
这是一个创建于 2715 天前的主题,其中的信息可能已经有所发展或是发生改变。
Techs = ['MIT', 'Caltech']
Ivys = ['Harvard', 'Yale', 'Brown']
Univs = [Techs, Ivys]
Univs1 = [['MIT', 'Caltech'], ['Harvard', 'Yale', 'Brown']]
print('Univs =', Univs)
print('Univs1 =', Univs1)
print('id(Univs) =', id(Univs))
print('id(Univs1) =', id(Univs1))
但实际运行效果如下
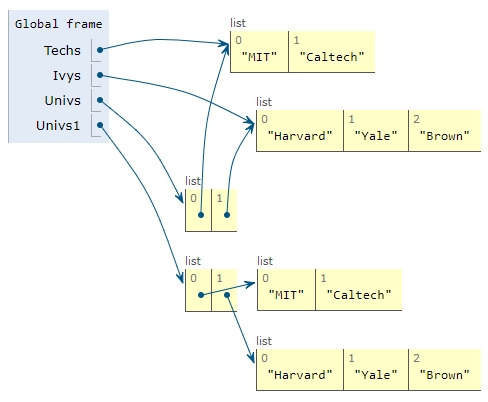
按照我自己的理解,如果 name bind 能够找到一个完全相同的 object,就不会重新创建一份 copy
但实际运行的结果和之前的总结似乎大相径庭
类似的问题还出现在 pass value by value/reference,网上也搜了一下这方面的 blog,但没找到说得特别清楚的
大佬们有推荐的 tutorial 链接吗 Python 语言何时创建新的 Object 有什么原则吗?
 |
1
whoami9894 2018 年 8 月 30 日 via Android
list 对象每次创建都会创建 id 值不同的新对象
不同的是字符串驻留和小整数驻留机制,[A-Za-z0-9_]的字符串,-5 ~ 256 的小整数新建对象时不会 copy |
 |
2
mimzy 2018 年 8 月 30 日 via Android
一楼正解
如果按你那么理解的话,Univs1 恰好创建了和 Univs 相同的内容,因此指向同一对象的话,那修改 Univs 也会造成 Univs1 的变动,这明显是不合理的。 |
|
3
mimzy 2018 年 8 月 30 日 via Android
|
 |
4
lxy42 2018 年 8 月 30 日
最近正在看《 Python 源码剖析》
#1 已经说到了几点,我补充一下: - 小整数缓存机制,Python 内部会预先初始化一个小整数对象缓存池,范围是[-5, 256],在创建该范围内的整数时直接使用缓存池中的整数对象。 ``` >>> a = 1 >>> id(a) 140706733650600 >>> b = 1 >>> id(b) 140706733650600 ``` - 字符串缓存机制,空字符串会被缓存在 nullstring,长度为 1 的字符串(即 0 - 255 的字符)会缓存在长度为 256 的 characters 数组中,避免重复创建。长度超过 1 的字符串会缓存在 intered 的字典中。 ``` >>> a = '^' >>> id(a) 4466954032 >>> b = '^' >>> id(b) 4466954032 >>> ``` - list 和 dict 也都有对应的缓存机制,当一个 list 或者 dict 销毁时,并不是真正的从内存中抹去,而是标记为“ free object ”,下次要创建 list 或者 dict 时,可以直接使用上次销毁的对象。 ``` >>> a = [1, 2, 3] >>> id(a) 4467181832 >>> del a >>> a Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'a' is not defined >>> b = [1, 2, 3, 4] >>> id(b) 4467181832 >>> ``` |
|
5
lxy42 2018 年 8 月 30 日
> 按照我自己的理解,如果 name bind 能够找到一个完全相同的 object,就不会重新创建一份 copy
这样做我觉得会有两个问题: 1. 在作用域中查找是否存在相同的 object 会带来性能问题。 2. Univs 和 Univs1 虽然看似值是相等的,但是它们是两个赋值过程,理应创建不同的 list。list 是可变类型,如果两者引用同一个 list,修改其中一个时会影响另外一个。 |