推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide
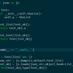
这是一个创建于 3545 天前的主题,其中的信息可能已经有所发展或是发生改变。
网站: http://sou.kuwo.cn/ws/NSearch?type=all&catalog=yueku2016&key=%E6%B1%AA%E5%B3%B0
要求:爬取其上的歌曲 ID ,歌名,歌手名
我写了个太难看了,如何写得更优雅点,或其它更好的方法
pat = re.compile(r'<p class="m_name">\s+<a href=".+?(\d+)/"\s*title="(.+?)".+?\s+.+?\s+.+?\s+.+?\s+.+?\s+?<p class="s_name".+?title="(.+?)"><')
res = pat.findall(html.read().decode())
另外:如何插入图片啊这里,代码也很乱
源码示例:
<li class="clearfix">
<p class="number"><input type="checkbox" checked="checked" name="musicNum" value="122560" mid="122560" />01</p>
<p class="m_name">
<a href="http://www.kuwo.cn/yinyue/122560/" title="怒放的生命" target="_blank">
<script>document.write("怒放的生命".replace(/(汪峰)/gi,'<em class="redFont">$1</em>'))</script>
</a>
</p>
<p class="a_name"><a href="http://www.kuwo.cn/album/7985/" title="怒放的生命" target="_blank"><script>document.write("怒放的生命".replace(/(汪峰)/gi,'<em class="redFont">$1</em>'))</script></a></p>
<p class="s_name"><a href="http://www.kuwo.cn/mingxing/%E6%B1%AA%E5%B3%B0/" target="_blank" title="汪峰"><script>document.write("汪峰".replace(/(汪峰)/gi,'<em class="redFont">$1</em>'))</script></a></p>
<p class="listen"><a href="http://player.kuwo.cn/MUSIC/MUSIC_122560" title="怒放的生命试听" target="_blank"></a></p>
<p class="video"><a href="http://www.kuwo.cn/mv/122560/" title="怒放的生命 MV" target="_blank"></a></p>
<p class="share"><a href="javascript:void(0);" onclick="showShareMusic(this,'怒放的生命','','122560')" title="分享"></a></p>
<p class="down"><a href="javascript:void(0);" title="怒放的生命下载" onclick="showDownMusic2014('MUSIC_122560');"></a></p>
</li>
要求:爬取其上的歌曲 ID ,歌名,歌手名
我写了个太难看了,如何写得更优雅点,或其它更好的方法
pat = re.compile(r'<p class="m_name">\s+<a href=".+?(\d+)/"\s*title="(.+?)".+?\s+.+?\s+.+?\s+.+?\s+.+?\s+?<p class="s_name".+?title="(.+?)"><')
res = pat.findall(html.read().decode())
另外:如何插入图片啊这里,代码也很乱
源码示例:
<li class="clearfix">
<p class="number"><input type="checkbox" checked="checked" name="musicNum" value="122560" mid="122560" />01</p>
<p class="m_name">
<a href="http://www.kuwo.cn/yinyue/122560/" title="怒放的生命" target="_blank">
<script>document.write("怒放的生命".replace(/(汪峰)/gi,'<em class="redFont">$1</em>'))</script>
</a>
</p>
<p class="a_name"><a href="http://www.kuwo.cn/album/7985/" title="怒放的生命" target="_blank"><script>document.write("怒放的生命".replace(/(汪峰)/gi,'<em class="redFont">$1</em>'))</script></a></p>
<p class="s_name"><a href="http://www.kuwo.cn/mingxing/%E6%B1%AA%E5%B3%B0/" target="_blank" title="汪峰"><script>document.write("汪峰".replace(/(汪峰)/gi,'<em class="redFont">$1</em>'))</script></a></p>
<p class="listen"><a href="http://player.kuwo.cn/MUSIC/MUSIC_122560" title="怒放的生命试听" target="_blank"></a></p>
<p class="video"><a href="http://www.kuwo.cn/mv/122560/" title="怒放的生命 MV" target="_blank"></a></p>
<p class="share"><a href="javascript:void(0);" onclick="showShareMusic(this,'怒放的生命','','122560')" title="分享"></a></p>
<p class="down"><a href="javascript:void(0);" title="怒放的生命下载" onclick="showDownMusic2014('MUSIC_122560');"></a></p>
</li>
 |
1
fy 2016 年 5 月 2 日
比较复杂的 html 就使用 lxml
而且说实话这种东西没什么复杂不复杂的,挂了就修,忘记了就重写,一个正则能顶个十天半个月的,你管他好不好看 |
 |
2
just1 2016 年 5 月 2 日 via Android
value="(\d+)"[\s\S]*(:?"(:?s|a)_name"[\s\S]*?title="(.*)?"){2}
难看,但是短了点 |
 |
3
qqmishi 2016 年 5 月 2 日 via Android
这种可以试试用 bueatifulsoup 解析
我的正则写的比你的更难看,但又不是不能用对吧,,,自用就懒得管优雅不优雅了 |
 |
4
icybee 2016 年 5 月 2 日
bs,pyquery?
|
 |
5
ayaseangle 2016 年 5 月 2 日
用 xml 解析方便。。。。
|
 |
6
skydiver 2016 年 5 月 2 日 via iPad
大忌就是用正则匹配 html
|
 |
7
binux 2016 年 5 月 2 日
html 不是正则语言,不符合正则文法
不要用正则解析 html ! 不要用正则解析 html ! 不要用正则解析 html ! |
 |
8
aprikyblue 2016 年 5 月 2 日 via Android
嗯。。楼上说的很清楚了。
会有各种坑 当然,如果是那种自己用几次就扔的,那当没说 |
 |
9
TangMonk 2016 年 5 月 2 日 via Android
用 xpath 嘛
|

 |
11
chairuosen 2016 年 5 月 2 日
pyquery
|
 |
12
explist OP 哪种方式速度快一点?我的正则实在是太慢了! OMGD
|
|
13
explist OP 好多都要生成树,而正则表达式写的好的话,会快一些?
|
 |
14
jackal 2016 年 5 月 2 日 抛开立场之分
(立场之分是指有人要让正则表达式做不该它做的事情,比如解析任意复杂的 html 等) 题主的问题是:希望从数个固定格式的网页数据中抓取固定模式的数据段。 我的意思是,前提条件是 kuwo 的歌曲网页数据都很固定,而且网页中关于歌曲 id ,歌曲名称,歌手名称,都是固定的模式数据( class=“ number ”, class=“ name ” , class=“ s_name ”) 这样,我觉得一个简单的实现,是可以用正则表达式来解析 /抓取数据的。 题主的正则表达式已经可以了,只是 3 点还有问题: 1 )应该遵从 class=“ number ”, class=“ name ” , class=“ s_name ”的格式来抓取对应的数据,而不是从其他地方去获取(以后就算页面改版,很可能 class 的名字和对应数据是不会改变的) 2 )让.*能够匹配换行,这样你的正则表达式中+?\s+.+?\s+.+?\s+.+?\s+.+?\s+?就不要再出现了。 3 )为提高效率,尽量使用普通字符串( plain text )匹配,少用.*+?等符号 |
 |
15
N4HS3zwwKs7wira0 2016 年 5 月 2 日
|
|
16
jackal 2016 年 5 月 2 日
|
 |
17
xiamx 2016 年 5 月 2 日
Html 是 Context Free Grammar ,不是 Regular Language 所以不能被 Regular expression 识别
|
|
19
explist OP @jackal 贴 个比较数据对新手来说要求有点高啊,以上所说的第三方库都没学习过,还要从头来,只知道一个自带的:
html.parser.HTMLParser |
|
20
N4HS3zwwKs7wira0 2016 年 5 月 2 日
@jackal Regex 不加奇怪的语法是 O(n). Suffix array 可以 O(m), m 是 query string length , n 是 text length 。但现在 Regex 语法太杂,如果不能用 DFA model ,复杂度很容易 blow up.
|
|
22
explist OP 这下好了点: r'<p class="m_name">\s+<a href=".+?(\d+)/"\s*title="(.+?)"[\s\S]+?<p class="s_name".+?title="(.+?)"><'
|
|
23
N4HS3zwwKs7wira0 2016 年 5 月 2 日
@explist Add (?s) before your regexp.
|
|
24
jackal 2016 年 5 月 2 日 我看到非常多的网友在回复中说, 不能用正则表达式来做这件事情。
我已经在我的回复中表达了这一点:“抛开立场之见”, 如果这个任务相对简单,不做其他扩展, 则完全可以用正则表达式来完成。 也请大家在做结论的时候, 切勿简单的思考或者表明立场。 实际上, 不少的网友心里并没有认真思考过, 什么叫合适, 什么叫不合适, 而是简单尊从 StackOverflow 或者某一些结论。 任何正确的结论都有前提条件; 当前提条件不满足了, 正确的就可能变成错误的结论, 希望大家深思。 |
|
25
jackal 2016 年 5 月 2 日
@explist 匹配换行符, 使用[\s\S]
不建议从<p class="m_name">里面去抓数据。 衡量性能, 请安装一个 RegexBuddy (这个是收费的)或者有好几个网站提供网页(免费,请自己找一下)来做类似的事情。 |
 |
26
cevincheung 2016 年 5 月 2 日
xpath 啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊!!!!
|
 |
27
jarlyyn 2016 年 5 月 2 日 via Android
@jackal
既然这个观点是你提出来的,那烦请给出范例。 作为一个方面做 mud 机器人正则写到吐,现在写 web 各种 class 混用的人,好奇怎么处理多 class 的 html. 我就不提万一 html 里有注释这种蛋疼的情况了。 |
|
28
fy 2016 年 5 月 2 日 |

|
33
just1 2016 年 5 月 2 日 via Android
reg='value="(\d+)"[\s\S]*?"a_name"[\s\S]*?title="(.*?)"[\s\S]*?"s_name"[\s\S]*?title="(.*?)"'
|
 |
34
eoo 2016 年 5 月 2 日 via Android
对于一个写 PHP 的我来说 我比较倾向于正则表达式 ,如果用类似 Simple HTML DOM 来解析 HTML 或者引入几十 K 甚至上百 几百 K 的类来解析 HTML 估计内存会挂掉。
|
 |
35
bigwahaha 2016 年 5 月 2 日
xpath 去解析 html 才是正道,楼主快回来
|
|
36
explist OP 这样速度快了不少:
re.compile(r'"m_name">.+?/(\d+)/"\s*title="(.+?)".+?s_name".+?title="(.+?)"',re.S) |
|
38
xiamx 2016 年 5 月 2 日
@jackal "抛开立场之分 (立场之分是指有人要让正则表达式做不该它做的事情,比如解析任意复杂的 html 等) "
正则表达式_不能_解析 html 。 正则能解析的 HTML 只是当前 HTML 文档的一个子集。 |
 |
39
52cik 2016 年 5 月 3 日
js 的正则是这样的,不知道其他语言能不能跑。
musicNum\D+(\d+)[^(]+\("([^"]+)[^(]+...([^)]+) $1 是 id ,$2 是歌曲,$3 是歌手 |
 |
40
retanoj 2016 年 5 月 4 日
我在源码里直接搜索 li class="clearfix 就定位到 n 条歌曲记录
不可以先对源码 parse 一下,然后用 xpath 或者各种选择器去选么? 例如 document.querySelector("li[class='clearfix'] > p[class='m_name'] > a").getAttribute('title') |