLemon OP @sagaxu
我说的是不改后端代码,这是前端发的 JSON 参数。 =============================================== 1.用什么方式都能做,前提都是后端服务支持,只是传统方式要后端写代码支持,而 APIJSON 几乎没有成本,尤其是对于后端开发来说。 2.APIJSON 规范了: 页码(统一用 page 代替 pageNum, page_index, pnum 等), 每页数量(统一用 count 代替 pageSize, pcount 等 ), 搜索关键词(统一用 $, ~ 代替原来的 serach,searchKey, s, query, q 等), 连续范围 Between and(统一用 % 代替原来的 start=1&end=2, s=1&e=2, from=1&to=2 等) 包含值(统一用 <> 代替原来的 contains, con, cts, include, ild, inc 等) 增加或扩展 (统一用 + 代替原来的 add, plus, pls, append, appd, appe 等) 减少或去除 (统一用 - 代替原来的 remove, reduce, delete, rmv, red, del 等) 比较运算 (统一用 > 代替原来的 gt, <= 代替原来的 lte,id != 1 代替原来的 "id": { "ne": 1 } 等 各种不直观的写法) 逻辑运算 (统一用 & 代替原来的 and, |(可省略) 代替原来的 or, ! 代替原来的 not 等 各种不直观的写法) ... 传统方式开发的接口,不同的人对以上的命名很可能不一样,甚至同一个人写的不同接口都有可能不一样, 前端需要针对每个接口去查看文档或找后端确定,如果复制另一个相似接口的调用代码, 而不改名称(以为搜索 key 都是 seachKey ),接口调不通最后确定是这种问题,不是很恼火? APIJSON 对以上功能是强制这样写关键词 /符号的,不是的话,调自动化 APIJSON 是得不到正确结果的, 还可能返回具体的错误信息,例如 "GET 请求,字符 id= 不合法! key:value 中的 key 只能关键词 '@key' 或 'key[逻辑符][条件符]' 或 PUT 请求下的 'key+' / 'key-' !" "id{}:range 类型为 Integer ! range 只能是 用','分隔条件的字符串 或者 可取选项 JSONArray !" 当然其它一些命名,例如字段名等不能抽象的东西确实是没法强制了,强制的话会导致满足不了业务需求。 3.你说的很对,但现实就有大量 PHP 等动态类型语言写的后端啊,我是见过空对象变成 [] 返回导致线上 App 挂掉的。 难道就视而不见,或者强制使用 Java,Go 等静态类型语言?谁有这个权利,还能承担这个风险? 而且即便是静态类型语言,也有部分后端开发者不遵守约定改掉类型的,开发与测试环境常见, 可能是原来的类型不满足需求,或者有代码洁癖,看不惯以前不一致的代码自己重构了,前端必须改代码来兼容。 用 APIJSON 低成本、低风险地简单解决不好吗?而且还是从源头上避免问题的发生。 4.不能,但问题是 APIJSON 起码能保证 自动化 API 是返回标准且统一的 状态码的,传统方式啥都保证不了,全靠人。 人都是懒的,能用自动化 API 简单解决的,他就不大可能会自己写,又因为大部分 CRUD 是能用自动化 API 做, 所以大部分 CRUD API 就能保证状态码标准和统一了。 至于调第三方的接口,如果是前端直接调用,则前端特殊处理;如果是后端调用,一般都是手动写的接口, 不管是前端特殊处理,还是后端转成标准的状态码,都是可行的。 5.业务逻辑、流程图又不是后端给前端的,这是产品需求给的。后端只是提供 API,告诉前端怎么调用。 至于 UML 图,基本只是后端用来描述表关系,内部交接的时候用下,前端不需要关心。 6.非常多,非常普遍,可能你所在的项目组是严格按照前后端约定好文档再开发接口,很好地落实了这个流程, 但大部分中小型企业,还真的比较少有 合理的组织、规范的流程、良好的落实、高素质的开发团队。 能用 APIJSON 低成本解决的问题,就不要用 高成本的管理 来死磕了嘛。 APIJSON 的规范统一的,你换项目、换公司还是一样,Learn once, write anywhere. 用传统方式,别说换公司、换项目、就是换个后端开发甚至只是换个接口,就很可能不一样了,得一遍遍学习和适应。 你觉得不是问题的问题,可能是你没注意到,或者你经历过的项目确实不存在,但不代表一大堆中小型企业啊。 如果都和你是一样的看法,怎么会有这么多人支持我呢?或许你的项目环境比较优越,以至于 “何不食肉糜?” =============================================== 一个项目从开源到普及是需要时间的,APIJSON 效果确实好,但还有大量业务的开发人员、企业都不知道不了解, 而且 APIJSON 确实也没有火到像 SpringBoot,Mybatis,Redis 等一样成为业内普遍认可的方案,所以还需要推广, 不太可能现在就有公司写到招聘广告里,但的确已经有一些公司、团队、个人在用了,我们经常在群里回答问题。 |
|
45
TommyLemon OP @TommyLemon
并不觉得“标题立的太高了” 1. 不用写代码 -- 后端不用写代码 “因为 APIJSON 是自动化的,后端不用写代码,就能自动解析前端传的 JSON 参数...” 标题太长可能显示不下,一大堆新闻资讯(包括开源相关的)的标题不都要精简提炼下? 2. 超 Hibernate -- Star 超 Hibernate 事实依据都放上来了,一开始就是那张 Star 趋势图,还带链接, 再不信的话,APIJSON 项目链接都给了,Hibernate 你也能找到(我发的可能你又不信了),你都看下。 不是符合事实就 “早就铺天盖地的用起来了,根本用不着亲自宣传。”, 而是要有很大的影响力才能达到这个效果,一般开发者是 名企或名人 才行,可惜我都不是,只好自己宣传了。 |
|
46
sagaxu 2018 年 11 月 15 日 via Android @TommyLemon 做到后端不写代码了吗?回顾一下做过的项目,有几个能因此不用写后端代码?就算把范围缩小到 orm 这一层,也没做到完全不写代码。如果前端直接调用,只是把拼 DSL 的工作移交到了前端。如果后端自己去调用这个库,拼 json 真的比拼 sql/hql 简单吗?
你是如何得出受社区欢迎的结论的,star 数吗?我觉得这个指标毫无参考价值。我更关注贡献者数量,和衍生项目或者依赖这个项目的项目指标。 你可以自己搜搜看,结果数量很少,其中不少还是你亲自写的。网友的分享和实践几乎空白,热度跟 star 数量已经没有相关性了。 抛开流行程度或者使用人数不讲,我们只看项目本身。你我最大的分歧在于,你觉得纯 CRUD 接口在后端工作中占有很高比例,但我觉得这个比例很低,绝大多数接口都有业务逻辑夹杂在里面。真正简单的 crud,不仅不用写后端代码,前端代码也不用写,有 django 这类自带 admin 的,也有根据 db 自动生成全套代码的,甚至有外包公司点几下鼠标一个完整项目代码就自动生成了。 |
|
47
ooonme 2018 年 11 月 15 日
@TommyLemon 还在讨论,你是不是以为“知道什么功能该丢掉”只是说说而已?我怕你不是对 orm 有什么误解哦,你知道 orm 是哪 3 个单词吗?跟 http,json 有半毛钱关系?如果没有请不要跟 hibernate 比较。
|
|
48
kran 2018 年 11 月 15 日 via iPhone 其实在了解这些项目后,我是打算直接基于 SQL 来做一个实现。甚至写了个简化版 SQL 的解析器。但后来跟小伙伴讨论这样的使用场景发现不是很乐观。最大的问题就是这样把业务向前移,后端少了一层抽象,结果就是各个业务方各自为政,同样的业务实现千差万别,性能,底层数据结构变更,业务逻辑变更,都变得很出血的事情了。所以基础服务还是要老老实实实写好。当然了,如果是做做独立小项目,不妨一试。
无论形式如何,这样的东西和 leancloud 这样的平台提供的部分功能是相仿的,管他 json 也好,rest 也罢,都是一样的。 |
 |
49
finian 2018 年 11 月 15 日 你这个和 GraphQL 完全没有可比性啊,何来完爆一说。GraphQL 是数据交换协议,服务端没有限定使用什么数据源,不会和具体数据层耦合。你这个实际上就是 remote SQL 客户端,这种完全面向 SQL 的业务架构,大概只能用在简单小项目里吧。这种将服务端数据层直接暴露给前端的方式,耦合性太强,前端为啥需要知道你服务端用的是啥数据源?这种方式的可维护性是很差的。且不说假设有一天你们的业务数据层换成了 MongoDB 这种非关系型数据库,你这套就嗝屁了。就单单说,如果某天数据库 schema 改动升级了,前端也要一起改(能不能改还是个问题,像 Android、iOS 这种客户端,公开提供的 API 就不能再改了,除非不管旧客户端兼容性)。然后你就等着前端拿着刀来砍你们吧。
|
 |
50
zzzmode 2018 年 11 月 15 日 via Android
写代码总是会和需求相结合啊,是能少写代码但感觉通用性不强
|

 |
52
openthinks 2018 年 11 月 16 日
Oracle APEX 可以了解下,直接 UI->DB,两层搞定,简单快速。我是来插科打诨的,溜。。。
|
 |
53
wfd0807 2018 年 11 月 16 日
想起当年的的 PowerBuilder 了,确实方便快捷了很多
但是,这相当于给用户提供一个 db 查询的入口,而且是可编程的 这个风险要考虑 |
 |
54
Sharuru 2018 年 11 月 16 日 via Android
推广未免过分了点,前几天 Hibernate ORM 讨论贴里都是你在回复,推广也是,大段文字令人毫无兴趣。
|
 |
55
FrailLove 2018 年 11 月 16 日
感觉就是 DB->服务器端->前端 砍掉了 服务器端 减少了一层抽象 面向对象也不需要了
|
 |
56
Finest 2018 年 11 月 16 日
后台做 BI 展示可能还是有点用
|
 |
57
clino 2018 年 11 月 16 日 via Android
楼主项目组织有点乱,看起来比较山寨,如果规整些喷的人会少一点
我有兴趣参考来实现 python 版的试试,有规范的无关具体实现的协议定义文档吗? |
|
58
TommyLemon OP @clino
说的是最后生态内开源库的链接吧, 排版预览时还是正常的,发出来就没对齐了。 设计规范 https://github.com/TommyLemon/APIJSON/blob/master/Document.md#3 如何实现其它语言的 APIJSON ? https://github.com/TommyLemon/APIJSON/issues/38 |
|
59
TommyLemon OP 其它评论下周回吧
|
|
60
TommyLemon OP @ooonme 你对 APIJSON 都没了解清楚就不要瞎评论了。
APJSON 就是一种 JSON 格式的 ORM 协议,APIJSONLibrary 就是基于这个协议实现的一个 ORM 库, 只负责将 JSON 对象解析为 SQL,以及校验权限。 https://github.com/TommyLemon/APIJSON/tree/master/APIJSON-Java-Server/APIJSONLibrary 至于 HTTP 请求,那是基于 SpringBoot 开发的 APIJSONDemo 实现了 7 个自动化 API,调用 ORM 库来实现 CRUD。 https://github.com/TommyLemon/APIJSON/tree/master/APIJSON-Java-Server/APIJSONDemo JSON 对象难道不是对象?这么说 Sequelize,TypeORM 等一堆 JavaScript ORM 库都不能叫 ORM 库了。 |
|
61
TommyLemon OP @kran 正是因为直接传 SQL 问题多,我才造轮子做出了 APIJSON。
SQL 不能直观地反映返回 JSON 的数据结构, APIJSON 就能做到看请求知结果,所求即所得。 APIJSON 的 提取字段、远程函数 功能也不是 SQL 方案能方便地实现的。 还有 自动加注释、自动生成封装请求 JSON 的代码,用 SQL 方案实现也很困难,甚至根本不可能准确地实现。 至于业务逻辑,APIJSON 提供了 远程函数,后端写远程函数来实现,然后前端调用。 "isPraised()":"isContain(praiseUserIdList,userId)" 会调用 boolean isContain(JSONObject request, String array, String value) 函数,然后变为 "isPraised":true 这种(假设点赞用户 id 列表包含了 userId,即这个 User 点了赞) https://github.com/TommyLemon/APIJSON/blob/master/Document.md#3.2 |
|
62
TommyLemon OP @finian
这既是它的优势,也是它的问题所在。 不做具体实现,意味着可以对接各种服务,不限于 CRUD, 但带来的问题就是什么都要开发者自己手动实现 CRUD 等功能, 而且还得写一大堆 Schema,Type,resolver, 容易引发 N+1 查询问题,又得为每个需要优化的 Type 写几十行代码初始化及调用 DataLoader 来解决。 APIJSON 的确只限于做 CRUD,但 CRUD 在大部分互联网中小型项目中占了开发工作量的很大一部分, APIJSON 帮助后端开发自动化解决了,不用写代码;前端还能很方便地定制数据和结构,不用催接口、求文档。 “ remote SQL 客户端” 可以这么理解,“完全面向 SQL ” 就不对了,APIJSON 提供了远程函数,请看 61 楼评论。 代码量才是导致 “可维护性差” 的最大原因,100 行代码能很好解决的事情,用 1000 行实现就 “可维护性差”, APIJSON 的自动化 API 节省了大量的 CRUD 代码,反而是大幅提高了可维护性,甚至压根就不需要维护。 “业务数据层换成了 MongoDB 这种非关系型数据库”,是指先用关系型数据库,后换成非关系型数据库吧, 请问用什么系统不会“嗝屁”?别和我说仅仅通过改后端代码来兼容,这工作量和风险不是一般的项目能承受得起的。 能承受得起的,可能不用 APIJSON,用了 APIJSON 也可以直接改前端代码,后端还是很稳没啥要动的, 或者技术实力上来了直接重构,参考 GitHub,Twitter 等,都是一开始快速实现产品投放市场验证, 后面有钱、有人了想重构可以,想增强原有技术也行,例如 Facebook 魔改 PHP,Instagram 定制 Django。 如果一上来就是大项目,敏捷开发都未必适用了,这种我也不建议用 APIJSON。 |
|
63
TommyLemon OP @zzzmode “写代码总是会和需求相结合”,这个明显也是说业务逻辑,APIJSON 提供了远程函数来实现业务,
请看 61 楼评论。 |
|
64
TommyLemon OP @TommyLemon 这样既能节省大量的 CRUD 代码,又能在后端实现自己的业务逻辑,“通用性”就强了。
|
|
65
TommyLemon OP |
|
66
TommyLemon OP @openthinks 刚刚大概看了下,没看懂核心原理,暂不评论,等有时间再仔细研究下
|
|
67
TommyLemon OP @wfd0807 所以 APIJSON 提供了 自动化的权限控制,3 行代码就能配置各种角色对于一张表的增删改查权限。https://my.oschina.net/tommylemon/blog/889074
|
|
68
TommyLemon OP @FrailLove
大致正确,其实是把“服务端”原来要大量手写的 API 抽象成了 APIJSON 的自动化 API, 前端通过它的协议来间接使用数据库的 CRUD 功能,当然后端也可以提供远程函数实现特定的业务逻辑,看 61 楼 |
|
69
TommyLemon OP @hand515
群里已经有一些用户反馈用在 小程序、数据中心、可视化 等场景了, 还有个是在用 APIJSON 重构以前的项目(数据库用的是 PostgreSQL ), 我的建议是先不要动以前的 API, 新需求先用 APIJSON 实现,然后有时间再从简单的 API 开始用 APIJSON 替代, 原来的一些业务逻辑迁移到 远程函数,这样就能尽可能复用以前的代码。 |
|
70
TommyLemon OP @sagaxu
APIJSON 自动化 API 能解决的,就不用写 CRUD 代码。 “如果后端自己去调用这个库,拼 json 真的比拼 sql/hql 简单吗?” 确实更简单,首先不管用什么方式开发 API,提供给前端的文档里是不能把后端代码贴上去代替 JSON 参数的, 反正都是要写,APIJSONAuto 自动化接口管理工具能根据左边的 JSON 自动生成在右边的封装它的代码, 复制粘贴到项目中改下值就能用,比起拼 SQL/HQL 就是要简单。 http://apijson.org/ |
|
71
TommyLemon OP  |
|
72
TommyLemon OP @sagaxu 昨天回复数量达到上限了。
我说的一直都是“一定程度上”,当然你说的那几个指标确实也很重要。 如果 Star “毫无价值”的话,Hibernate 等一大堆开源库都未必会放到 GitHub 上了。 摘取知乎上两个评论: “开源作者一不加薪二不升值,开源的驱动力本来就是成就感。” “求 star 更多的获得认同和成就感 也会为作者带来些影响力和名气 如果这也批判的话 谁还做开源呀” 搜索结果的数量是少啊,APIJSON 这不才 2 年嘛,Hibernate 都快 12 年了才有现在的搜索量和热度啊。 从默默无闻到业内普及是有过程的,哪怕是大厂的开源项目也是如此,只不过会加速这个过程。 我想 Hibernate 刚开源时很可能也是有类似你这种评论,受到各种否定和质疑,但它还是发展起来了。 问题是那些就只能做 “简单的 CRUD ”,权限又怎么控制呢?还不是要写一堆代码。 而且它们是生成静态代码,会有很多不符合业务需求的代码要做二次开发,而且也基本只能在新需求用。 已经开发过的需求,如果再用新生成的代码覆盖肯定不行,往往因为业务逻辑也不能简单地替换已分散的代码, 找到能替换的部分在一段段替换,往往成本过高,还不如直接在原来的基础上改。 貌似真的只有 DSL 才能做到完全自动化了,后端不写代码就能自动化解析前端传的参数。 APIJSON 就是一种基于 JSON 扩展而来的 DSL,实现了前端动态传 JSON,后端动态解析为 SQL, 如果需求改了,前端把 JSON 参数改下,后端不用改接口或新增接口, 总之就是不用写代码,仍然自动解析为 SQL,满足新的需求。 APIJSON 能自动化实现的可不仅仅是“简单的 CRUD ”,还有复杂的查询,包括多表关联查询,自动化 join 等。 github.com/TommyLemon/APIJSON/blob/master/Document.md#3.2 在线解析 自动生成文档,清晰可读永远最新 自动生成请求代码,支持 Android 和 iOS 自动生成 JavaBean 文件,一键下载 自动管理与测试接口用例,一键共享 自动校验与格式化 JSON,支持高亮和收展 对于前端 不用再向后端催接口、求文档 数据和结构完全定制,要啥有啥 看请求知结果,所求即所得 可一次获取任何数据、任何结构 能去除重复数据,节省流量提高速度 对于后端 提供通用接口,大部分 API 不用再写 自动生成文档,不用再编写和维护 自动校验权限、自动管理版本、自动防 SQL 注入 开放 API 无需划分版本,始终保持兼容 支持增删改查、模糊搜索、正则匹配、远程函数等 |
|
73
TommyLemon OP |