推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 3059 天前的主题,其中的信息可能已经有所发展或是发生改变。
proxy_list
很多网站对爬虫都会有 IP 访问频率的限制。如果你的爬虫只用一个 IP 来爬取,那就只能设置爬取间隔,来避免被网站屏蔽。但是这样爬虫的效率会大大下降,这个时候就需要使用代理 IP 来爬取数据。一个 IP 被屏蔽了,换一个 IP 继续爬取。此项目就是提供给你免费代理的。
需要免费代理的可以试试,如果对您有帮助,希望给个 Star ⭐,谢谢!😁😘🎁🎉
Github 项目地址 gavin66 / proxy_list
特性
-
爬取、验证、存储、Web API 多进程分工合作。
-
验证代理有效性时使用协程来减少网络 IO 的等待时间。
-
持久化(目前使用 Redis )爬取下来的代理。
-
提供 Web API,随时提取与删除代理。
使用
使用 Python3.6 开发的项目,没有对其他版本 Python 测试
克隆源码
git clone [email protected]:gavin66/proxy_list.git
安装依赖
pip install -r requirements.txt
运行脚本
python run.py
Web API
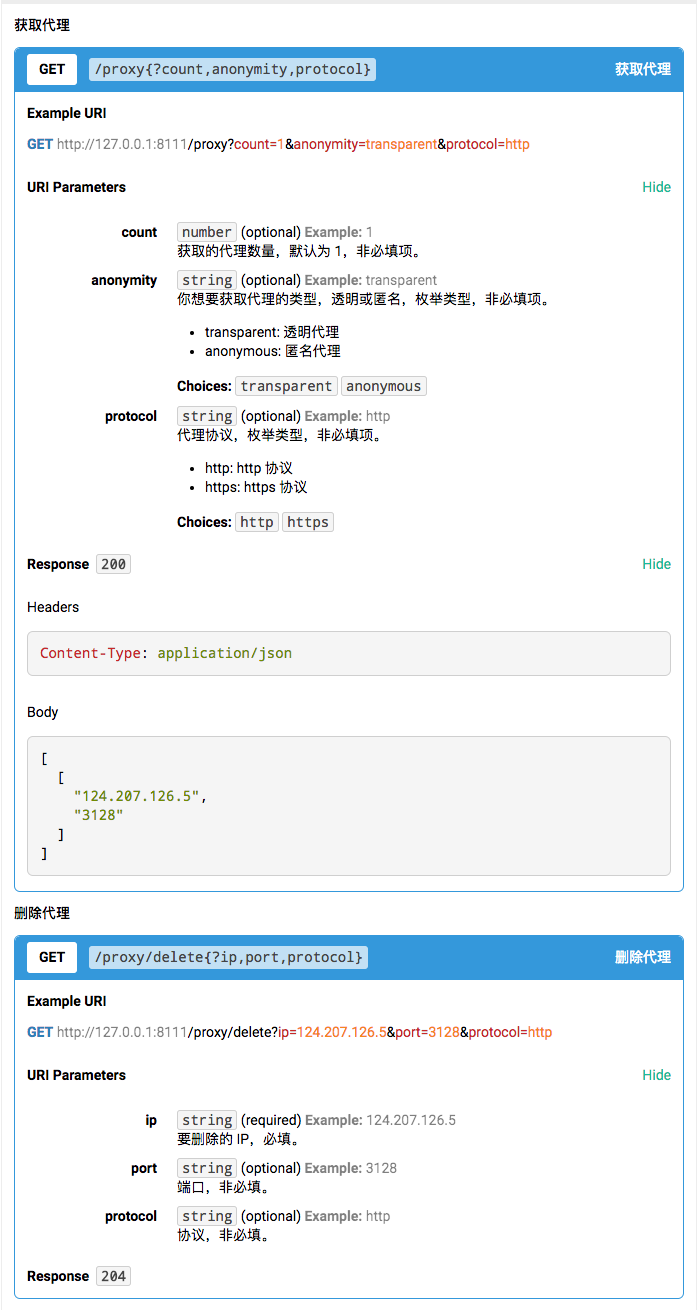
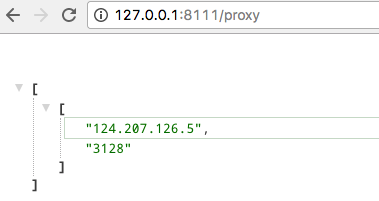
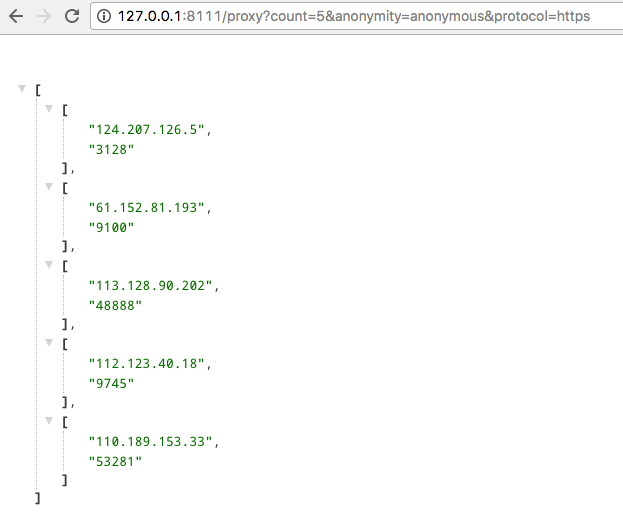
 |
1
Cooky 2017 年 9 月 4 日 via Android
手动点赞
|
 |
2
Le4fun 2017 年 9 月 4 日
好东西,mark
|
 |
3
est 2017 年 9 月 4 日 很好。我已经把这些 ip 全部加黑名单了。
|

 |
5
oneofwower 2017 年 9 月 4 日 via iPhone
@est 此帖终结
|
 |
6
lwghappy 2017 年 9 月 4 日
有测试过爬虫的效率怎么样?
|
 |
7
ksaa0096329 OP @lwghappy 你指的是哪一方面?是使用这些代理的效率还是爬取这些代理的效率?如果是爬取的话,每个代理都会访问一遍 `https://httpbin.org/` 确定代理可用。也就是使用已持久化下来的,都是保证可用的,使用 Web API 获取的时候都会获取连接速度最快的。
|
|
8
ksaa0096329 OP @Cooky 😄
|
|
9
ksaa0096329 OP @Le4fun 😄
|
|
10
ksaa0096329 OP @est 👍
|
 |
11
Itanium 2017 年 9 月 4 日
反爬界的福音
|

 |
13
gyh 2017 年 9 月 4 日
和 [IPProxyPool]( https://github.com/qiyeboy/IPProxyPool) 比有什么优势么
|
 |
14
lj0014 2017 年 9 月 4 日 via iPhone
顶,收藏备用
|
 |
15
fhefh 2017 年 9 月 4 日
顶 收藏备用
|
 |
16
Soar360 2017 年 9 月 4 日
我也做了一个,话说,这个成本真的不高啊……
https://ip.coderbusy.com/ |
 |
17
Orzzzz 2017 年 9 月 4 日
|
 |
18
suantong 2017 年 9 月 5 日 via Android
刚在 tending 看到了
|
 |
19
flyingfz 2017 年 9 月 5 日
话说 会不会 用的人多了之后, 被扒的网站 很容易就 把所有(或者大部分)的代理池分辨出来, 然后大家都没得玩了。
|
|
20
ksaa0096329 OP @gyh 我原来用的就是这个项目,后来看了源码感觉很多地方复杂了,我又有代码洁癖。所以有了这个项目,如果看源码,有很多我是借鉴 IPProxyPool 的。
|
|
21
ksaa0096329 OP @flyingfz 再找其他的免费代理网站
|
 |
22
jfry 2017 年 9 月 5 日
顶 收藏备用
|
 |
23
pengdu 2017 年 9 月 5 日
楼主帮忙科普下:
1,爬虫是怎么使用 IP 代理的? 2,如何贡献自己的 IP 作为爬虫代理? 谢谢! |
