
这是一个创建于 509 天前的主题,其中的信息可能已经有所发展或是发生改变。
构建 AI 化需要的知识体系
Semantic Kernel
Semantic Kernel 是 Microsoft 推出的一个开源框架,旨在帮助开发者构建和部署 AI 应用,特别是那些需要理解和生成自然语言的应用。它提供了一种结构化的方式来定义和管理技能( Skills ),这些技能可以是简单的函数调用,也可以是复杂的 AI 模型交互。
核心组件
- Kernel: Semantic Kernel 的核心,负责技能的管理和执行。
- Skills: 定义了应用可以执行的一系列操作,可以是本地函数,也可以是远程服务调用。
- Prompt Templates: 用于生成和修改自然语言的模板,支持变量和函数调用。
- Memory: 提供了存储和检索应用状态的能力,可以是简单的键值对,也可以是复杂的图数据库。
LangChain
LangChain 是一个开源框架,专注于构建应用,这些应用可以利用大型语言模型( LLMs )来执行各种任务,如回答问题、生成文本、执行代码等。它提供了一种灵活的方式来组合和调用不同的 LLMs ,以及管理与这些模型的交互。
核心组件
- Chains: 定义了模型调用的逻辑流程,可以是简单的单步调用,也可以是复杂的多步流程。
- Prompts: 用于指导模型生成特定类型输出的模板。
- Memory: 提供了存储和检索应用状态的能力,可以用于上下文理解和历史记录。
- Agents: 可以自动执行任务的实体,基于给定的目标和约束。
总结
Semantic Kernel 和 LangChain 都是为了简化 AI 应用的开发,但它们的侧重点不同。Semantic Kernel 更注重技能的定义和管理,而 LangChain 则更侧重于大型语言模型的组合和调用。选择哪个框架取决于具体的应用场景和需求。
在我们的场景里我们更多的是考虑使用 semantic kernel 的方式来构建,不是说 langchain 不好,只是 langchain 的代码侧抽象的东西太厉害,本身架构也比较重,对于后期开发的运维和迭代成本比较高,我们现在的体量还太小,感觉自身玩不太动。
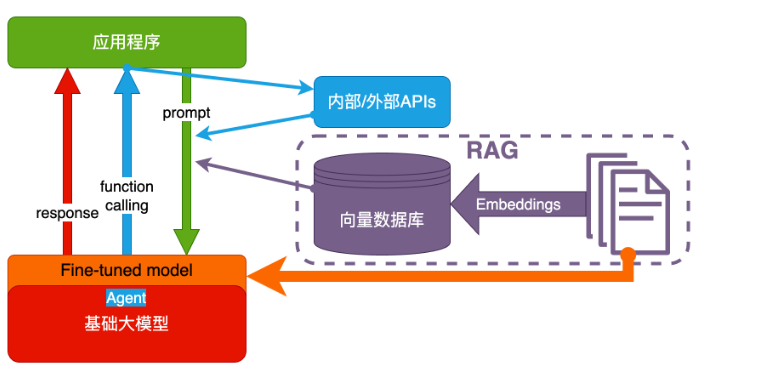
大模型的应用架构
典型的业务架构
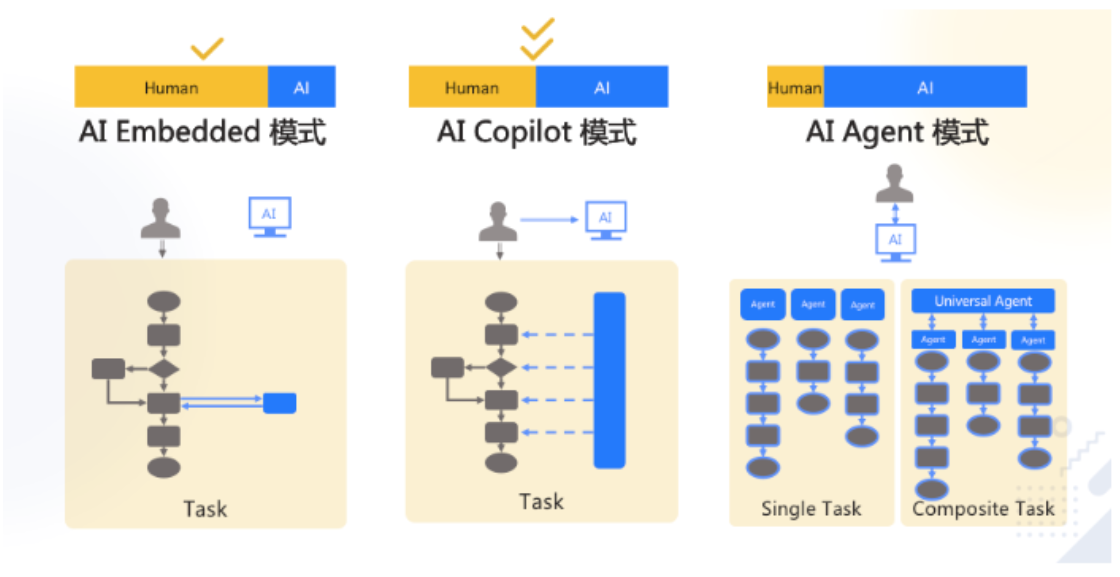
技术架构
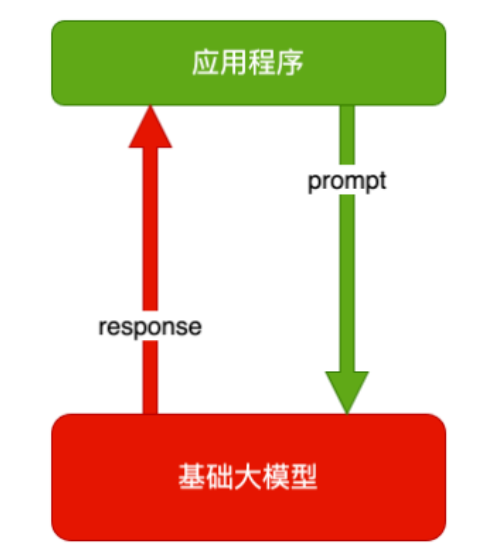
纯 Prompt
就像和一个人对话,你说一句,ta 回一句,你再说一句,ta 再回一句
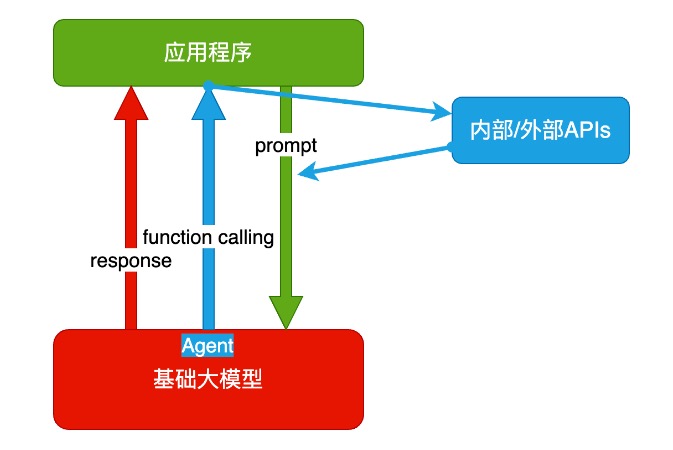
agent + FC (Function calling)
- Agent:AI 主动提要求
- Function Calling:AI 要求执行某个函数
场景举例:你问过年去哪玩,ta 先反问你有几天假
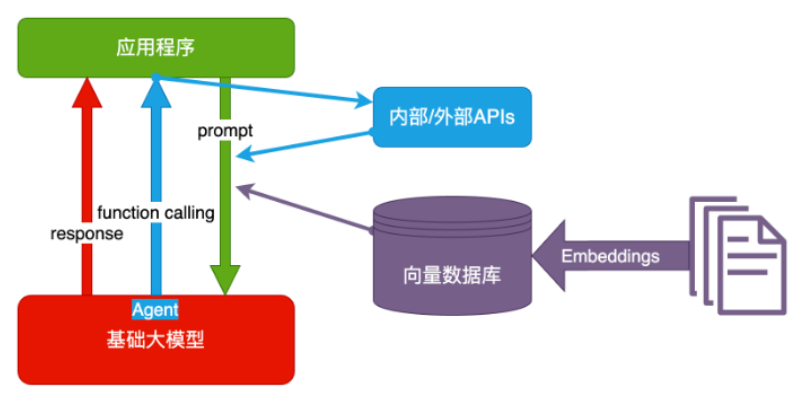
RAG(Baseline)= Embeddings + 向量数据库
- Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量
- 向量数据库:把向量存起来,方便查找
- 向量搜索:根据输入向量,找到最相似的向量
- 场景举例:考试时,看到一道题,到书上找相关内容,再结合题目组成答案。然后,就都忘了
目前我们还使用了 rerank model 对 RAG 的结果进行重排序,使得得到更精准的答案
Fine-Tuning
努力学习考试内容,长期记住,活学活用
目前传统的 FT 对于在运维体系中,特别是抽象对象的训练达不到一个很好的效果,所以我们也在尝试基于 DeepKe 的抽象方式做运维体系中的数据,文本做 FT ,看是不是能把抽象的对象直接关系能理解清楚
Prompt 的工程:提升 LLM 理解与响应能力
Prompt 设计原则
为什么要说 Prompt ,其实有了架构,但如何让 LLM 理解你的推理依据,那就需要 Prompt 提示工程来解决,不同的 LLM 的 chat_template 的模版也是完全不同的,也就会导致不同的模型你用同一种 Prompt 的方式无法得到一样的答案,甚至于同一个模型多次重复同一个问题也会存在差异的现象。
从我的个人实践来说,总结主要有以下几条原则:
- Write clear instructions (写出清晰的指令)
- Provide reference text (提供参考文本)
- Split complex tasks into simpler subtasks (将复杂的任务拆分为更简单的子任务)
- Give the model time to "think"(给模型时间“思考”)
- Use external tools (使用外部工具)
- Test changes systematically (系统地测试变更)
具体实现的方式
1.把话说详细
尽量多的提供任何重要的详细信息和上下文,说白了,就是把话说明白一点,不要一个太笼统。 比如:不要说:“总结会议记录” 而是说:“用一个段落总结会议记录。然后写下演讲者的 Markdown 列表以及他们的每个要点。最后,列出发言人建议的后续步骤或行动项目(如果有)。”
2.让模型充当某个角色
你可以把大模型想象成一个演员,你要告诉他让他演什么角色,他就会更专业更明确,一个道理。 比如:充当一个喜欢讲笑话的喜剧演员,每当我请求帮助写一些东西时,你会回复一份文档,其中每个段落至少包含一个笑话或有趣的评论。
3.使用分隔符清楚地指示输入的不同部分
三引号、XML 标签、节标题等分隔符可以帮助划分要区别对待的文本节。可以帮助大模型更好的理解文本内容。我最喜欢用"""把内容框起来。 比如:用 50 个字符总结由三引号分隔的文本。"""在此插入文字"""
4.指定完成任务所需的步骤
有些任务能拆就拆,最好指定为一系列步骤。明确地写出这些步骤可以使模型更容易去实现它们。 比如:使用以下分步说明来响应用户输入。 步骤 1 - 用户将为您提供三引号中的文本。用一个句子总结这段文字,并加上前缀“Summary:”。 步骤 2 - 将步骤 1 中的摘要翻译成西班牙语,并添加前缀“翻译:”。
5.提供例子
也就是经典的少样本提示,few-shot prompt ,先扔给大模型例子,让大模型按你的例子来输出。 比如:按这句话的风格来写 XX 文章:"""落霞与孤鹜齐飞,秋水共长天一色。渔舟唱晚,响穷彭蠡之滨"""
6.指定所输出长度
可以要求模型生成给定目标长度的输出。目标输出长度可以根据单词、句子、段落、要点等的计数来指定。中文效果不明显,同时你给定的长度只是个大概,多少个字这种肯定会不精准,但是像多少段这种效果就比较好。 比如:用两个段落、100 个字符概括由三引号分隔的文本。"""在此插入文字"""
提示框架应用
是不是遵循着一套方式就可以一路梭了呢,显然不是,对于不同的任务背景其实还需要使用不同的提示词框架来做具体任务的实现,由于涉及到具体内容太过冗长,我这里也就直接给出有哪些框架和实现的框架逻辑
TAG 框架
- 任务( Task ):描述您所要求完成的具体任务。
- 行动( Action ):细致描述所需采取的动作。
- 目标( Goal ):明确您追求的最终目的。
SPAR 框架
- 情境( Scenario ):勾勒出背景蓝图。
- 问题( Problem ):阐释所面临的难题。
- 行动( Action ):详细说明所需实施的策略。
- 结果( Result ):描绘期待的成果。
TRACE 框架
- 任务( Task ):确定并明确具体的任务。
- 请求( Request ):表述所希望请求的具体事项。
- 行动( Action ):描述必须实施的行动。
- 背景( Context ):提供相关背景或情境。
- 示例( Example ):用实例来阐明您的见解。
SCOPE 框架
- 情境( Scenario ):描写当前状况或情景。
- 复杂情况( Complications ):讨论任何潜在的复杂因素。
- 目标( Objective ):描述预期的目标。
- 计划( Plan ):阐述实现目标所需的策略。
- 评估( Evaluation ):讲述如何评估成功的标准。
APE 框架
- 行动( Action ):说明所完成的具体工作内容。
- 目的( Purpose ):讲解行动背后的意图或目标。
- 期望( Expectation ):阐明所期待的结果或成功的标准。
SAGE 框架
- 情况( Situation ):描述背景或当前情况。
- 行动( Action ):详细说明所需进行的行动。
- 目标( Goal ):明确目标所在。
- 预期( Expectation ):阐明您所期望获得的结果。
RTF 框架
- 角色( Role ):定义 LLM 的角色定位。
- 任务( Task ):详述特定的任务内容。
- 格式( Format ):说明您所期望的答案形式。
ROSES 模型
- 角色( Role ):界定 GPT 所扮演的角色。
- 目标( Objective ):明确您的意图。
- 情境( Scenario ):描述具体情境与环境。
- 解决方案( Solution ):设定所期望的结果。
- 步骤( Steps ):咨询解决问题的具体步骤。
CARE 框架
- 背景( Context ):界定讨论的场景或上下文环境。
- 行动( Action ):说明期望完成的行动。
- 结果( Result ):阐明期待的结果。
- 示例( Example ):提供一个例证以阐述您的观点
以上不同的提示框架对于具体实际的应用场景中需要灵活的去实现,天下没有一招鲜的武功,要用好大模型提升助力,底层的逻辑实现与框架的了解是必不可少的,否则 LLM 只是一个聊天工具,并不能为你的工作带来质的提升
让 LLM 理解逻辑推理:从 CoT 到 ReAct
上面几个 KeyPoint 解释了在 LLM 中实现应用的主要的技术或者方式,但真正要让 LLM 作为一个 AGENT 或者 Copilot 存在,还需要有一个关键的点,那就是如何让 LLM 知道你的推理方式,其实 LLM 解决只是技术差距的问题,但它无法解决提出问题的源头,所以其实在 LLM 的今天,对于大家来说有想法且逻辑清楚的人,有了 LLM 的加持可能真的会一飞冲天,如果你能提出好的问题,那么就能得到一个好的答案。
那么推理架构有具体哪些呢,我在这里只说一些相对用的比较多的,特别是在运维运营场景中比较容易落地的方式。
CoT ( chain-of-thought prompting )思维链
提示通过中间推理步骤实现了复杂的推理能力。您可以将其与少样本提示相结合,以获得更好的结果,以便在回答之前进行推理的更复杂的任务.对于解决数据等具体落地问题,可以显著提高大模型的推理方面的能力。
区别于传统的 Prompt 从输入直接到输出的映射 <input——>output> 的方式,CoT 完成了从输入到思维链再到输出的映射,即 <input——>reasoning chain——>output>。
例如,如果问题是“纽约到洛杉矶的距离是多少?”,模型可能首先检索纽约和洛杉矶的坐标,然后计算两点之间的距离,最后给出答案。在这个过程中,模型不仅提供了答案,还展示了其推理过程,增强了答案的可信度。
Auto-CoT 自动思维链
即利用 LLMs “让我们一步一步地思考” 提示来生成一个接一个的推理链。这种自动过程仍然可能在生成的链中出现错误。为了减轻错误的影响,演示的多样性很重要。这项工作提出了 Auto-CoT ,它对具有多样性的问题进行采样,并生成推理链来构建演示。
Auto-CoT 主要由两个阶段组成:
- 阶段 1:问题聚类:将给定问题划分为几个聚类
- 阶段 2:演示抽样:从每组数组中选择一个具有代表性的问题,并使用带有简单启发式的 Zero-Shot-CoT 生成其推理链
例如,如果问题是“如果一个苹果的重量是 150 克,那么 10 个苹果的总重量是多少?”,Auto-COT 模型可能会生成这样的思维链:“10 个苹果的总重量 = 10 * 150 克 = 1500 克”。这样,用户不仅得到了答案,还了解了模型是如何得出这个答案的。
在运维的告警源头判断做辅助,或者故障处理建议等方面可以产生不错的效果,也降低新人工技能培训的投入,更容易让运维人员统一视角与标准。
TOT ( Tree of Thought ) 思维树
这里我可能需要特别说一下思维树这个框架,"TOT 思维树"并不是一个广泛认可或标准的术语,因此其具体定义可能在不同的上下文或领域中有所变化。但我们可以基于“思维树”的概念来理解它可能的含义。
思维树( Tree of Thoughts )是一种用于表示和组织思考过程的结构化方法,它以树状图的形式展示思考的层次和分支。在决策制定、问题解决、创意生成等场景中,思维树可以帮助人们系统地探索各种可能性,评估不同选项,从而做出更明智的决策。
在思维树中:
- 根节点:通常代表问题或决策的起点,即需要解决的核心问题。
- 分支:从根节点开始,每个分支代表一个可能的思考方向或解决方案。分支可以进一步细分,形成更详细的子分支,代表更具体的思考步骤或子问题。
- 叶节点:树的末端,代表思考过程的最终结果或结论。
通过构建思维树,人们可以:
- 系统地探索:确保所有可能的思考方向都被考虑,避免遗漏重要的信息或解决方案。
- 评估和比较:通过比较不同分支的结果,评估各种选项的优劣,做出更合理的决策。
- 增强理解:通过可视化思考过程,增强对问题的理解,使复杂的决策过程变得清晰。
目前针对 TOT 我们还没有得到特别好的效果,可能是在构建当中还有不合理的定义或者解析问题不精准的存在。但从对于资源的合理性投入,供应链的管理,提高决策质量和效率它应该是有天然的优势存在,如果有哪位大佬对 TOT 有深度尝试并有合理化建议的,请给出更多的好的建议,在此先谢过了。
ReAct ( Retrieval-Augmented Generation for Thinking and Acting )
其实对于这个框架,我个人总结来看,可以理解为是一种结合了推理和行动的新型人工智能框架,主要用于增强 AI 系统在复杂环境中的决策能力和执行效率。ReAct 框架的核心思想是通过实时检索相关信息和执行基于这些信息的行动,来辅助 AI 系统进行更准确的推理和决策。
在 ReAct 框架中,AI 系统不仅依赖于其预训练的知识,还会在遇到新情况时,主动检索外部信息(如数据库、网络资源等),并将这些信息整合到其决策过程中。这一过程可以看作是 AI 系统在“思考”( Reasoning )和“行动”( Acting )之间的循环,其中:
- 思考( Reasoning ):AI 系统基于当前状态和目标,进行推理和规划,确定下一步需要采取的行动或需要检索的信息。
- 行动( Acting ):根据推理结果,AI 系统执行相应的行动,如检索信息、执行任务等。
- 反馈:AI 系统根据行动的结果,更新其状态和知识,然后再次进入思考阶段,形成一个闭环。
ReAct 框架的优势在于,它使 AI 系统能够适应不断变化的环境,处理之前未见过的情况,而不仅仅是依赖于预训练数据。通过实时检索和整合新信息,AI 系统可以做出更准确、更灵活的决策,提高其在复杂任务中的表现。
总结来说:ReAct 是 Reason + Action ,而 Cot 、ToT 则只是 Reason 。ReAct 与 CoT 和 ToT 的本质区别,就是 ReAct 不止在推理,还在利用外部工具实现目标,我不知道这里解释大家是不是能明白..
运维场景应用
- 告警分析与故障处理:利用 CoT 与 Auto-CoT 辅助故障诊断,提供决策支持。
- 资源管理与优化:TOT 框架帮助系统化分析资源分配,提升运维效率。
- 动态决策与执行:ReAct 框架在复杂运维场景中,实现基于实时信息的决策与行动
通过深度探索与实践,我们正逐步构建基于 LLM 的运维体系,旨在提升运维效率与可观测性。未来,我们将继续探索更多创新场景,推动 AI 技术在运维领域的广泛应用,期待与更多同行携手,共同开创运维智能化的新篇章。
本文旨在分享 AI 在运维领域的实践与思考,通过 Semantic Kernel 、LangChain 、RAG 、Fine-Tuning 等技术,结合 Prompt 工程与推理架构,探索如何有效提升运维效率与可观测性。期待与更多技术探索者和实践者共同推动 AI 在运维领域的创新与发展。
- 原文链接: https://flashcat.cloud/blog/ai-you-need-to-know/
- 作者是 Zenlayer 高级网络工程师钱老师在第二届 CCF 夜莺开发者创新论坛上所做的分享的补充和展开。内容包括 AI 方向的一些实践效果、基础知识、选型思考等。
9 条回复 • 2025-07-31 11:15:17 +08:00
 |
1
NeverBB 2024 年 8 月 26 日 via Android
第一次见这里看到这么长而正经
|
 |
2
AaronWang13 2024 年 8 月 26 日
第一次见这里看到这么长而正经
|
 |
3
Imr 2024 年 8 月 26 日
看文中写的主要还是停留在 llm 的提示词框架和一些技术原理或者名词解释,AIOps 大方向都一样还是提升运维效率和可观测性。
AI + 运维确实很有意思,但是我一个做运维想来想去也不知道在哪里用,不知道 v2er 有没有稍微成熟的应用分享一下。我目前体验过的就是 deepflow 自带的 askgpt 。 另外对于不熟悉领域的技术名词,用 llm 就可以帮你写笔记,参考使用麦肯锡提问的方法: https://ki6j1b0d92h.feishu.cn/wiki/E4I1wSQY6i2GxAkMANuc0E8anRd TL;DR 例如对 llm 提问:用麦肯锡的快速了解行业方法,通过大量行业高频关键词来建立概念。现在我是一个对<大模型技术>不了解的小白,请你给我整理出 50 个常用关键词,制作成 Markdown 表格,表头是:关键词(英文)、关键词(中文)、介绍(限 50 字)、应用场景。 再下一步,让 llm 对这些词分批例如 10 个一组进行扩展介绍(避免太长),这样写笔记,学习概念快得多 |
 |
4
laiwei OP @NeverBB @AaronWang13 已经控制长度了,内容再多就看不完了~
|
 |
5
raincaptain 2024 年 8 月 30 日
行家啊,码了这么多字,路过留痕
|
|
6
laiwei OP @raincaptain 收藏起来慢看看:)
|
 |
7
testliyu 2024 年 12 月 3 日
牛的
|
 |
8
xdc 2025 年 3 月 18 日
收藏 = 会了
|
 |
9
YoungCrocodile 2025 年 7 月 31 日
老师,图挂啦
|