
这是一个创建于 740 天前的主题,其中的信息可能已经有所发展或是发生改变。
Detect GPU
起因
在开发 gpu-docker-api时,需要先获取主机的 GPU 信息,然后使用 UUID 给容器分配 GPU 。
从网上找到了 go-nvml 能够很简单的获取 GPU 信息,输出结果类似于 nvdia-smi,问题是它必须跑在装好 NVIDIA 驱动的 Linux 服务器上,最重要的是当我们开发的项目引入它后,都不能运行。类似的报错如下:
# github.com/NVIDIA/go-nvml/pkg/dl
/Users/ming/go/pkg/mod/github.com/!n!v!i!d!i!a/[email protected]/pkg/dl/dl.go:34:18: could not determine kind of name for C.RTLD_DEEPBIND
后来想到在本机启动一个 Docker 容器然后编译也是比较方便,后来折腾了半天,没有成功最后放弃了。
于是想到把这个功能抽离出来,同时提供一个 HTTP 接口,通过调用的方式来获取 GPU 信息。当然这个 HTTP 服务要跑在带有 NVDIA 驱动的 Liunx 驱动上。
这样我们就能在 macOS 或 Windows 下开发项目了。
笔者平时使用 golang 进行开发,工作中经常遇到,有时只需要简单的两三个接口,同事都要引入 GIN 框架、ZAP 日志框架等等,一个非常简单的项目导致依赖非常多,同时也没有 Makefile 、测试用例,构建、启动只能问同事,然后复制粘贴。
当然我没有鄙视这种行为,能解决问题的方法就是好方法。只不过在空闲时间,研究研究也是挺好的。所以贯彻 Golang 的 Less is more 理念,尽量引入第三方库,尽量使用原生方法来写本项目。
项目中使用的库都是我感觉非常简洁、好用的,大家可以进行参考。
项目地址
使用
可以从 release 下载二进制文件,扔到服务器上运行。或者克隆到本地,然后构建。
git clone https://github.com/mayooot/detect-gpu
cd detect-gpu
make linux
默认程序会占用 2376 端口,api 地址为 /api/v1/detect/gpu 。
$ curl 127.0.0.1:2376/api/v1/detect/gpu
[
{
"index":0,
"uuid":"uuid",
"name":"NVIDIA A100 80GB PCIe",
"memoryInfo":{
"Total":85899345920,
"Free":63216877568,
"Used":22682468352
},
"powerUsage":74634,
"powerState":0,
"powerManagementDefaultLimit":300000,
"informImageVersion":"1001.0230.00.03",
"systemGetDriverVersion":"525.85.12",
"systemGetCudaDriverVersion":12000,
"tGraphicsRunningProcesses":[]
},
{
"index":1,
"uuid":"uuid",
"name":"NVIDIA A100 80GB PCIe",
"memoryInfo":{
"Total":85899345920,
"Free":30687952896,
"Used":55211393024
},
"powerUsage":65507,
"powerState":0,
"powerManagementDefaultLimit":300000,
"informImageVersion":"1001.0230.00.03",
"systemGetDriverVersion":"525.85.12",
"systemGetCudaDriverVersion":12000,
"tGraphicsRunningProcesses":[]
}
]
当然也可以在 golang 项目中直接引用。如下:
package main
import (
"fmt"
"time"
"github.com/mayooot/detect-gpu/pkg/detect"
)
func main() {
timeOutDuration := 500 * time.Millisecond
testClient := detect.NewClient(detect.WithTimeout(timeOutDuration))
if err := testClient.Init(); err != nil {
panic(err)
}
defer testClient.Close()
gpus, err := testClient.DetectGpu()
if err != nil {
panic(err)
}
for _, gpu := range gpus {
fmt.Printf("%#+v\n", gpu)
}
}
个人感觉好用的库
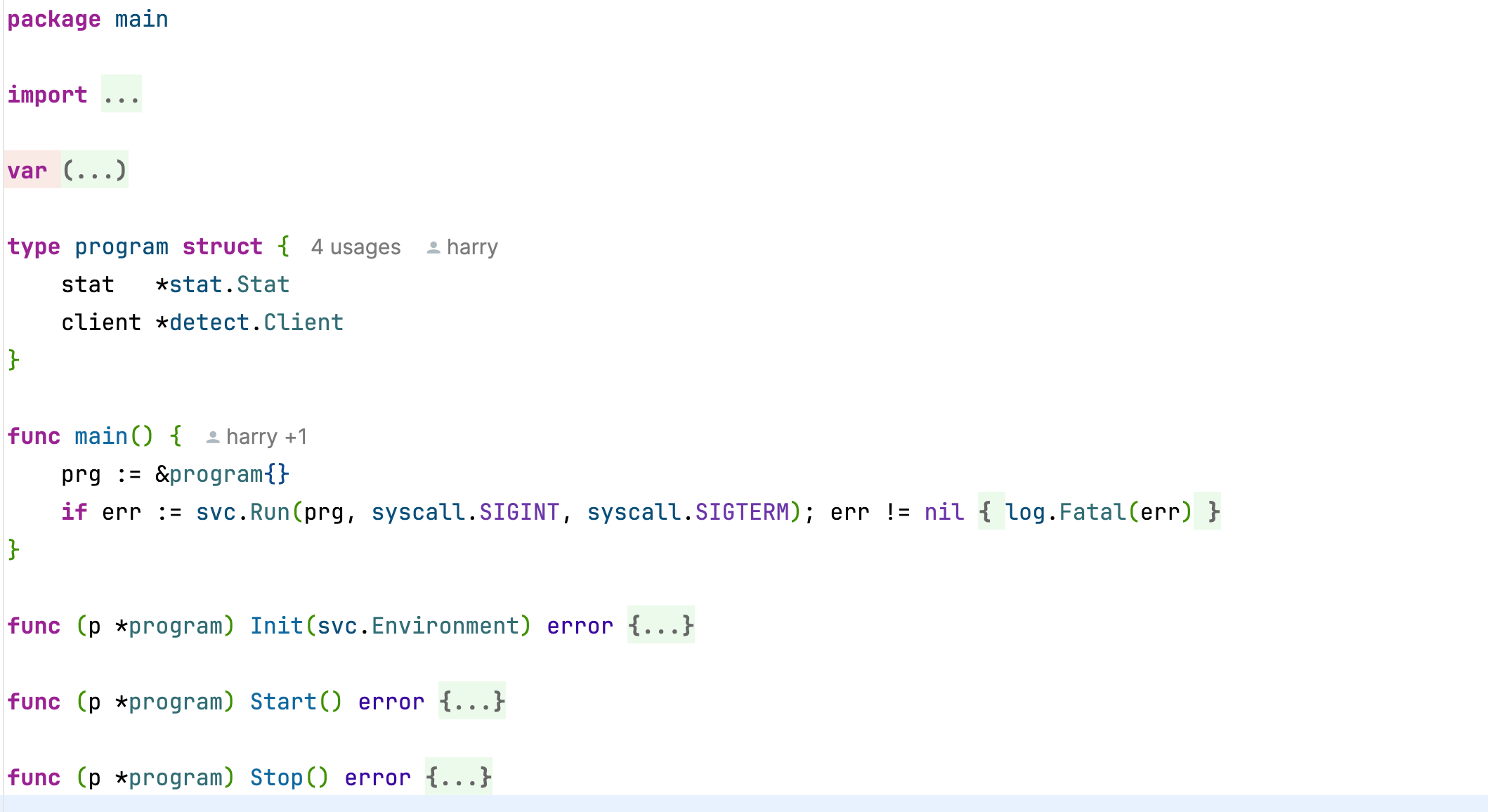
go-svc
一般启动一个 web 服务时,需要做好初始化工作,比如初始化数据库、Redis 。然后异步启动并阻塞,最后优雅关闭,释放资源。
常用的写法就是声明一个监听信号量的 channel ,然后 select 等待。go-svc 进行封装,能让代码看起来更加简洁。
ngaut/log
这个库是我开发一些简单的项目时最喜欢的日志库了,它只对 GO 自带的 log 库进行了简单的封装,不同的日志级别有不同的颜色。
比如该项目启动和结束时,打印的日志:

pflag
非常棒的命令行解析库,支持全拼参数和简写,使用起来只能说太爽了。

最后
如果对你有用的话,你可以把该项目当成一个快速开发的模板进行参考。同时有任何的 bug/意见,欢迎你提 issue ,我很乐意解答。
 |
1
mayooot OP 项目地址贴错了,应该是: https://github.com/mayooot/detect-gpu 。😅
|
 |
2
009694 2024 年 1 月 8 日 via iPhone
没有更详细操作 gpu 的需求,为什么不执行 nvidia-smi -L 直接获取? 先判断有没有这个命令就可以了
|
|
3
mayooot OP @009694 你可以看一下我上面提到的 gpu-docker-api 项目,它需要为容器指定 GPU 的 UUID 。我是在 mac 上开发的,执行 nvidia-smi -L ,也没有结果。而且开发的时候,不方便把代码传送到具有 GPU 的 linux 服务器上,只能这样抽取一下。
|
 |
4
qieqie 2024 年 1 月 9 日 via iPhone
业界普遍用环境变量去做容器化调度 GPU 的,用 device id 就好。
go-nvml 底层使用的 dl_open+cgo 方式去访问 nv 驱动中动态库的 c 接口,你这个报错多半是编译环境里 libc 版本太低了。 如果想要不引入 cgo 来支持 GPU 检测最简单就是在启动脚本执行 nvidia-smi 然后作为命令行或者环境变量参数丢给程序入口就好。 |
|
5
mayooot OP @qieqie 感谢大佬!当时因为比较着急要获取到 uuid ,感觉解析命令行有点麻烦,所以就直接使用了 go-nvml 库。我本地是 macOS ,所以执行 nvidia-smi 也没有结果的,主要还是懒得把代码扔到服务器上,因为是个人开发着练习练习,没考虑那么多。
|
|
6
qieqie 2024 年 1 月 9 日
@mayooot 试试 nvidia-smi --query-gpu=index,uuid --format=csv,noheader,nounits
本地开发用 go 的编译 tags 控制下,mock 一个假的返回就行,我比较早一个项目就是这么搞的。 |
 |
8
zeusho871 2024 年 1 月 27 日 via Android
我用 zebra 加 Uber 那个 log 库,这个 go-svc 看起来不错,我去瞅瞅
|