

新年快乐!推一下自己的开源项目《Docker 二次开发 | NVIDIA Docker + Docker Client 调度 GPU 容器项目》
mayooot · 2024 年 1 月 1 日 · 1639 次点击这是一个创建于 756 天前的主题,其中的信息可能已经有所发展或是发生改变。
Docker 二次开发 | NVIDIA Docker + Docker Client 调度 GPU 容器项目
新年快乐🎉
前言
你是否有这样的困扰?实验室里新购买了一台多卡 GPU 服务器,你和你的师兄要在上面炼丹,但是你们用的 Python 、PyTorch 等工具版本不同,在宿主机共同操作很麻烦。
这时候 Docker 就可以大显身手了,首先你可以“先入为主”地把 Docker 容器理解成一个小型“虚拟机”,然后你和师兄各启动一个绑定了一张 GPU 卡的容器,就可以在容器里随意“折腾”了。但是默认的 Docker 是不支持 GPU 调度的,这就要求你要为 Docker 安装 NVIDIA Container Toolkit ,这样就可以轻松愉快的使用 Docker 炼丹了。这听起来很酷 😎。
但是,有一天你跑的模型占用的显存溢出了,一张卡已经满足不了你的需求,此时你会想,我再启动一个容器,绑定多张卡不就行了。然后你想到刚使用这个容器的时候,APT 源不能用,你 Google 了怎么换国内源; CUDA 报错,你又 Google 发现 PyTorch 要和 CUDA 版本匹配。为了跑起来这个模型,经历了太多太多,这时候重新创建一个容器,意味着再配置一遍,这一点都不酷 😭。
或者你是一个码农,你们老板敏锐的发现了这个痛点,这些研究生们要么实验室没显卡,要么卡的性能太落后,最重要的还有上述更新容器 GPU 配置后,需要重新安装软件、拷贝数据的问题。这不得狠狠赚它一把!
所以你被委派开发这个项目,你可能是容器领域大神,心想:直接把容器提交成镜像不就得了,这样子安装的软件都还在,然后把数据重新挂载到容器里。事实确实如此,但是我相信使用 GPU 容器的用户更多只想跑代码,并不是很了解 Docker 相关的知识,而且跑训练的容器动不动就 10GB 、20GB ,提交为镜像很耗时,怎么存储这些镜像又是一个问题。
所以我们的这个开源项目就派上用场了,项目提供了 RESTful API ,基本上请求的地址都能直译成汉语,很容易理解。所以它应该有两种用途。
比如你还是一个研究生,在实验室找个“德高望重”的师兄,拷贝运行这个项目,等新人来的时候,鼠标点一点就能为他创建一个 GPU 容器,或者新人受不了导师的 PUA ,润了,这时候点一点接口删除他这个容器,并回收 GPU 资源。又或者某位师兄需要更高的算力,调用更新接口为他的容器“升级”一下 GPU 配置即可,当然一切数据都在。
又或者你想提供 GPU 算力容器给客户、学生,基于本项目二次开发,即可上线一个支持升降配置的 GPU 算力平台。当然他要比 K8s 简单的多(当然功能也不如 K8s 的一根毛)。
介绍
该项目通过调用 NVIDIA-Docker 实现 GPU 容器无卡启动、升降 GPU 配置、扩缩容数据卷等功能,提供 RESTful API 。
类似于 AutoDL 中关于容器实例的操作。
项目地址: https://github.com/mayooot/gpu-docker-api
实现的功能
容器( Container )
- 创建 GPU 容器
- 创建无卡容器
- 升降容器 GPU 配置
- 升降容器 Volume 配置
- 停止容器
- 重启容器
- 在容器内部执行命令
- 删除容器
- 保存容器为镜像
卷( Volume )
- 创建指定容量大小的 Volume
- 删除 Volume
- 扩缩容 Volume
GPU
- 查看 GPU 使用情况
Port
- 查看已使用的端口号
效果 & 演示
演示部分接口,详情可见 GitHub。
创建一个 GPU 容器
我们创建一个名为 mankind 的容器。它的描述如下:
- name 为 mankind
- 使用 1 张 显卡
- 挂载 name 为 veil-0 的 Volume 到容器的 /root/veil-0 目录
- 挂载宿主机的 nfs 目录 /mynfs/data/ctr-mankind 到容器的 /root/data/ctr-mankind
- 注入一个 name 为 USER 的环境变量,值为 foo
- 容器要暴露 22 端口到宿主机,以方便远程连接
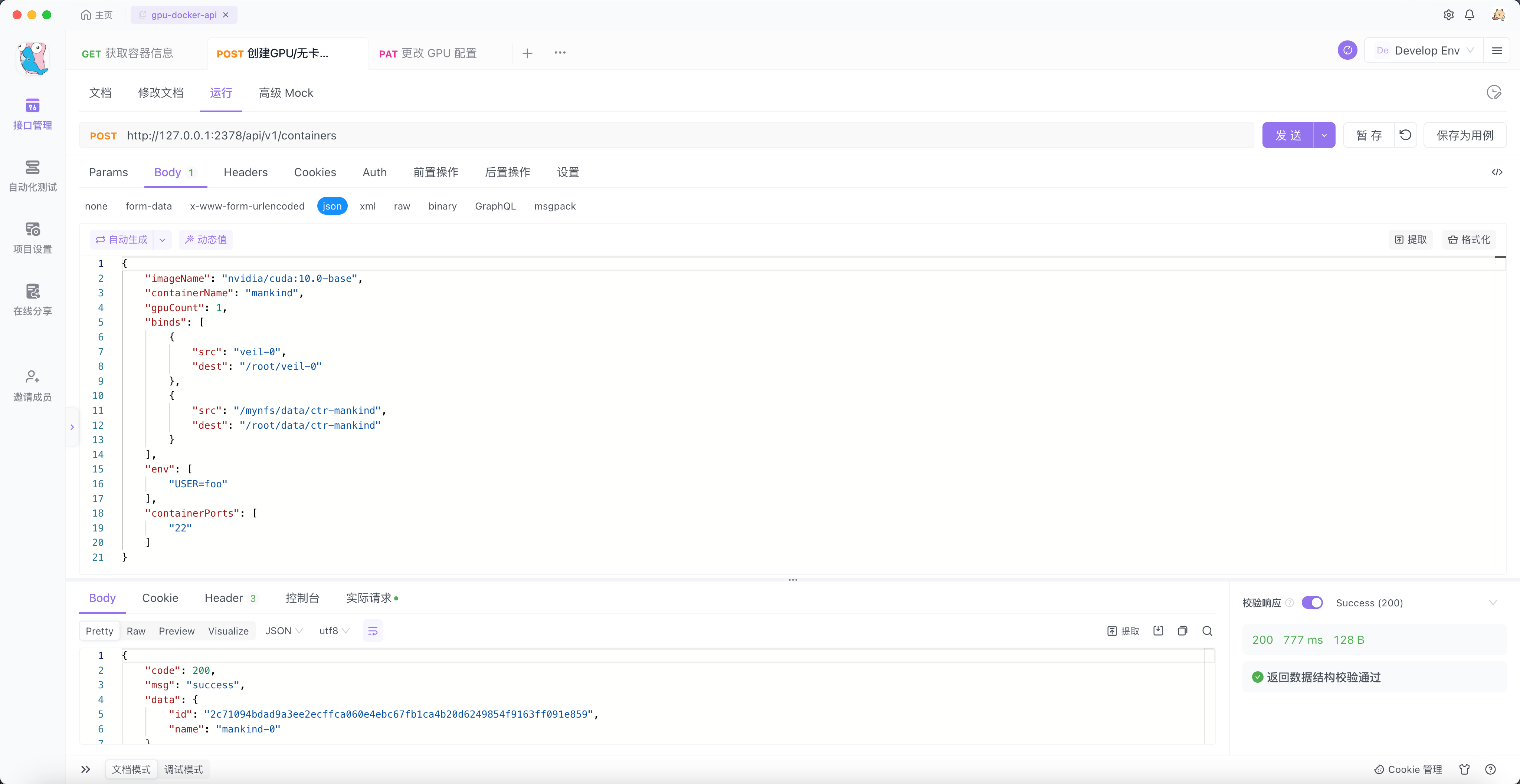
可以看到接口返回 success ,成功创建名为 mankind-0 的 1 卡容器(这里自动的为容器添加了版本号,目的是记录一下容器的当前版本)。
我们需要知道它暴露到宿主机上来的端口是多少,或者想要查看一下容器的其他信息。
通过调用 查看容器信息 接口,如下:
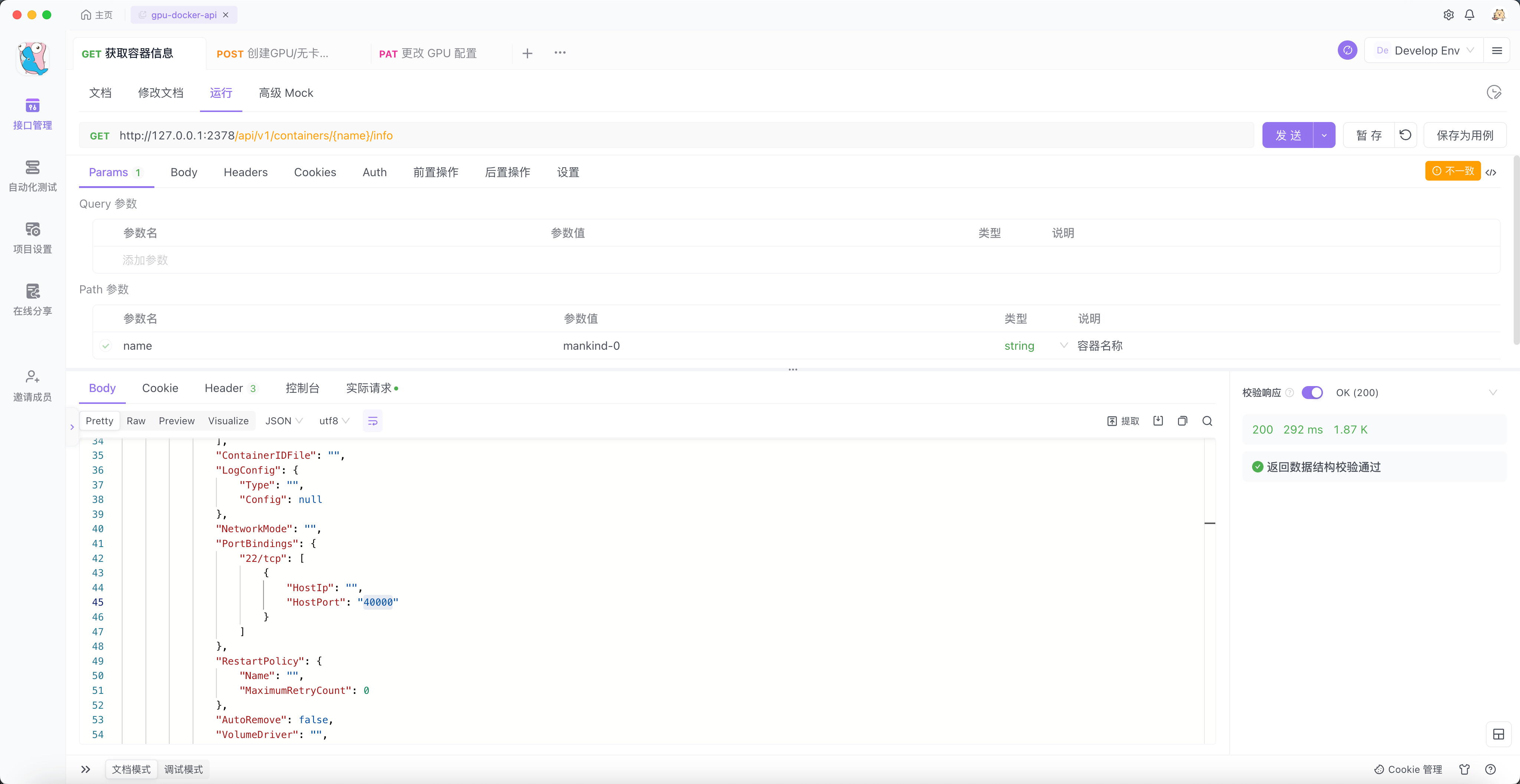
一切都很顺利,宿主机的 40000 端口映射到了容器的 22 端口。
如果我们进入容器并为它安装 SSH 服务,就可以很方便的通过如下的方式,来远程登录到容器。
ssh -p 40000 root@your_ip
当然我们还要验证一下,它是否能够使用 1 张 GPU 呢?通过执行下面的命令,发现在容器内部确实有 1 张 A100 的显卡可以使用。
$ docker exec mankind-0 nvidia-smi
Sun Dec 31 10:20:31 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100 80G... On | 00000000:36:00.0 Off | 0 |
| N/A 44C P0 65W / 300W | 51819MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
升级容器的 GPU 配置
只演示升级 GPU 的过程,降低 GPU 的配置、有卡容器变无卡、无卡容器变有卡的操作,只需改变 gpuCount 的参数即可。详情可见 GitHub 中的接口文档 gpu-docker-api-sample-interface.md 或导入 openapi.json 到 Postman 、Apifox 。
在训练模型的时候发现,1 张 A100 满足不了我的需要,此时要升级到 3 卡容器才行。
我先为你描述一下上面创建的容器,它的目录结构是怎样的。如下:
| 名称 | 路径 | 性能 | 说明 |
|---|---|---|---|
| 系统盘 | / | 本地盘,快 | 容器停止后数据不会丢失。一般系统依赖和 Python 安装包都会在系统盘下,保存镜像时会保留这些数据。容器升降 GPU 、Volume 配置后,数据会拷贝到新容器。 |
| 数据盘 | /root/foo-tmp | 本地盘,快 | 使用 Docker Volume 挂载,容器停止后数据不会丢失,保存镜像时不会保留这些数据。适合存放读写 IO 要求高的数据。容器升降 GPU 、Volume 配置后,数据会拷贝到新容器。 |
| 文件存储 | /root/foo-fs | 网络盘,一般 | 可以实现多个容器文件同步共享,例如 NFS 。 |
为了证明它升级 GPU 配置后,安装的软件和数据都存在,我们先进入到上面的容器。然后安装 Vim 、Python ,并在 /root/veil-0 目录下保存一些代码,如下所示:
$ docker exec -it mankind-0 bash
...
省略安装过程
...
$ vim --version | head -n 1
VIM - Vi IMproved 8.1 (2018 May 18, compiled Dec 07 2023 15:42:49)
$ python --version
Python 2.7.18
$ ls /root/veil-0/
main.py
$ python /root/veil-0/main.py
Hello World!
调用升级 GPU 的接口:
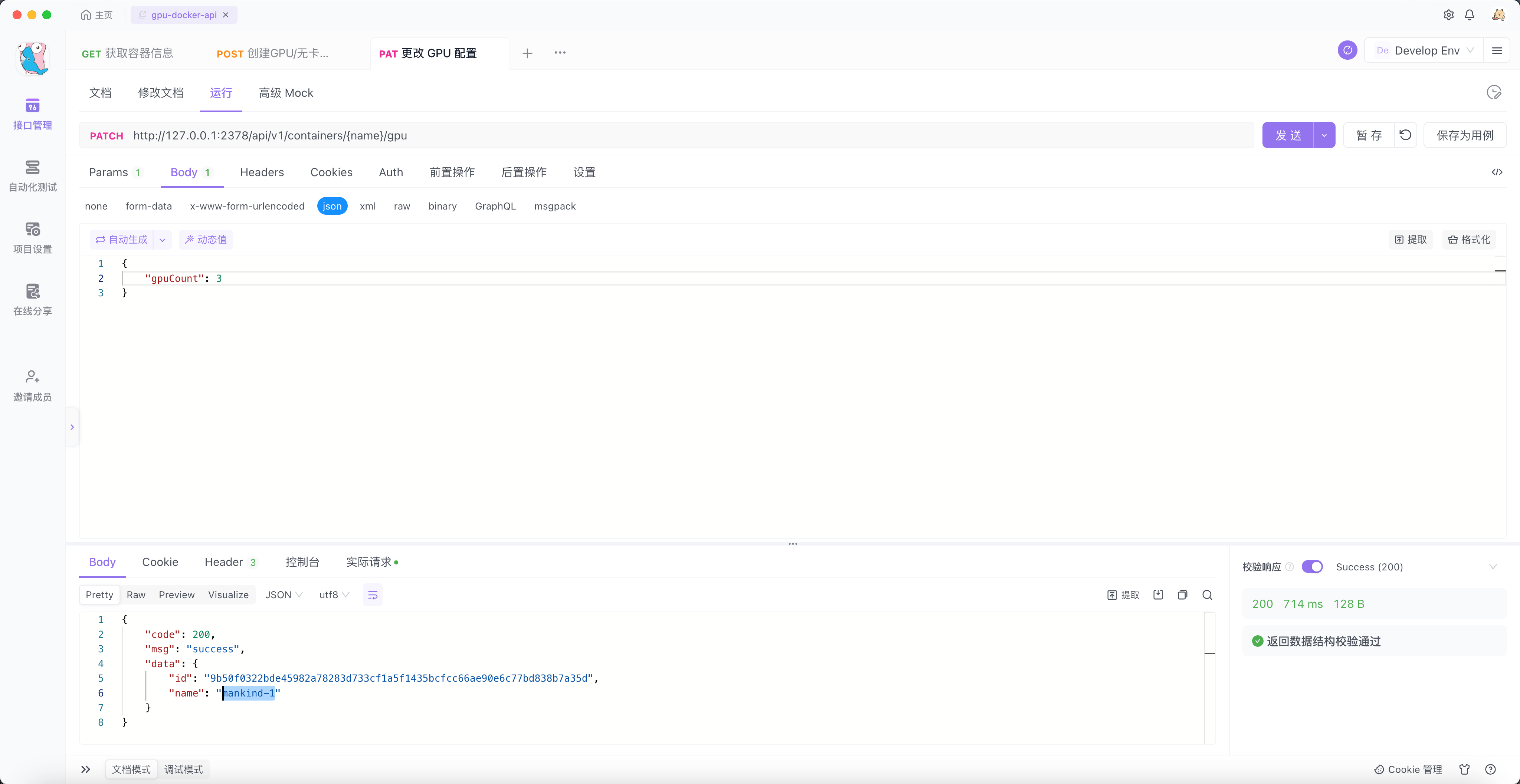
可以看到 mankind-1 被创建出来,此时我们进入容器查看它可以使用多少张卡,安装的 Vim 、Python ,以及在 /root/veil-0 目录下保存一些代码是否还在。
$ docker exec -it mankind-1 bash
$ nvidia-smi
Sun Dec 31 00:27:55 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100 80G... On | 00000000:36:00.0 Off | 0 |
| N/A 44C P0 65W / 300W | 51819MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100 80G... On | 00000000:3D:00.0 Off | 0 |
| N/A 41C P0 61W / 300W | 12355MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A100 80G... On | 00000000:91:00.0 Off | 0 |
| N/A 39C P0 46W / 300W | 0MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
$ vim --version | head -n 1
VIM - Vi IMproved 8.1 (2018 May 18, compiled Dec 07 2023 15:42:49)
$ python --version
Python 2.7.18
$ ls /root/veil-0/
main.py
$ python /root/veil-0/main.py
Hello World!
很好!结果符合我们的预期。不同于 K8s 的滚动更新,mankind-0 容器还会存在,只不过它是暂停状态。
值得注意的是它映射到宿主机的端口会发生变化,由 40000 变成了
40001 。之所以这样,是因为当我们对一个容器进行更新时,如果新版本的容器更新失败,旧版本的容器不应该被删除,而同一个宿主机端口号不能绑定到多个容器,所以重新获取一个端口号,俩个容器是相互独立的,当新容器启动成功后,再停止旧容器。
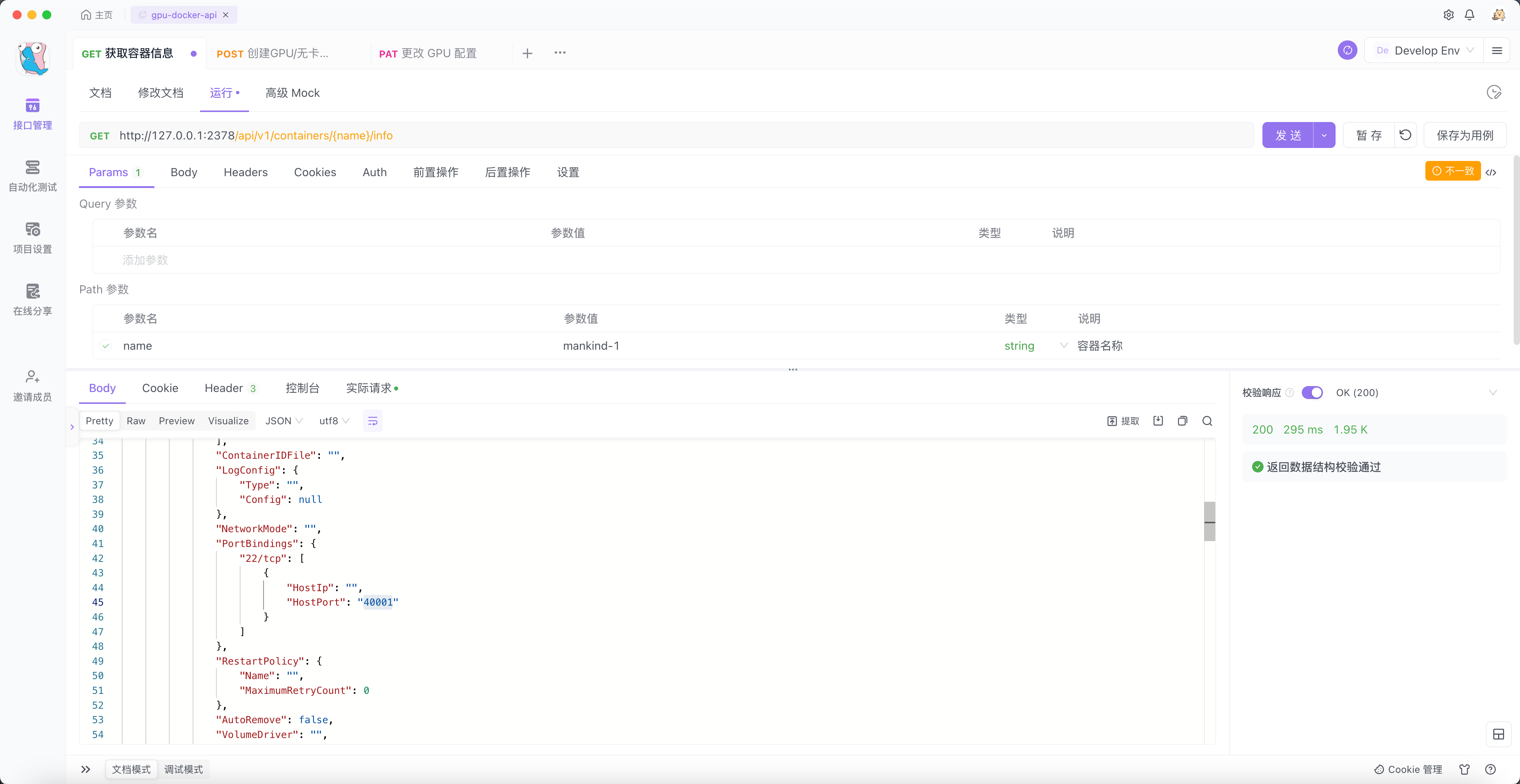
PS:例如容器从使用 1 张卡到使用 3 张卡的更新过程中,mankind 容器(不管版本号为 0 还是 1 )都会持续占用已分配的 1 张卡。然后再去申请两张卡,当新容器创建成功后,再去停止旧容器。
这样做的好处有:
-
当机器上空闲俩卡时,就能完成升级操作;
-
升级失败后,它还是拥有 1 张卡,旧的容器没被暂停。如果升级时就释放卡、停止容器,卡被别的用户占用,就会很尴尬的造成新容器因为 GPU 资源不够未能启动,旧容器也同样启动不了;
升级容器的 Volume 配置
只演示升级 Volume 大小的过程,降低操作同理。
首先调用接口创建 Volume ,指定 name 为 spill ,大小为 20GB 。
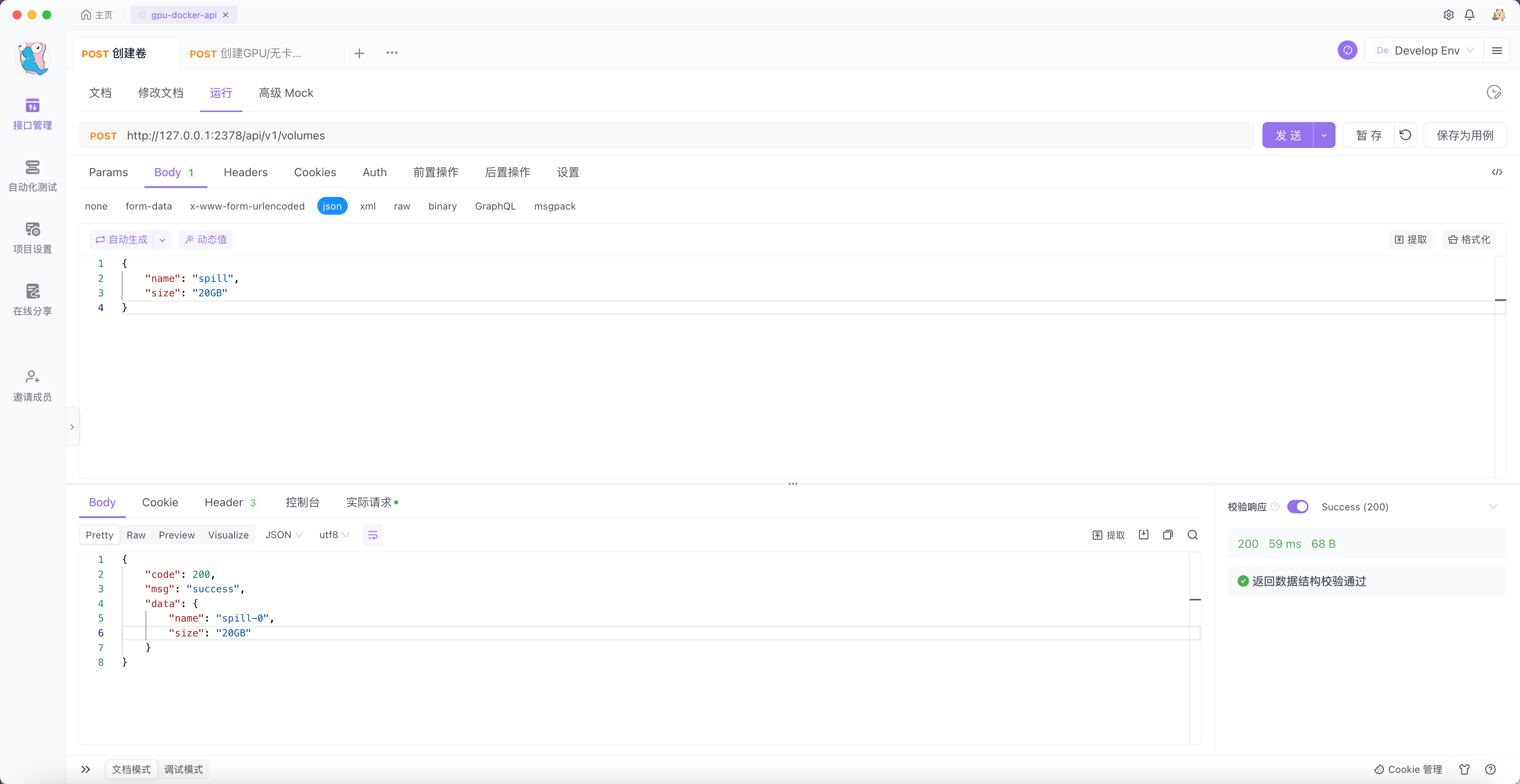
效果如下:
$ docker volume inspect spill-0
[
{
"CreatedAt": "2023-12-31T11:10:29Z",
"Driver": "local",
"Labels": null,
"Mountpoint": "/localData/docker/volumes/spill-0/_data",
"Name": "spill-0",
"Options": {
"size": "20GB"
},
"Scope": "local"
}
]
然后创建一个容器将 spill-0 挂载到 /root/spill-0 目录下,如下:
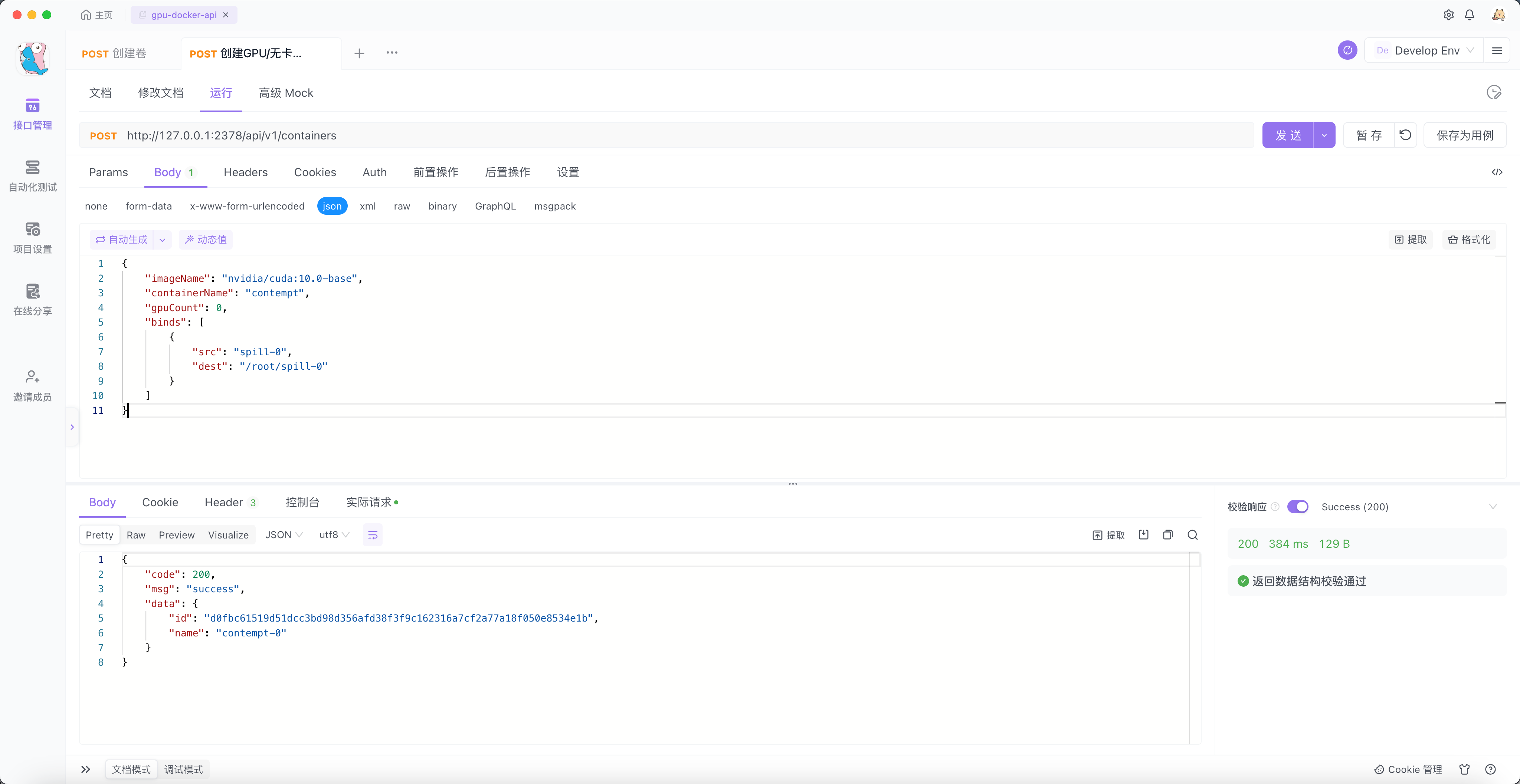
我们进入到 contempt-0 容器的 /root/spill-0 目录下,生成一个 10GB 大小的文件。
$ docker exec -it contempt-0 bash
$ cd /root/spill-0/
$ dd if=/dev/zero of=test bs=1G count=10
10+0 records in
10+0 records out
10737418240 bytes (11 GB, 10 GiB) copied, 6.2047 s, 1.7 GB/s
$ du -h test
10G test
接下来,先将 spill-0 Volume 扩容一倍。
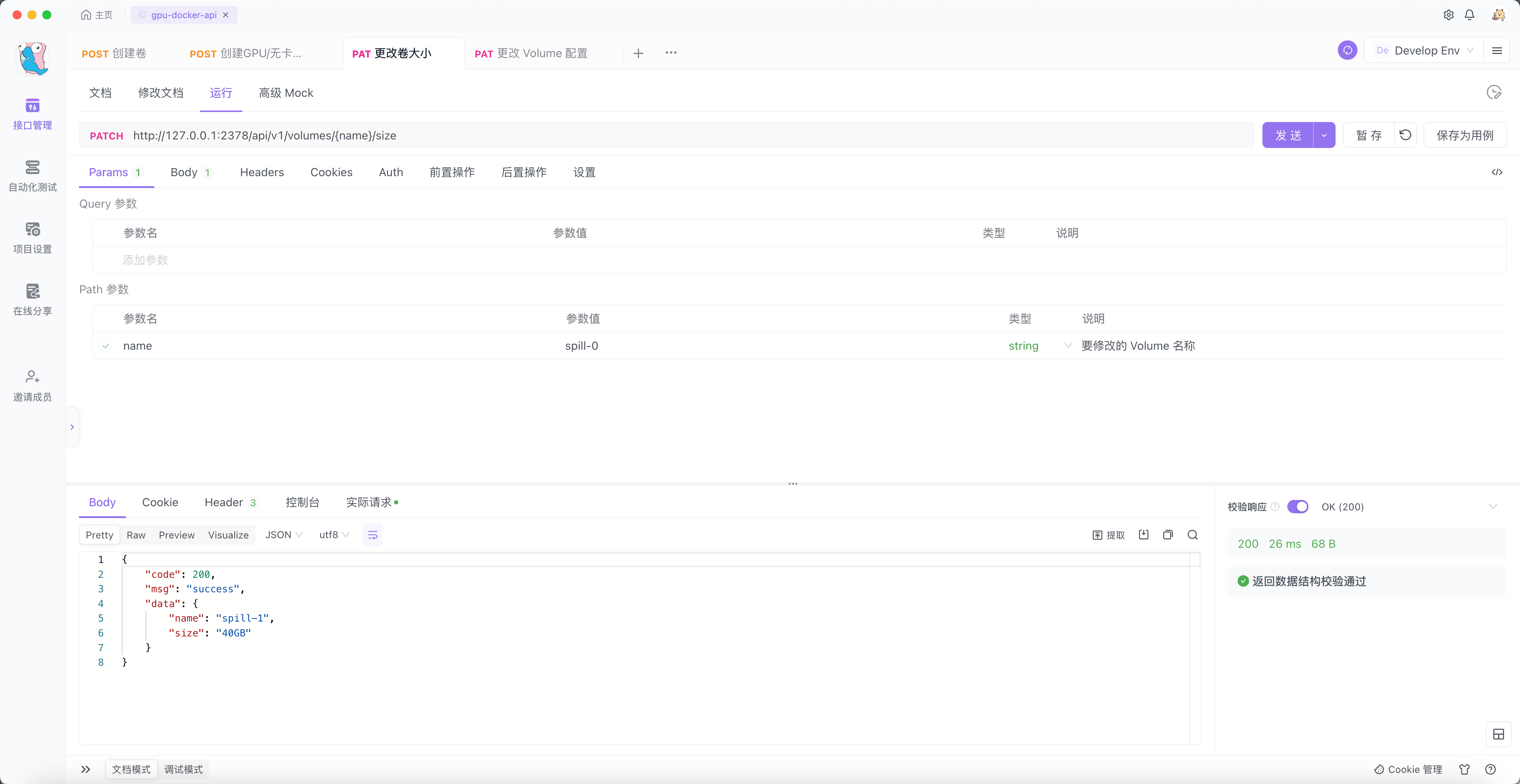
$ docker volume inspect spill-1
[
{
"CreatedAt": "2023-12-31T11:17:09Z",
"Driver": "local",
"Labels": null,
"Mountpoint": "/localData/docker/volumes/spill-1/_data",
"Name": "spill-1",
"Options": {
"size": "40GB"
},
"Scope": "local"
}
]
然后更改 contempt-0 容器的 Volume 配置。为了用户更好的体验,我们仍然将 spill-1 Volume 挂载到 /root/spill-0 目录下(可以任意填写 newBind 的 dest 字段,除了 / 目录)。
可以看到新的容器 contempt-1 已经启动。
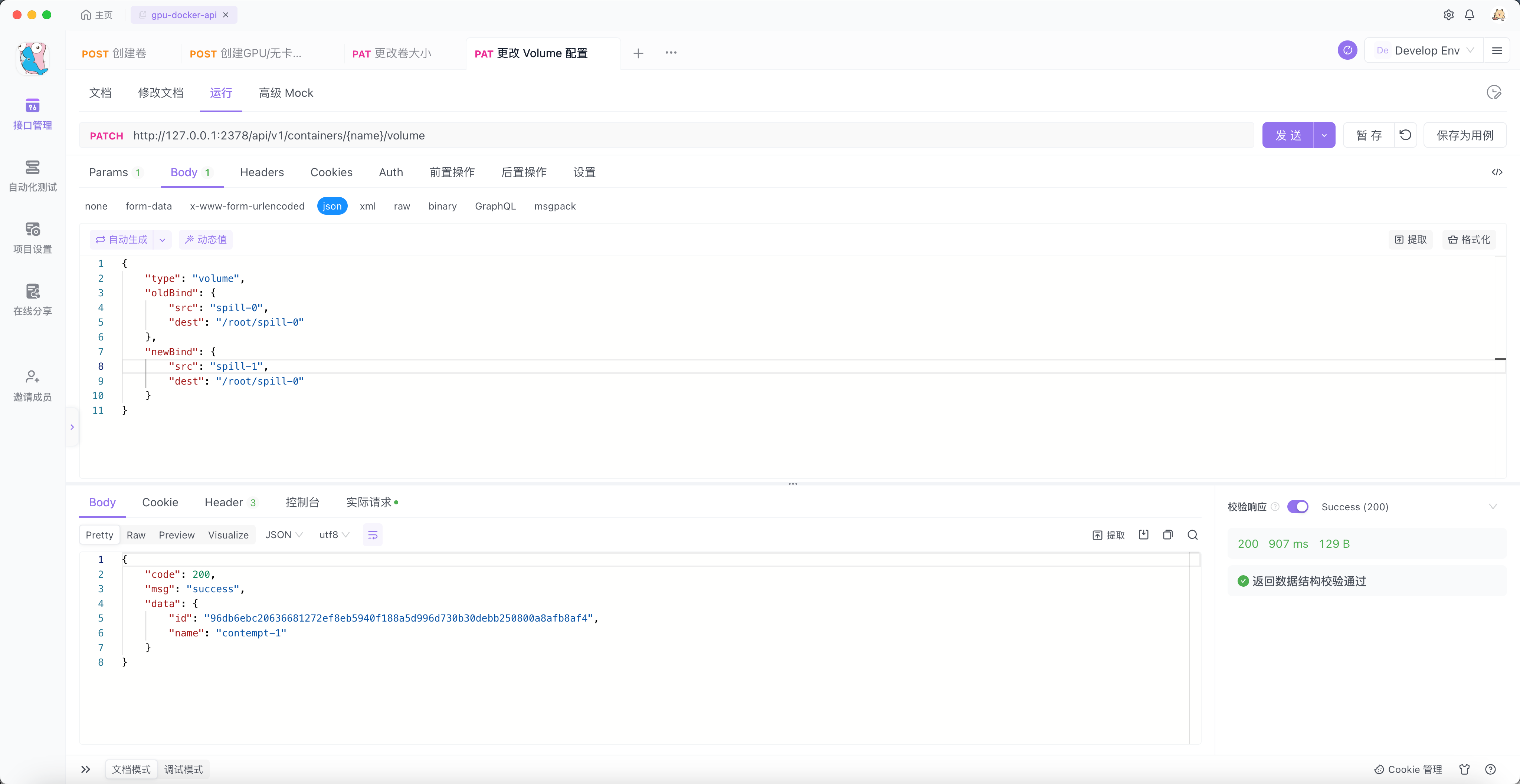
我们进入容器并验证一下。可以看到结果如我们所愿。
$ docker exec -it contempt-1 bash
$ ls -al /root/spill-0/
total 10485760
drwxr-xr-x 2 root root 26 Dec 31 11:17 .
drwx------ 1 root root 68 Dec 31 11:11 ..
-rw-r--r-- 1 root root 10737418240 Dec 31 11:15 test
$ du -h /root/spill-0/test
10G /root/spill-0/test
获取宿主机 GPU 资源
在 Golang 中获取 NVIDIA GPU 信息,可以引入 go-nvml。
令人不爽的是,项目引入这个包后,在启动的时候会把我们的开发环境(比如我们的电脑)当成安装了 NVIDIA 驱动的环境。所以就会报错,程序无法启动。
为了解决这个问题,我写一个小工具,它很简单,只是调用 go-nvml 并提供一个 HTTP 接口。我们通过访问这个 HTTP 接口,即可在不更改本机驱动的情况下,调用 Liunx 服务的 GPU 信息。
项目地址: https://github.com/mayooot/detect-gpu
构建 & 运行
环境准备
- 测试环境已经安装好 NVIDIA 显卡对应的驱动。
- 确保你的测试环境已安装 NVIDIA Docker ,安装教程:NVIDIA Docker 安装。
- 为支持创建指定大小的 Volume ,请确保 Docker 的 Storage Driver 为 Overlay2 。创建并格式化一个分区为 XFS 文件系统,将挂载后的目录作为 Docker Root Dir 。 详细说明:volume-size-scale.md
- 确保你的测试环境已安装 ETCD V3 ,安装教程:ETCD。
- 克隆并运行 detect-gpu。
release
你可以在直接下载 release 中合适的版本,然后直接执行。
或者按照以下步骤构建最新代码。
编译项目
git clone https://github.com/mayooot/gpu-docker-api.git
cd gpu-docker-api
make build
修改配置文件(可选)
vim etc/config.yaml
运行项目
./gpu-docker-api-${your_os}-amd64
架构
设计上受到了许多 Kubernetes 的启发和借鉴。
比如 K8s 将会资源( Pod 、Deployment 等)的全量信息添加到 ETCD 中,然后使用 ETCD 的版本号进行回滚。
以及 Client-go 中的 workQueue 异步处理。
组件介绍
-
gin:处理 HTTP 请求和接口路由。
-
docker-client:和服务器的 Docker 交互。
-
workQueue:异步处理任务,例如:
- 创建 Container/Volume 后,将创建的全量信息添加到 ETCD 。
- 删除 Container/Volume 后,删除 ETCD 中关于资源的全量信息。
- 升降 Container 的 GPU/Volume 配置后,将旧 Container 的数据拷贝到新 Container 中。
- 升降 Volume 资源的容量大小后,将旧 Volume 的数据拷贝到新的 Volume 中。
-
container/volume VersionMap:
- 创建 Container 时生成版本号,默认为 0 ,当 Container 被更新后,版本号+ 1 。
- 创建 Volume 时生成版本号,默认为 0 ,当 Volume 被更新后,版本号+ 1 。
程序关闭后,会将 VersionMap 写入 ETCD ,当程序再次启动时,从 ETCD 中拉取数据并初始化。
-
gpuScheduler:分配 GPU 资源的调度器,将容器使用 GPU 的占用情况保存到 gpuStatusMap 。
- gpuStatusMap: 维护服务器的 GPU 资源,当程序第一次启动时,调用 detect-gpu 获取全部的 GPU 资源,并初始化 gpuStatusMap ,Key 为 GPU 的 UUID ,Value 为使用情况,0 代表未占用,1 代表已占用。
程序关闭后,会将 gpuStatusMap 写入 ETCD ,当程序再次启动时,从 ETCD 中拉取数据并初始化。
-
portScheduler:分配 Port 资源的调度器,将容器使用的 Port 资源保存到 usedPortSet 。
- usedPortSet: 维护服务器的 Port 资源,已经被占用的 Port 会被加入到这个 Set 。
程序关闭后,会将 usedPortSet 写入 ETCD ,当程序再次启动时,从 ETCD 中拉取数据并初始化。
-
docker:实际创建 Container 、Volume 等资源的组件,并安装了 NVIDIA Container Toolkit ,拥有调度 GPU 的能力。
-
etcd:保存 Container/Volume 的全量创建信息,以及生成 mod_revision 等 Version 字段用于回滚资源的历史版本。存储在 ETCD 中资源如下:
- /apis/v1/containers
- /apis/v1/volumes
- /apis/v1/gpus/gpuStatusMapKey
- /apis/v1/ports/usedPortSet
- /apis/v1/versions/containerVersionMapKey
- /apis/v1/versions/volumeVersionMapKey
-
dete-gpu:调用 go-nvml 的一个小工具,启动时会提供一个 HTTP 接口用于获取 GPU 信息。
架构图
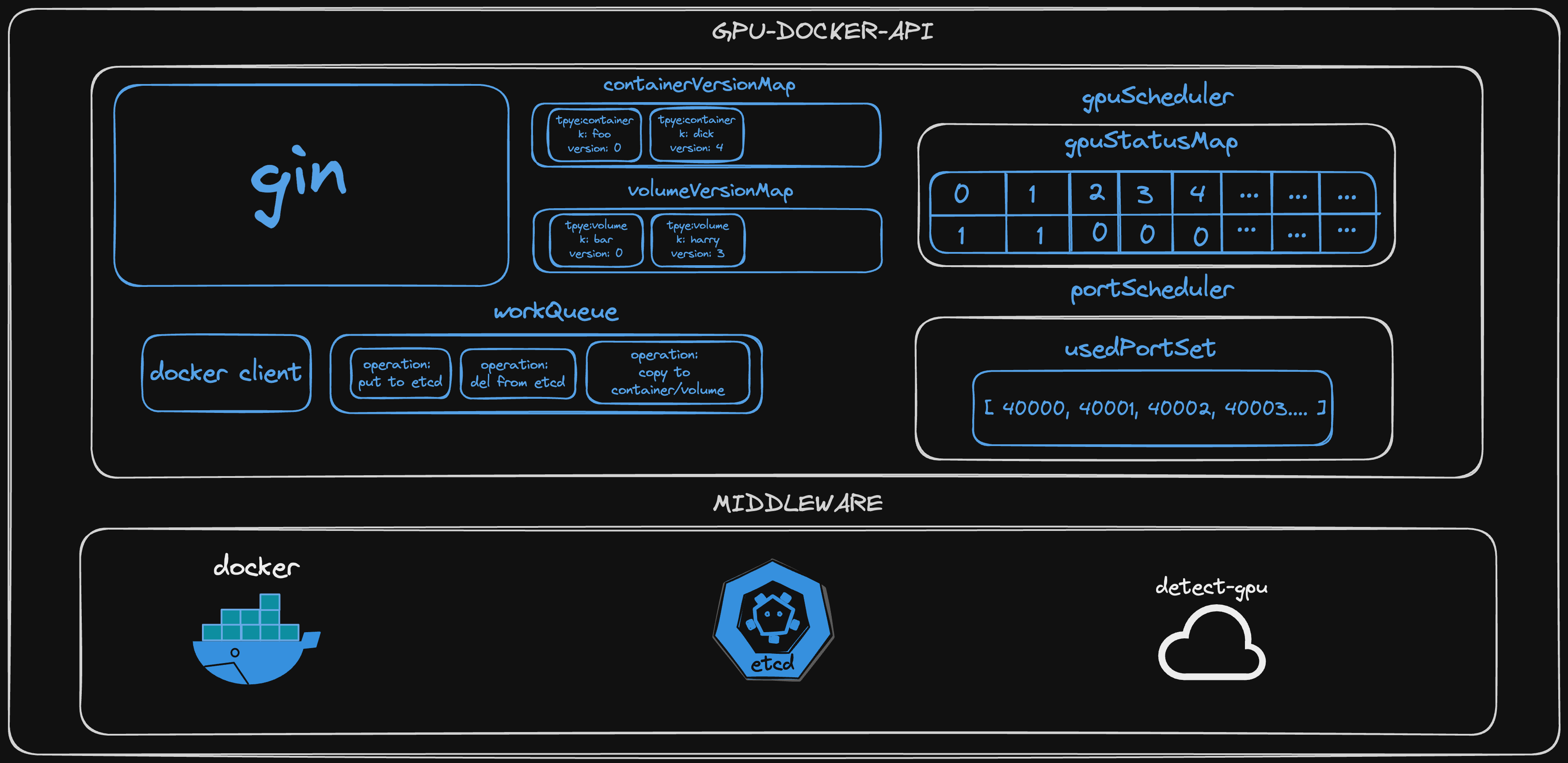
最后
笔者也是初学 Golang ,Docker ,K8s 。如果文章/代码有错误的地方,敬请斧正。
项目实现的原理具体可见:docs
 |
1
zhlxsh 2024 年 1 月 1 日 via iPhone
写的很详细,收藏了👍
|
 |
3
mayooot OP 如果项目能够帮助大家的话,欢迎点个 star !😘
|
 |
4
NeroKamin 2024 年 1 月 7 日
已 star ,学习下
|