

这是一个创建于 3279 天前的主题,其中的信息可能已经有所发展或是发生改变。
数人云上海&深圳两地“容器之 Mesos/K8S/Swarm 三国演义”的嘉宾精彩实录第三更来啦。唯品会是数人云 Meetup 的老朋友,去年曾做过 RPC 服务框架和 Mesos 容器化的分享。本次分享中,嘉宾王成昌分享了唯品会在 Kubernetes 上两年的 PaaS 实践,干货满满诚意奉上~
王成昌,唯品会 PaaS 平台高级开发工程师 主要工作内容包括:平台 DevOps 方案流程优化,持续部署,平台日志收集, Docker 以及 Kubernetes 研究。
大家好,我是唯品会 PaaS 团队的王成昌,与大家分享一下 PaaS 在 Kubernetes 的实践。基于 2014 年底或 2015 年初 PaaS 没有推广的现状,唯品会 PaaS 部门目前已经做了两年的时间。
PaaS 主要工作将分为三个部分进行介绍,首先, PaaS 定义的标准构建流程,持续集成和持续部署的架构以及已有组建上的功能定制;第二部分,基于 Kubernetes 实现的网络方案,以及根据网络方案做的扩展定制;第三部分, PaaS 如何做日志收集和监控方案,最后列一下唯品会目前为止所遇到的问题和总结。
唯品会现状

唯品会目前线上有一千多个域,每个域之间相互的依赖比较复杂,每次的部署发布困难。线下有多套的测试环境,每套测试环境都要去维护单独的应用升级和管理。公司层面也没有统一的持续集成和部署的流程,大家各自去维护一个 Jenkins 或者一个 Jenkins slave ,看工程师的个人追求是否能够写一个完整的从源代码、到打包、最后到部署的脚本。
唯品会线上全部用物理机在跑,之前 Openstack 方式没有在线上,只是在测试环境跑,物理机的使用效率还是比较低的。即使在 7 周年大促的高峰时段, 60~80%的物理机利用率也均低于 10%。
唯品会 PaaS 构建流程

基于前面提到的现状,唯品会的 PaaS 定义了一个构建流程,整个流程不是一蹴而就,这是目前为止的定义,首先从源代码的角度出发,即 Git ,所有的 7 个 Phase 全部包括在 Jenkins Pipeline 里,由于是基于 Kubernetes ,所以 Jenkins Pipeline 的执行是通过 Jenkins k8s Plugin 去调度后台的 k8s Cluster ,由 k8s 产生的 Pod 去运行 Pipeline 。整个 Pipeline 的几个阶段,除了传统的编译单元测试和打包之外,加入了烘焙镜像、部署以及集成公司的集成测试(即 VTP ),打包和镜像完成后会正常上传到公司统一的包管理系统 Cider 和平台维护的 Docker registry 。
部署完成后会触发集成测试,如果通过测试的话,会把这个包或者是镜像标记为可用的状态,一般先从测试环境标记,然后通过到 staging 环境。目前 PaaS 平台主要是维护测试环境和 staging 环境,线上还没有,但是已经定义了一个审批的流程,如果标记了这个包为可用的状态,需要一个审批来决定它是否可以上线。部署后通过 k8s client ,由另外一套 k8s 的集群来管理部署里面所有的节点。
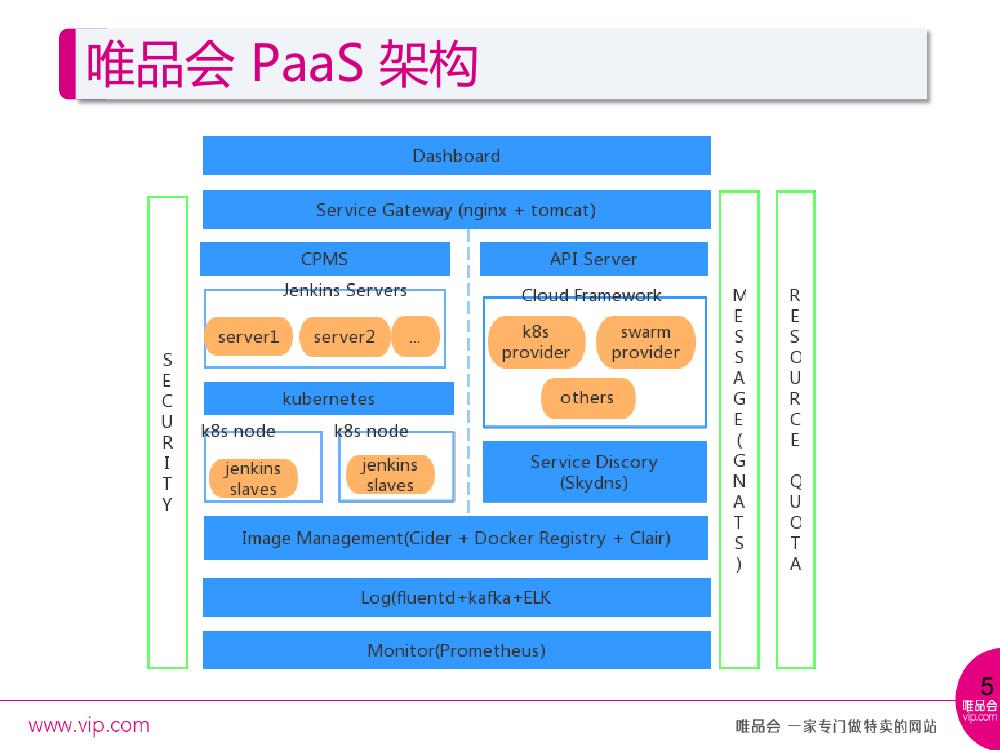
这是唯品会的 PaaS 架构,主要包含持续集成和持续部署。首先由一个统一 UI 的入口 Dashboard ,使用 Nginx 和 Tomcat 作为服务的网关。其背后有两套系统—— CPMS 和 API server , CPMS 主要管理持续集成的各个流程, API server 主要管理应用部署,在 CPMS 背后是使用多个 Jenkins server 统一连到一个 Kubernetes 集群上产生 Pod 作为 Jenkins slave 去运行,不同的构建有多种语言也有不同的模板,这里会提供各种方案让不同的 Jenkins Pipeline 运行在不同的 Kubernetes node 里面。
在部署实现一个 Cloud Framework ,可以接入各种 cloud provider ,目前使用的是 k8s provider ,背后的服务发现也是 k8s 推荐使用的 Skydns 。为了兼容公司基于包发布的这样一套模式,镜像管理这部分会把包管理系统 Cider 接入进入,平台的 Docker Registry ,以及应公司安全方面的要求,通过 Clair 对镜像的内容进行检查。
在日志收集方面,使用 fluentd+ELK 的组合,采用 Prometheus 做监控。在 PaaS 架构里,安全是通过接入公司的 CAS 做认证的动作,有一个 Oauth 组件做鉴权机制,通过 Gnats 做消息传输的系统。配额的问题在构建和部署中都会有所体现,包括用户对于 Pipeline 的个数控制或者 Pipeline 触发的个数,以及对应用上的物理配额或者逻辑资源配额等。

Docker Registry 改造,主要在 Middleware 做了一些工作,做了一个接入公司的 CAS 和 Oauth 做的验证和授权。也接入了当有新的镜像 Push 进来的时候,会自动触发应用的部署。 Docker Registry 本身对所有的 repository 不同的 tag 索引还是比较慢的,所以会针对 push 进来所有的镜像信息存入数据库做一个索引,方便查找镜像。用户行为记录主要针对 pull 和 push 的动作,把它记录下来。镜像安全通过接入 Clair 做扫描, push 镜像 layer 完成之后在 push 镜像的 manifest 时,会将镜像 layer 信息发送到 Clair 做镜像的安全扫描。

原来的 Jenkins Kubernetes Plugin ,默认把 Jenkins slave 调度在所有 Kubernetes node 上,我们做了一个 node selecter ,针对不同的 Pipeline 类型,需要跑在不同的节点上。调度上加入了 node selecter ,此外在每个 Pipeline 要去 run 的时候申请资源,加入了资源的 request limit ,防止单个的 Pipeline 在运行的时候占用过多的资源,导致其他的应用或者是构建任务受影响。在挂载方面,像传统的 maven 项目在下载过一个包之后,如果是同一个主机上会把.m2 文件会挂载在主机上,不同的 Jenkins Pool 在跑的时候,可以共享已经下载过的资源文件。
最后,实现了 Container slave pool 的策略。当要 run 一个 Pipeline 的时候,每次告诉 k8s 要起一个 Jenkins slave Pod ,当需要执行一个 job 的时候,等待时间比较长,这里会定一个池的策略,就是一个预先准备的过程,当有一个新的任务要 run 的时候,立刻就可以拿到一个可用的 containerslave 。
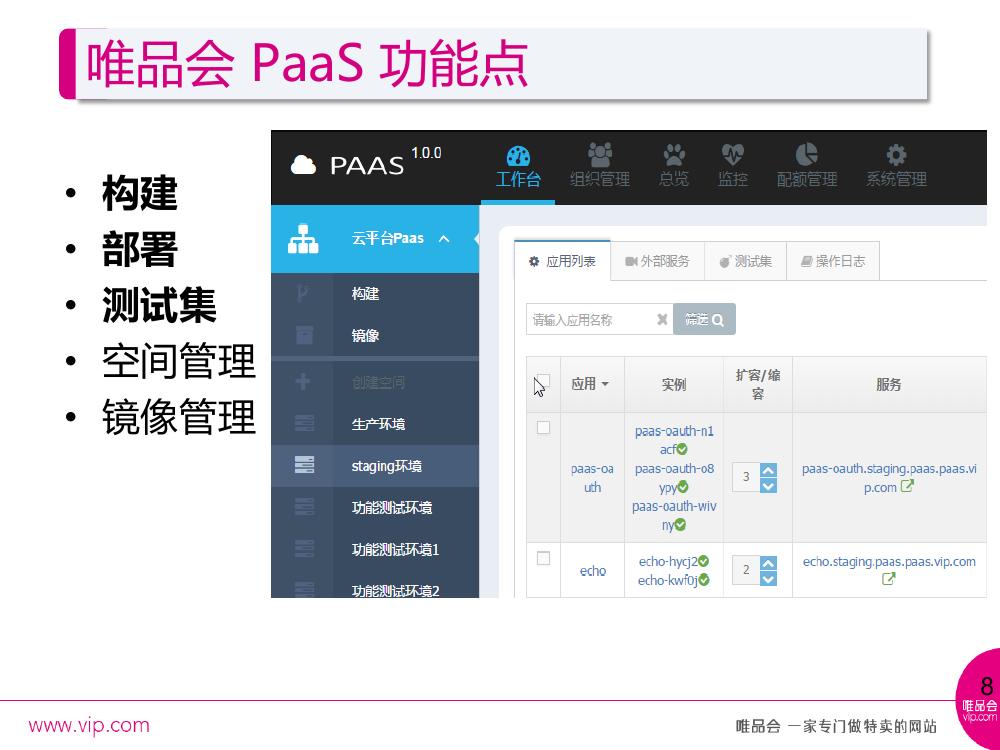
这是 PaaS 的功能点,包含三个主要的部分,构建,部署和测试集。构建是关于用户定义 Pipeline 以及对 Pipeline 触发的 record 的管理,以及 Pipeline 各个 phase 的管理。部署主要对应用配置的管理,这个应用包括服务的配置如何、资源的申请如何,以及应用实例的一些管理。测试集对接公司的集成测试环境,和平台的应用进行关联。
空间管理和镜像管理,空间主要提供不同的隔离空间,提供应用快速的复制,比如你有一个测试环境,我也有一个测试环境,为了大家环境之间相互不干扰可以提供应用的快速复制。镜像管理主要分三种,即平台提供的基础镜像,业务部门一些特殊的需求会基于基础镜像做一些定制,以及具体业务镜像。
PaaS 网络方案和定制
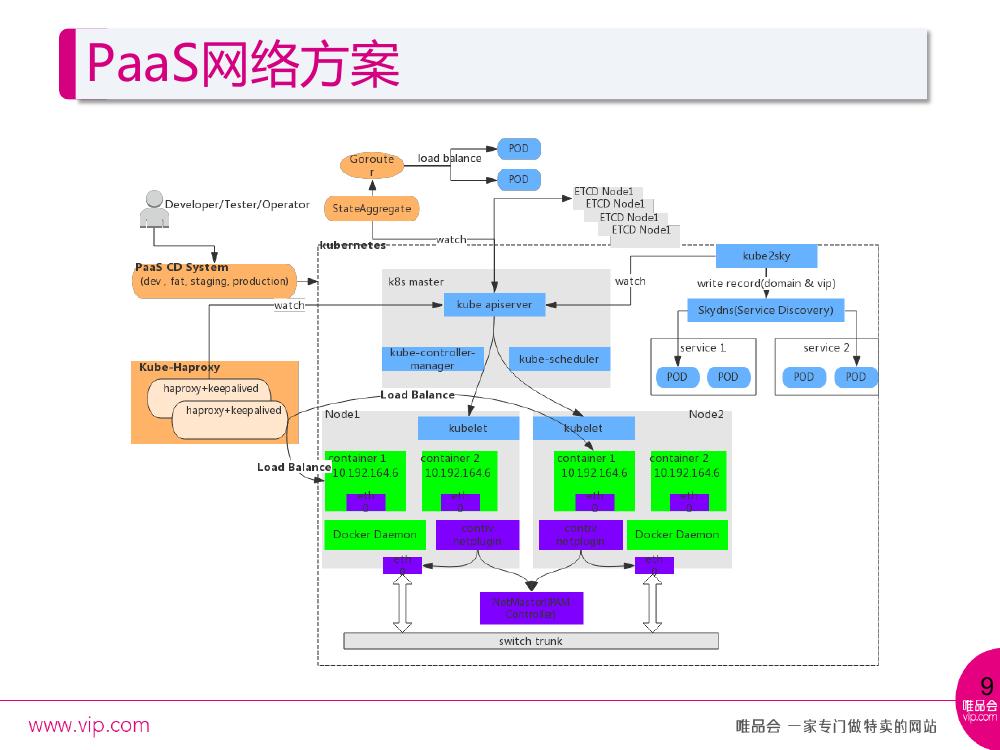
PaaS 采用的网络方案,网络方案最开始直接使用的 k8s 1.0 的版本加 flannel 的一套工作模式,后来由于业务需求,用户需求能够直接访问到实例 IP ,而 flannel 当时是封闭的子网。目前采用 Contiv 这套网络模式,由公司统一分配 Pod 的 IP 网段。这里做了一个 kube-HAProxy ,替换了节点上 kube-proxy 这个组件,用 kube-HAProxy 来做 Service IP 到 end point 的一个转发。
在 kube2sky ,完成域名和服务 IP 的注册。传统的模式下,域名是短域名, Service 的名字作为短域名,还有 Service 本身的 IP 会注册到 Skydns 上。这里做了一些定制,因为公司的应用比如两个业务域 A 和 B 都有本身的域名—— a.vip.com 和 b.vip.com , A 如果要访问 B ,不能让这个访问跑到线上或者其他环境去,于是通过 kube-sky 去解析规则,把 b.vip.com 加入到里面,再加一个 subdomain 作为扩展的 domain search ,最终找到平台内部部署的 B 域。
goroute 主要是平台内部的应用,每个应用都会提供一个平台的域名,这个域名主要是有一个组件叫做 state aggregator ,会 watch k8s apiserver 发出来的 Service 和 end point 的变化,最终通过 Service 的名字和 end point 的地址,把它写到 gorouter 的 route 注册表信息中,当我们访问平台域名时就可以找到真正的 end point 地址。这里也有定制,采用 HAproxy 和 KeepAlived 替换了 kube-proxy ,之前从 Service IP 到 end point IP 的转化,通过每个节点部署的 kube-proxy ,它会检测到 Service 和 end point 的变化,去写 IPtables 的规则,来找到最终 end point 的地址的 IP 。

现在统一使用的 HAproxy 加上 KeepAlived ,有一个 kube2HAproxy 组件,功能和 kube-proxy 前面一部分相似,都要 watch kube-apiserver 的 Service 和 end point 的 event 来动态的生成一个 HAproxy 最新的配置。 KeepAlived 主要为了高可用。有一个值得注意的细节, kube2HAproxy 所在机器的 IP ,要和 Service IP 的网段在同一个网段里,用户在访问真正的应用的时候直接使用 Service IP 是公共可见的,而不是随便定义的 Service IP 。

对外应用访问是由平台提供的域名,后缀均为*.PaaS.vip.com ,解析到之后会有公司的 DNS 统一转发到 gorouter 这台机器上,因为 gorouter 会监听到 Service 和 end point 的变化, route 表里面会存储每个域名对应的 end point 的地址,通过 round robin 的方式找到最终的 Pod 来完成 http 访问。

最后一个定制关于 Pod 的 IP 固定,为什么要做 PodIP 固定?因为之前的测试环境很多应用都是部署在 VM 甚至在物理机上, IP 都是固定的,有一些应用是需要白名单访问的,应用在这个部署机上,需要将 IP 提供给相应的调用方或者是公司的某个部门来告诉他加入白名单。 Docker 默认情况下,每次销毁和重建的过程中, IP 都会随机申请和释放,所以 IP 有可能变化。 IP 固定主要在 k8s apiserver 做,加了两个对象,即 Pod IP Allocator 和 IP recycler , Pod IP Allocator 是一个大的 Pod 的网段,可以认为它是 Pod 的 IP 池, IP recycler 主要记录一些临时回收的 IP ,或者叫临时暂存区, IP 不是一直存在,否则是一种 IP 浪费,有一个 TTL 时效性的。
当应用重新部署的时候,原本的 Pod 会被删掉,删掉的过程中会先放在 IP recycler 中,当一个新的 Pod 启动的时候,会通过 namespace+RC name 的规则去找是否有可用的 IP ,如果找到优先用这样的 IP 记录在 Pod 里,这个 Pod 对象最终会交由 kubelet 去启动, kubelet 启动的时候会读取这个 Pod IP ,然后告诉 Docker 启动的 IP 是什么。最终有新的 Pod 启动之后,它的 IP 是之前已经被销毁的 Pod IP ,达到的效果就是 Pod IP 固定。在 kubelet 因为修改了 Pod 对象的结构,增加了 Pod IP 记录使用 IP 的情况,根据 Pod 的 IP 告诉 Docker run 的时候执行刚刚的 IP 来启动。 kubelet 在删除 Pod 的时候会告诉 k8s 去 release 这个 IP 。
日志收集和监控
日志收集主要分三种类型:首先是平台自身的服务组件的收集,比如像 jenkins 、 Docker 或者 Kubernetes 相关组件的日志收集,另一个是所有部署在平台里面应用的收集,最后还有一些域,因为公司一些已有系统( dragonfly )也是做日志收集和监控的,有一些特定的规则对接公司。
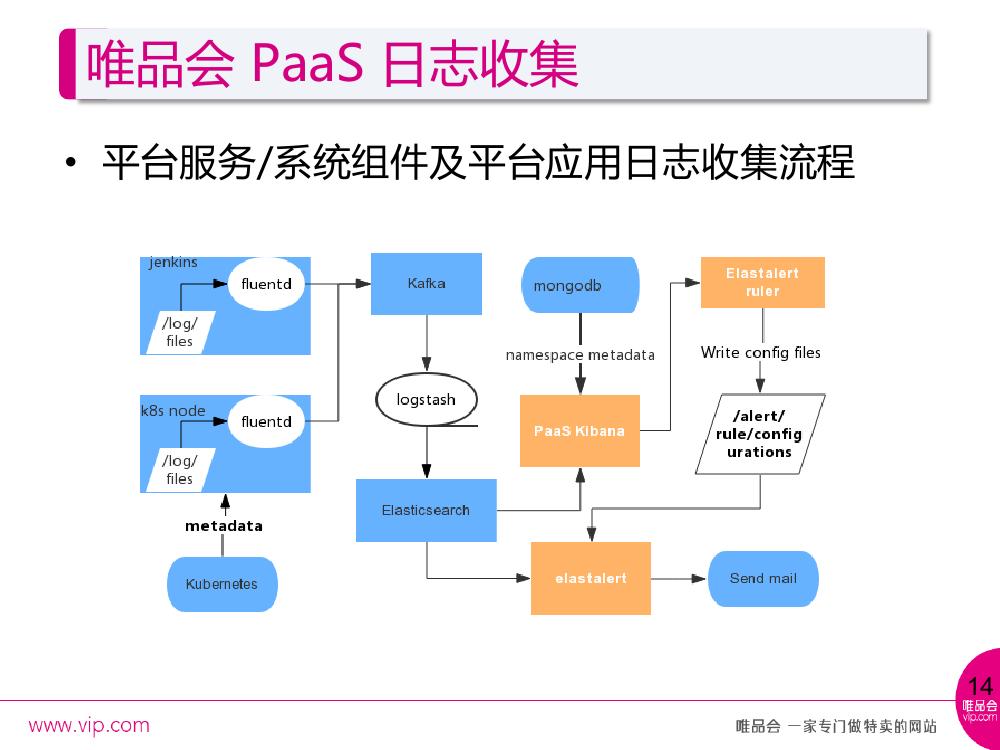
平台自身日志收集的规则,包含系统组件还有平台应用两种设计。系统组件比较简单,无外乎通过 systemd 或者是指定日志文件的路径做日志的收集,应用收集主要在 k8snode 上, k8s 会把每一个 Pod 日志 link 在一个特定的文件路径下,因为 Docker 会记录每一个容器的日志,可以从这个地方读取应用的日志,但是只拿到 namespace 和 Pod name 这样的结构,我们会通过 fluentd 里的 filter 反向去 k8s 拿 Pod 所对应的 meta data ,最终发送到 kafka ,通过 logstash 达到 elastic search 。
Kibana 的展现做了一些定制,因为平台的展现主要基于 namespace 和应用名称的概念查看日志的,定制能够展现特定的 namespace 下的特定应用的日志,同时把自定义的告警加在了这里,因为告警是通过 elastalert 来做的,在 Kibana 上做一个自定义告警的 UI 入口,由用户来指定想要监听什么样的日志内容的告警,去配置监听的间隔或者出现的次数,以及最终的邮件接收人。
有一个组件是当用户创建了自定义告警的规则时会发送到后面的 elastalert ruler , ruler 解析前台 UI 的信息,生成 elastalert 能够识别的 configure 文件,动态地读取 configure 的加入。 对接公司的业务系统比较简单,特定的收集规则都是特定的,比如具体的目录规则,一般来讲都是通过挂载容器的目录到主机目录上,在主机上统一部署一个 agent 去 run ,主要体现在 k8s node 上,所以仍然使用 Daemonset 的方式去跑 agent 。
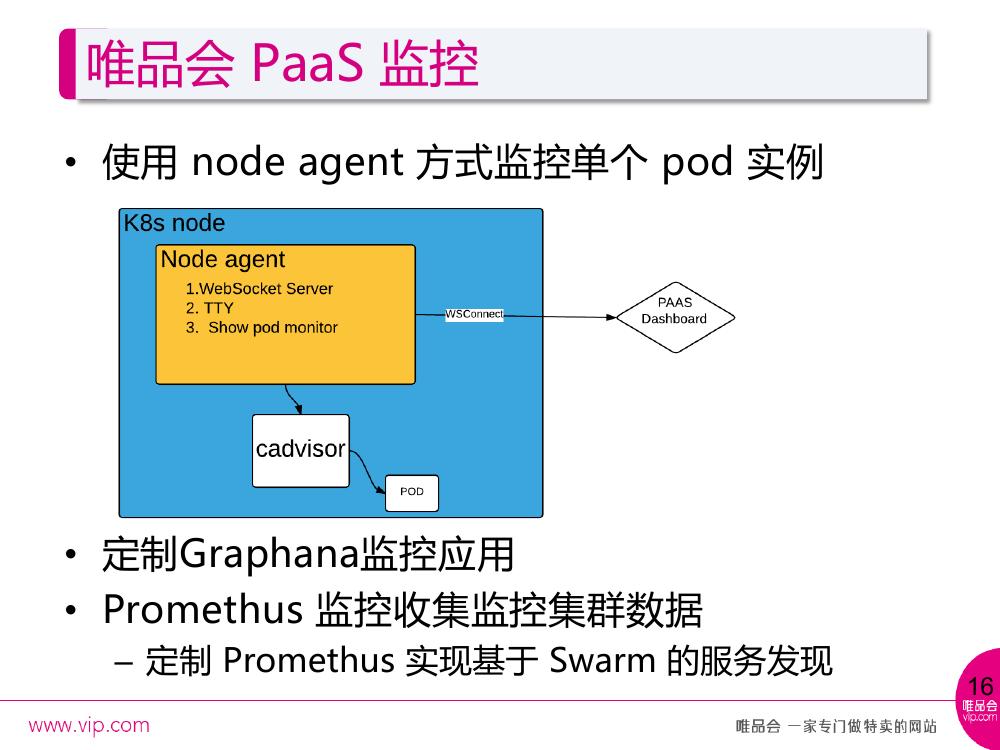
监控有两种,一种是对单个 Pod 的实例监控,在页面上是可以直接看这样的实例的,单个 Pod 是一个应用实例了,然后通过 node agent 去包装了 cAdviser ,前端去统一访问,获取对应的 CPU 和 Memory 使用信息。 cAdviser 对 Network 收集到的数据是不正确的,通过 node agent 读取 Linux file 获取 Network 的信息。 Websocket Server 是为了提供网页上直接对容器进行网页控制台的登录。
另一个是看整个的应用,因为应用是有多个实例的,通过 Graphana 去定制,去展现 namespace 的应用,有多个实例,就把多个实例的监控都展现出来。此处有一个 promethus plugin 的定制,之前有一些 Swarm 的节点加入,持续部署提到过它是一个多个 cloud framework 都可以接入的。唯品会接入了一些 Swarm 的信息,针对 Swarm 创建的容器的话,也要能够监控到它的容器监控信息的数据。在 Promethus plugin 通过 Docker info 获取不同的 Swarm node 的信息,在每个 Swarm node 上部署 cAdviser ,获取由 Swarm 创建的容器的监控信息。
问题总结
遇到的问题非常多,到现在为止将近两年的时间,有很多都是可以在 GitHub 找到的问题,以及通过升级可以解决的问题。最开始采用的是 Docker 1.6 以及 Kubernetes 1.0 ,中间经历两次的升级,现在主要使用 Docker 1.10 和 Kubernetes 1.2 。
Devicemapper loopback 性能问题
production 使用 direct-lvm 做 Devicemapper 存储。
Pod 实例处于 pending 状态无法删除
目前发现一些 Pod 一直处于 pending 的状态,使用 kubectl 或者 Kubernetes API 没有办法直接对 Pod 做任何操作,目前只能通过手动 Docker 的方式删除容器。
k8s 僵死容器太多,占用太多空间
k8s 僵死容器是以前碰到的问题,现在最新版的 Kubelet 是支持这样的参数,允许每一个节点上最大僵死容器个数,交由 Kubelet 自己做清理的工作。
Kubernetes1.1.4 上 ResourceQuota 更新比较慢
因为以前发现用户来告诉配额不足的时候,调整配额并不会立马的生效,升级以后就没有这种问题了。
k8s batch job 正常退出会不断重启
这个是应用的问题,不是传统理解的跑一次性任务, k8s batch job 要求一定要 exit 0 。也有一些 Job 的类型,目前是直接对应的背后 k8s 的 Pod 方式。
Skydns ping get wrong IP
这是最新遇到的问题,上下文的话,稍微有一点复杂,有两个应用部署在唯品会的平台上,每个应用都有自己的 legacy 域名,比如有一个域名叫 user.vip.com ,另一个叫 info.user.vip.com ,这时候 ping user.vip.com ,有可能会拿到 info.user.vip.com 的 IP ,由于 kube-sky 本身在写 Skydns record 时候有问题,所以会添加一个 group 做一个唯一性的识别,这样在 ping 子域名( user.vip.com )的时候就不会读到 info.user.vip.com 。 Skydns 本身目录结构的问题,加上 group 就不会再去读到下面的子路径。
Overlayfs issue: can ’ t doing mv operation
唯品会一直使用 Devicemapper ,中间尝试一些节点用 Overlayfs 的存储,但是在目录操作时会 file not found ,官方也有一个 issue 说当 Overlayfs 在不同的 layer 的时候,牵扯到删除的操作,会出现这个问题。可以升级解决,但是系统是固定的,升级很麻烦,所以没有做升级而是切回了 Devicemapper 。
Devicemapper 空间满,需要改造 cAdvisor 监控容器空间使用
由于容器占用的磁盘空间过多,导致了整个 k8s node 的磁盘空间被占满的问题,唯品会是在 Cadviser 做一些改造,可以监控到每一个容器所占用的磁盘空间,对磁盘空间做一些限制。
Kubernetes namespaces stuck in terminating state
在删除一个 namespace 的时候, namespace 是可以动态创建和删除的,在删除的时候会看到 namespace 一直处于 terminating 的状态,这个在 GitHub 上有一些解决方法,因为它本身是由于 namespace 的 finalizer 会进入一个死循环,有一个 work around ,可以手动的置空 finalizer ,把这个 namespace update 回去,就可以正常删除了。
以上就是我要分享的主要内容,谢谢大家。
目前尚无回复