
这是一个创建于 384 天前的主题,其中的信息可能已经有所发展或是发生改变。
问题来自在看这篇博客时看到的图片
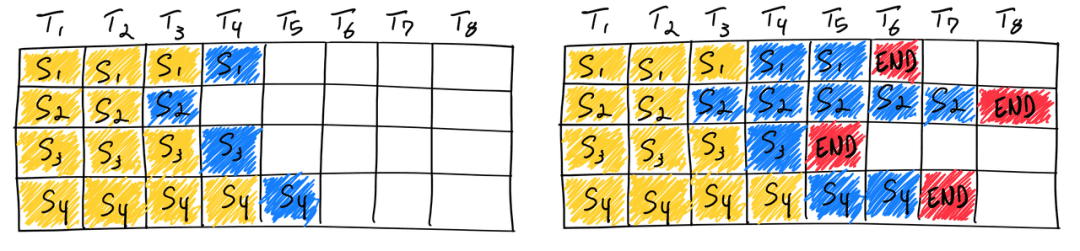
这张图片中是静态 batch 的示意图,但我的理解似乎有所偏差,希望有大佬能答疑解惑。
问题 1:对于静态 batch 场景,同一个 batch 中不同的 sample 的 prefill 是同时完成的吗?
我的理解: 对于一个单独的短 prompt ,prefill 阶段肯定是一个比很长的 prompt 快的。但是当这 2 个长度不同的 sample 经过 padding 然后拼成了一个静态 batch 之后,也就是维度变成了 [batch_size, ..] (当然这里可能不止 2 个 sample )。在 prefill 阶段,他们肯定是同时开始的,因为 transformers 内部是很多的矩阵乘法。并且要经过很多层,比如:
emb = layer1(emb)
emb = layer2(emb)
...
上面的 emb 的维度应该也都会是 [batch_size, ....]
虽然同一个 batch 之间不同 sample 单独做 prefill 需要的时间不同,但是当他们成为一个 batch 之后,变成了一个大矩阵,他们在经过不同的 layer 的时候,都是一起一层一层过的,也就相当于他们同时开始 prefill 阶段,然后同时完成 layer1, 同时完成 layer2, ......。最后一起完成最后一层,获得第一个预测的 new_tokens ( batch 中每个 sample 都有一个 new_token)。所以,在我的理解中,prefill 阶段应该是左右对齐的。
问题 2: 以下我对 Continuous Batch 的理解是否正确?
我的理解:
- 首先模型每次 forward 都是生成一个新的 token (无论是 prefill 还是 decoder 阶段)。prefill 完成生成第一个 new_token 后接着自回归。
- 如果是 continous batch 配置情况下,如果有 sample 输出 end_token ,那 batch_size 就少一个,可能就可以再放一个 sample 进来。这样子的话这个新 sample 要做 prefill (目的也是生成 new token ),别的 sample 是继续在 decoder 阶段。不过别的 sample 都是有前面的 kvcache 的,所以这个时候这个新 sample 的 prefill 就拖累了旧的 sample 中的 decoder 过程,毕竟大家都还是在一个 batch 中,大家最终还是一起一层 layer 一层 layer 过。
- 如果同一个 batch 都在 decoder 阶段,因为 kvcache 的存在大家都很快。但是只要有一个 sample 输出了 end_token, 就可能允许新的 sample 进来,这个新 sample 的 prefill 过程因为可能没有 kvcache 会拖累其他的 sample 。所以有一些工作提出要将 prefill 和 decoder 分离。
以上是我的理解,不知道有多少错误的内容,希望有大佬指正。我的描述可能有点啰嗦,抱歉。
 |
1
RoccoShi 2025 年 1 月 11 日
op 理解都没啥问题吧我感觉, static batching 和 continuous batching 区别就是每一次 decode 生成新 token 后如何处理, 和 prefill 没啥关系, prefill 肯定都是一起的
静态 batching 就是生成 eos_token 后的 sequence 还要等着 batch 里其他所有 sequence 都生成 eos_token 后一起输出 continuous batching 就是发现有 eos_token 就直接拿出来, 塞一个新的 sequence 进来, 至于 prefill 是塞进来后再做还是做好再塞进来, 都可以 PS: 随便找了个 huggingface TGI continuous batching 的伪代码 ( https://medium.com/@martiniglesiasgo/anatomy-of-tgi-for-llm-inference-i-6ac8895d903d)  PPS: 理解可能也有问题, 也不是专业的, 就碰巧之前也看过这个博客, 期待其他大佬补充( |
 |
2
huc2 OP @RoccoShi orz ,我主要是看到最上面那篇博客里的图,他每一列对齐是用 token 对齐的,从某种角度看似乎也没错。但是我脑子里想这个过程的时候,就总是一个 batch 里大家先一起 prefill (也就是我说的 prefill 阶段是左右都对齐的),然后大家每个 new_token 都一起生成第一个,第二个,,,这样子。然后看他这个图就很别扭,所以想确认一下我的理解是否有误。
|
 |
3
frankyzf 2025 年 1 月 11 日
|
|
4
frankyzf 2025 年 1 月 11 日
|
 |
5
bug2018 2025 年 1 月 11 日
之前实现过 continuous batching, 会把 prefill 和 decode 拼在一次处理。新 sample 的插入确实会打断 decode ,现象就是用户生成会卡顿,如果 prompt 不长一般影响不大,但长 prompt 高 qps 下会非常影响性能。
对此业界有一些应对方案,1. 前缀缓存 2. chunk split 3. prefill 和 decode 分离 。前两个方案可以缓解打断问题,方案 3 可以彻底解决打断问题。 |
|
6
huc2 OP @frankyzf 谢谢谢谢,有空去刷刷
@bug2018 谢谢大佬回复,我感觉方案 1 和方案 2 其实本质都差不多,都是利用提前算好的 kv 来缓解这个问题。但是我对方案 2 有一些疑问,chunk split 是不是一种损失精度的方式。因为 kv 只有第一层 layer 是上下文无关的,切了 chunk 后,后面 layer 的 kv 都缺失了很多上下文。这个方法让我想到了最近看到的这个里面提到的 kvcache 不光可以前缀匹配,后面甚至中间的匹配也可以用到,我当时也很疑惑。这种方法在实际操作过程中是不是都会损失精度 https://zhuanlan.zhihu.com/p/17239625983?utm_medium=social&utm_psn=1860823961383874560&utm_source=wechat_session |